华泰证券-计算机行业专题研究:大模型深度复盘,科技变革加速-230522.pdf
需积分: 0 13 浏览量
2023-06-20
09:29:43
上传
评论
收藏 6.06MB PDF 举报


免责声明和披露以及分析师声明是报告的一部分,请务必一起阅读。
1
证券研究报告
计算机
大模型深度复盘,科技变革加速
华泰研究
计算机
增持 (维持)
研究员
谢春生
SAC No. S0570519080006
SFC No. BQZ938
xiechunsheng@htsc.com
+(86) 21 2987 2036
研究员
郭雅丽
SAC No. S0570515060003
SFC No. BQB164
+(86) 10 5679 3965
研究员
范昳蕊
SAC No. S0570521060004
+(86) 10 6321 1166
联系人
彭钢
SAC No. S0570121070173
+(86) 21 2897 2228
联系人
袁泽世,PhD
SAC No. S0570122080053
+(86) 21 2897 2228
联系人
林海亮
SAC No. S0570122060076
+(86) 21 2897 2228
行业走势图
资料来源:Wind,华泰研究
2023 年 5 月 22 日│中国内地
专题研究
大模型时代已来,AGI 新纪元开启
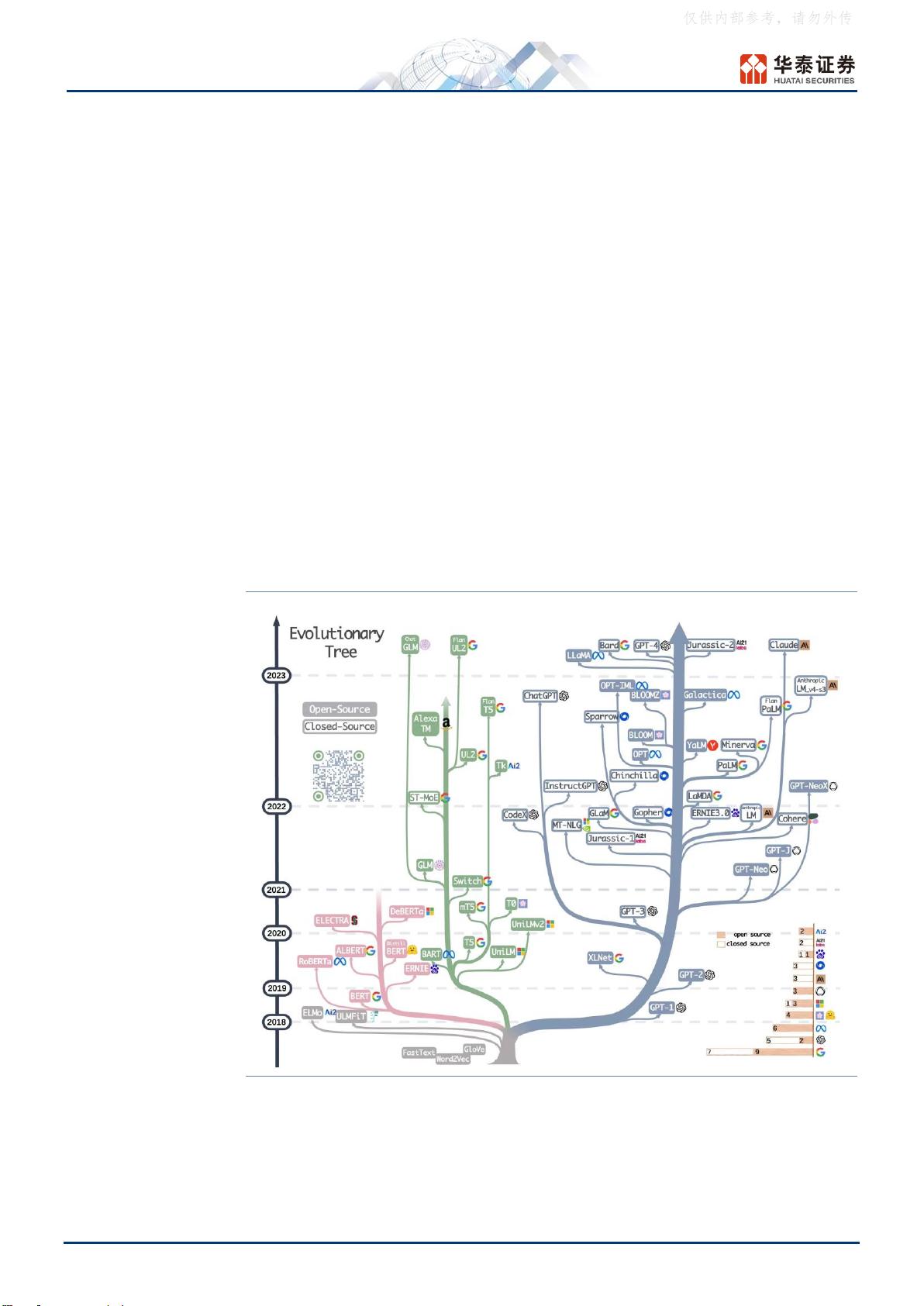
大语言模型(LLM)是在大量数据集上预训练的巨大模型,在处理各种 NLP
(自然语言处理)任务方面显示出了较大潜力。2017 年 Transformer 编解
码器架构问世后,成了今年 LLM 发展的蓝图,并由此分化出编码器、编解
码器和解码器三条进化路径。其中,编解码器和解码器架构目前仍在不断演
