

大数据背景下,数据挖掘与分析成为信息处理和知识管理等相关学科领域重点关注的
研究对象
[1]
。在各种复杂数据类型中,广泛存在于金融市场和工业工程等领域的时间序列
是一种与时间密切相关的数据,根据变量属性维度的大小其可分为单变量和多变量两种时
间序列。相应地,时间序列数据挖掘是从时间序列数据库中发现信息与知识的理论与方
法,为帮助政府和企业管理者在相关领域中提供更为可靠的辅助决策与技术支持
[2]
。时间
序列的高维性具有时间维度长、属性变量多、数据体量大等特征,给传统数据挖掘技术的
实施带来了极大困扰,在一定程度上阻碍了其在时间序列数据分析领域中的应用与发展。
因此,运用数据挖掘技术从高维时间序列数据中发现信息和知识成为了数据分析领域中具
有挑战性且最主要的研究方向之一
[3]
。
传统时间序列数据分析主要基于某种数据分布假设,再选取和制定计量经济模型来对
时间序列数据预测分析。在大数据时代,除了需要传统的统计模型对时间序列数据进行预
测与分析之外,鉴于时间序列数据具有时间维度长、属性变量多和数据体量大等高维性特
征,借助机器学习、模式识别、智能计算和数据挖掘等模型和算法对高维时间序列数据可
以进行深入研究与挖掘。聚类是数据挖掘相关研究和应用中非常重要的方法,涉及计算机
科学、模式识别、人工智能和机器学习等多个研究领域,同时也常被用于教育、营销、医
学和生物信息学等学科,在大数据、人工智能和机器人等热点领域有突出贡献
[4]
。如在大
规模群体决策中,聚类分析被用于划分大规模群体、处理非合作行为和社区发现等
[5-6]
。聚
类分析也是一项重要而且基础的工作,其过程包括了时间序列的数据表达、特征提取、相
似性度量以及具体聚类模型与算法等。为此,本文对时间数据挖掘中的聚类分析进行综述
研究,首先介绍了目前时间序列聚类方法分类,然后分别从特征表示、相似性度量、聚类
算法和簇原型等方面进行国内外研究状况分析,最后分析了目前研究存在的不足,同时给
出了未来的研究方向。
1. 时间序列聚类
时间序列聚类研究大体上可分为 3 种类型
[7]
,分别为整体时间序列聚类、子序列聚类
