
回归分析
2022/6/8
#6.1
#
(
1
)
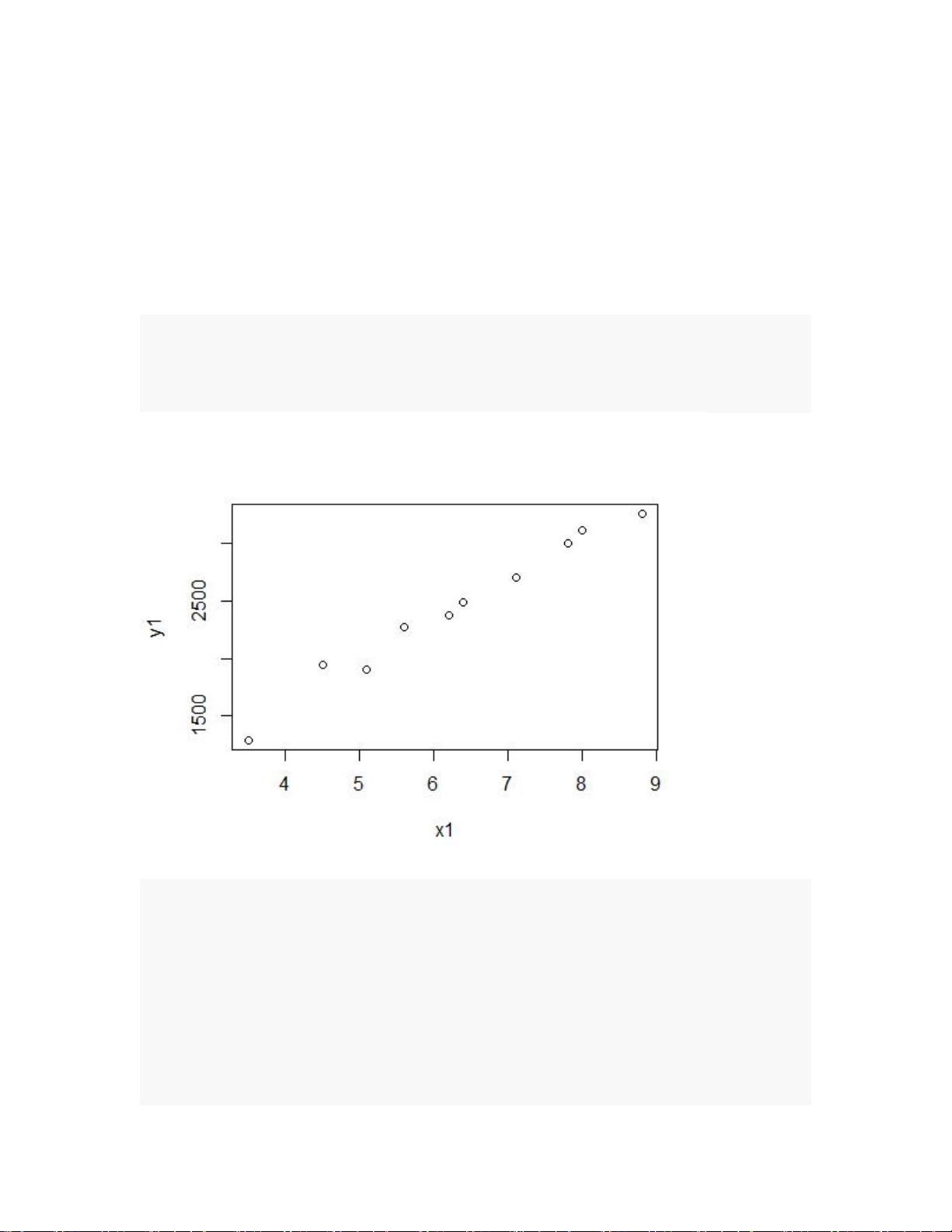
x1 <- c(5.1, 3.5, 7.1, 6.2, 8.8, 7.8, 4.5, 5.6, 8.0, 6.4)
y1 <- c(1907, 1287, 2700, 2373, 3260, 3000, 1947, 2273, 3113,2493)
plot(x1,y1)
#
由此判断,
Y
和
X
有线性关系
#
(
2
)
lm.sol <- lm(y1~x1)
#
回归方程为
Y=140.95+364.18X
#(3)
summary(lm.sol)
##
## Call:


剩余19页未读,继续阅读
资源评论


井力15
- 粉丝: 1
- 资源: 5









最新资源
- SQL语言详细教程:从基础到高级全面解析及实际应用
- 仓库管理系统源代码全套技术资料.zip
- 计算机二级考试详细试题整理及备考建议
- 全国大学生电子设计竞赛(电赛)历年试题及备考指南
- zigbee CC2530网关+4节点无线通讯实现温湿度、光敏、LED、继电器等传感节点数据的采集上传,网关通过ESP8266上传远程服务器及下发控制.zip
- 云餐厅APP项目源代码全套技术资料.zip
- vscode 翻译插件开发,选中要翻译的单词,使用快捷键Ctrl+Shift+T查看翻译
- mrdoc-alpine0.9.2
- ACMNOICSP比赛经验分享:从知识储备到团队协作的全面指南
- 云餐厅项目源代码全套技术资料.zip
- 基于STM32的数字闹钟系统的仿真和程序
- 混合信号设计中DEF文件创建流程
- 美国大学生数学建模竞赛(美赛)详细教程:从组队到赛后总结全攻略
- 病媒生物孳生地调查和治理工作方案.docx
- 保姆的工作标准.docx
- 病媒生物防制指南.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


