基于量子计算的分类和聚类算法综述.docx
版权申诉
143 浏览量
2022-12-01
09:10:37
上传
评论
收藏 121KB DOCX 举报

1. 引言
近年来,越来越多的研究表明量子计算技术可以对经典算法进行显著加速.在机器学习
领域,同样可以得到类似的结论.因此,结合了量子计算和机器学习的量子机器学习领域得
到了广泛的关注,涌现出了很多量子机器学习算法
[1-3]
.一方面,研究者们希望通过量子计算
解决机器学习的运算效率问题,降低传统机器学习算法的复杂度;另一方面,探索使用量
子力学的性质,创造出可以真正运行在量子环境上的量子机器学习算法.量子计算是量子力
学与计算机科学结合的产物.量子计算机可以展现出比传统计算机强大得多的性能.随着数据
的海量增加,在当今大数据时代量子机器学习将发挥无与伦比的优势
[4-5]
.
传统机器学习主要可以分为三类:有监督学习、无监督学习和增强学习.量子计算有助
于研究有监督分类和无监督聚类问题,本文将重点关注和总结该领域的进展.例如将经典信
息转换为量子态的形式存储起来,用量子态来表示所有样本;以量子态之间的距离替代样
本数据之间的距离,形成新的相似度度量等.
2. 量子有监督分类算法
2.1 量子 K 近邻算法
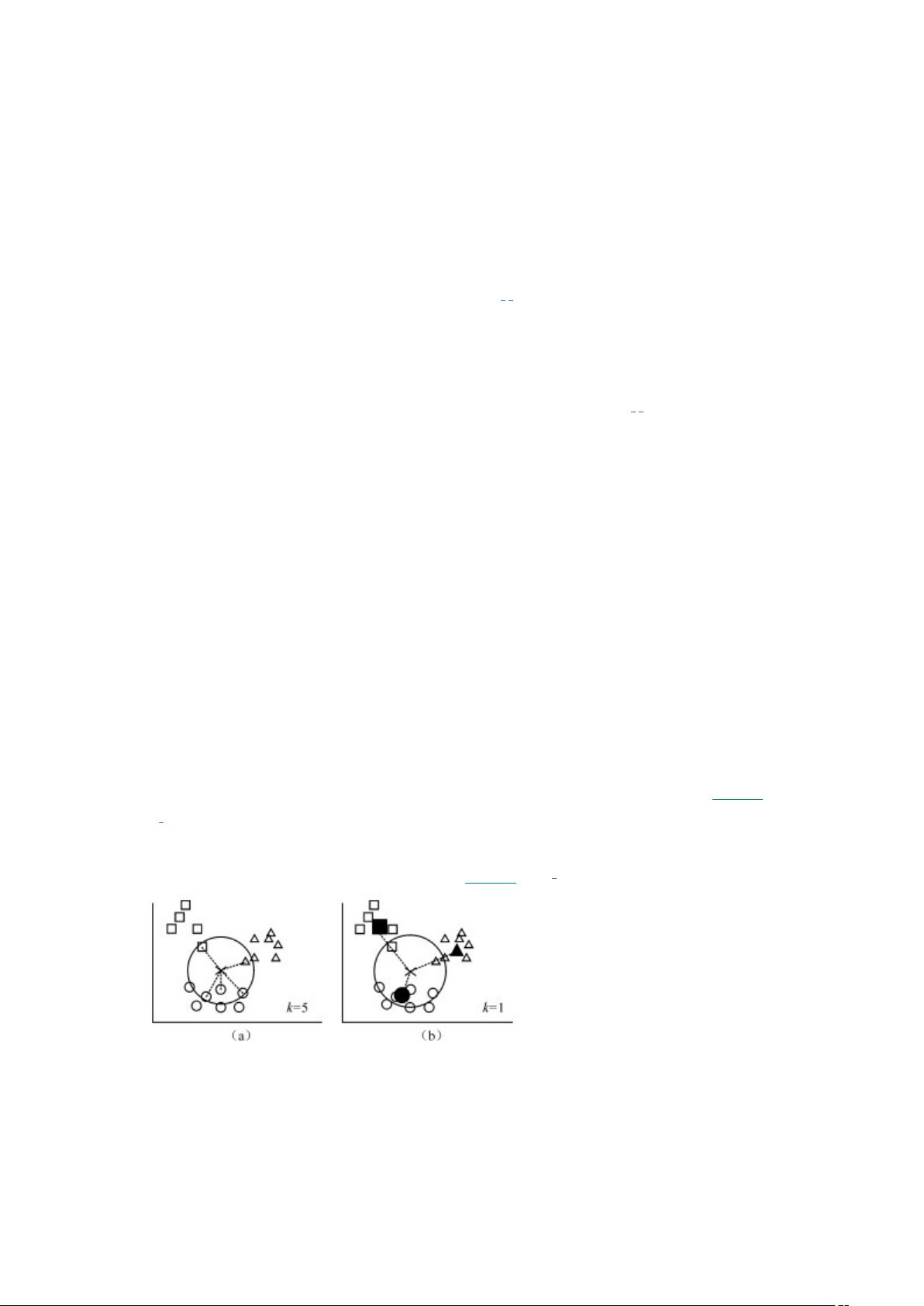
K 近邻(K-Nearest Neighbours,KNN)是一种传统有监督分类的算法,它根据待分类数
据与样本数据(也称为训练样本)之间的相似度进行分类.相似度需要根据实际问题定义,通
常是通过距离来估量相似度.它的主要思想是:一个待分类样本,在特征空间中如果与其最
近邻的 K 个样本中大多数属于某一个类别,则该待分类样本也属于这个类别,如图 1(a)所
示
[2]
.通常 K 值的选择并不容易,而且很大程度上影响分类结果.也可以计算出每个类别里的
一个平均样本,称为该类别的质心(centroid),评估待分类样本与每个质心的距离,距离最
短的那个所属类别即为待分类样本的类别,如图 1(b)所示
[2]
.
图 1 KNN 算法数据分类方式
(a) 当 k=5 时,找到与待分类样本×最近的 5 个训练样本,可知×所属于圆形类别;(b)计算
出每个类别的质心(阴影样本),可知×与圆形阴影质心的距离最短,即×所属于圆形类别.此
时可认为 k=1.
资源评论


罗伯特之技术屋
- 粉丝: 3659
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