和时间点聚类。整体时间序列聚类把每条时间序列视为数据对象,对具有共同数据特征的
时间序列对象进行聚类。它常以相似性度量为基础,结合数据降维和特征表示来找出两个
数据对象之间的共性,进而实现时间序列数据的簇划分。
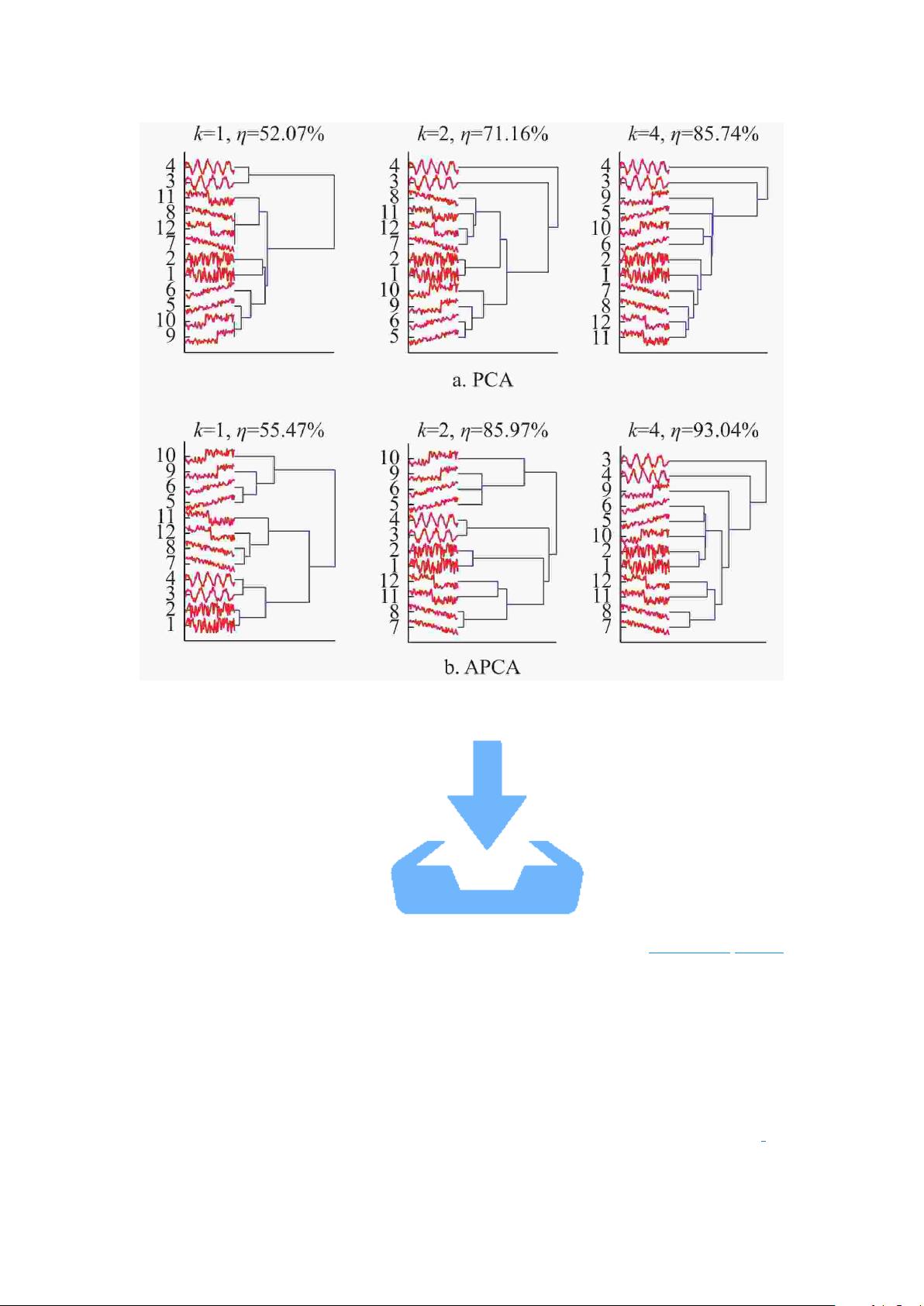
如图 1 所示,分别使用主成分分析(principal component analysis, PCA)和对称性主成分
分析(asynchronism-based principal component analysis, APCA)
[8]
对 10 条 Synthetic_Control 时
间序列数据进行特征表示,并使用相应的相似性度量方法结合层次聚类实现整体时间序列
的聚类分析。

剩余11页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 4494
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 没用333333333333333333333333333333
- 基于Vue和SpringBoot的企业员工管理系统2.0版本设计源码
- 【C++初级程序设计·配套源码】第2期-基本数据类型
- 基于Java和Vue的kopsoftKANBAN车间电子看板设计源码
- 影驰战将PS3111 东芝芯片TT18G23AIN开卡成功分享,图片里面画线的选项很重要
- 【C++初级程序设计·配套源码】第1期-语法基础
- 基于JavaScript、CSS、HTML的简易DOM版飞机游戏设计源码
- 基于Java开发的日程管理FlexTime应用设计源码
- SM2258XT-BGA144-4BGA180-6L-R1019 三星KLUCG4J1CB B0B1颗粒开盘工具 , EC, 3A, 94, 43, A4, CA 七彩虹SL300这个固件有用
- GJB 5236-2004 军用软件质量度量
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