进中,且解码器架构在数量上占据绝对优势。全球视角看,LLM 的典型代表
是 OpenAI 开发的 GPT 系列模型,国内的百度、智源等也在大模型上进行
了深厚的积累。在大模型的赋能下,各种垂类应用和工程实现纷纷落地,包
括 BloombergGPT、AutoGPT 等。LLM 或将开启通用人工智能新纪元。
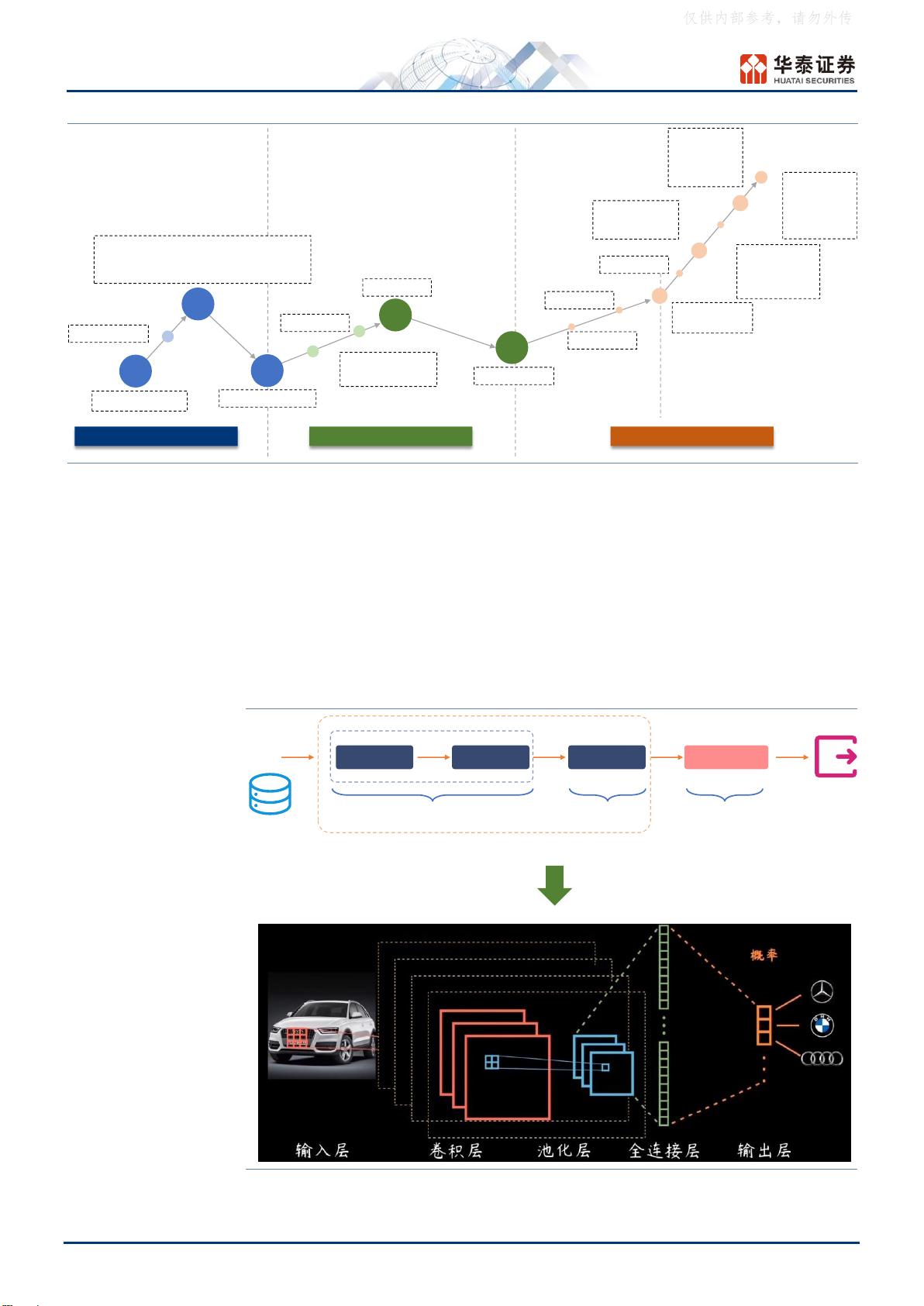
溯源:从经典神经网络到 Transformer 架构
深度学习可以概括为特征的抽象和结果的预测。深度学习与神经网络密不可
分,主要原因是神经网络模型可以使用误差反向传播算法,较好地解决了深
度学习中的贡献度分配问题。从历史发展看,神经网络诞生于 1943 年提出
的 MP 模型,深度学习概念由 Hinton 于 2006 年正式提出。经过多年的发展,
问世了如卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络
(LSTM)等经典的深度学习算法。2017 年,Transformer 架构的出现成为
了后来 LLM 的基础架构,再次开启了大语言模型快速发展时期。
发展:从 GPT-1 到 GPT-4,开启大模型新纪元
2018 年,OpenAI 提出生成式预训练模型 GPT-1,引入有监督的微调训练。
2019 年,GPT-2 以更大的参数量和多任务训练进行 zero-shot 学习;2020
年,GPT-3 用 few-shot 代替 zero-shot,并将训练参数增加到 1750 亿,再
次提高模型表现性能。2022 年,InstructGPT 引入基于人类反馈的强化学习,
实现了更符合人类预期的模型输出。2022 年 11 月,OpenAI 正式推出对话
交互式模型 ChatGPT,5 天时间突破了 100 万用户。2023 年 3 月,GPT-4
问世,支持多模态输入,并能高水准完成专业考试,支持 API。
延伸:国内大模型快速成长,海外大模型多维拓展
大模型时代到来,模型体系与生态快速扩充,海内外企业坚定发力。受益于
大模型的理解能力、推理能力、泛化能力得到充分验证,海内外企业纷纷加
速大模型相关的产业布局,全面拥抱大模型时代的技术变革。1)国内:国
内大模型发展起步相对较晚,ChatGPT 问世以来国内企业加速大模型研发,
2023 年以百度文心、商汤日日新、讯飞星火等为代表的国产大模型相继发
布,并持续推进模型迭代升级;2)海外:海外大模型发展呈现垂直落地、
工程实现、模态丰富三大发展趋势,模型体系与配套的工程生态日益丰富。
产业链相关公司梳理
以 GPT 为代表的大模型产业链可分为算力、模型、应用三个环节。1)算力:
包括寒武纪、景嘉微、海光信息等芯片厂商以及浪潮信息、中科曙光、工业
富联等服务器厂商;2)模型:包括百度、三六零、科大讯飞、昆仑万维、
商汤科技等科技企业;3)应用:2C 简单包括金山办公、科大讯飞、同花顺、
万兴科技、东方财富、汉仪股份、汉王科技、萤石网络等企业;2B 简单包
括泛微网络、致远互联、上海钢联、彩讯股份等企业;2C 复杂包括中望软
件、索辰科技、广联达等企业;2B 复杂包括恒生电子、石基信息、科大讯
飞、汉王科技、金桥信息等企业。
风险提示:宏观经济波动;大模型技术迭代不及预期;本报告内容基于客观
资料整理,不构成投资建议。
(14)
6
26
46
66
May-22 Sep-22 Jan-23 May-23
(%)
计算机 沪深300
仅供内部参考,请勿外传

剩余38页未读,继续阅读
资源评论













