(项目案例)天猫品牌推荐.docx
需积分: 10 45 浏览量
2021-03-19
11:19:35
上传
评论
收藏 925KB DOCX 举报


本项目是基于阿里巴巴天猫电商平台真实脱敏数据的数据分析推荐项目,主要用于
《大数据分析项目实践》课程 ,占用课时 课时,项目中部分模块还应用在《机器学
习》和《 云端开发》课程中。
项目背景:
在天猫,每天会有数千万的用户通过品牌发现自己喜欢的商品,品牌推荐是连接商家
和消费者的最重要的纽带,此外,品牌推荐在大促销活动中更是举足轻重,以 年双
为例,如果大家在双 上买过东西,应该会有印象,无论是在 上还是无限上,会
场的组织形式通常是品牌,而不是单品,因为品牌可以承载更多的信息。通过品牌组织,
实现个性化会场,改变原来千人一面的风格,做到千人千面。帮助消费者从众多品牌中快
速找到自己喜欢的,因此,品牌推荐具有非常切实的业务意义。
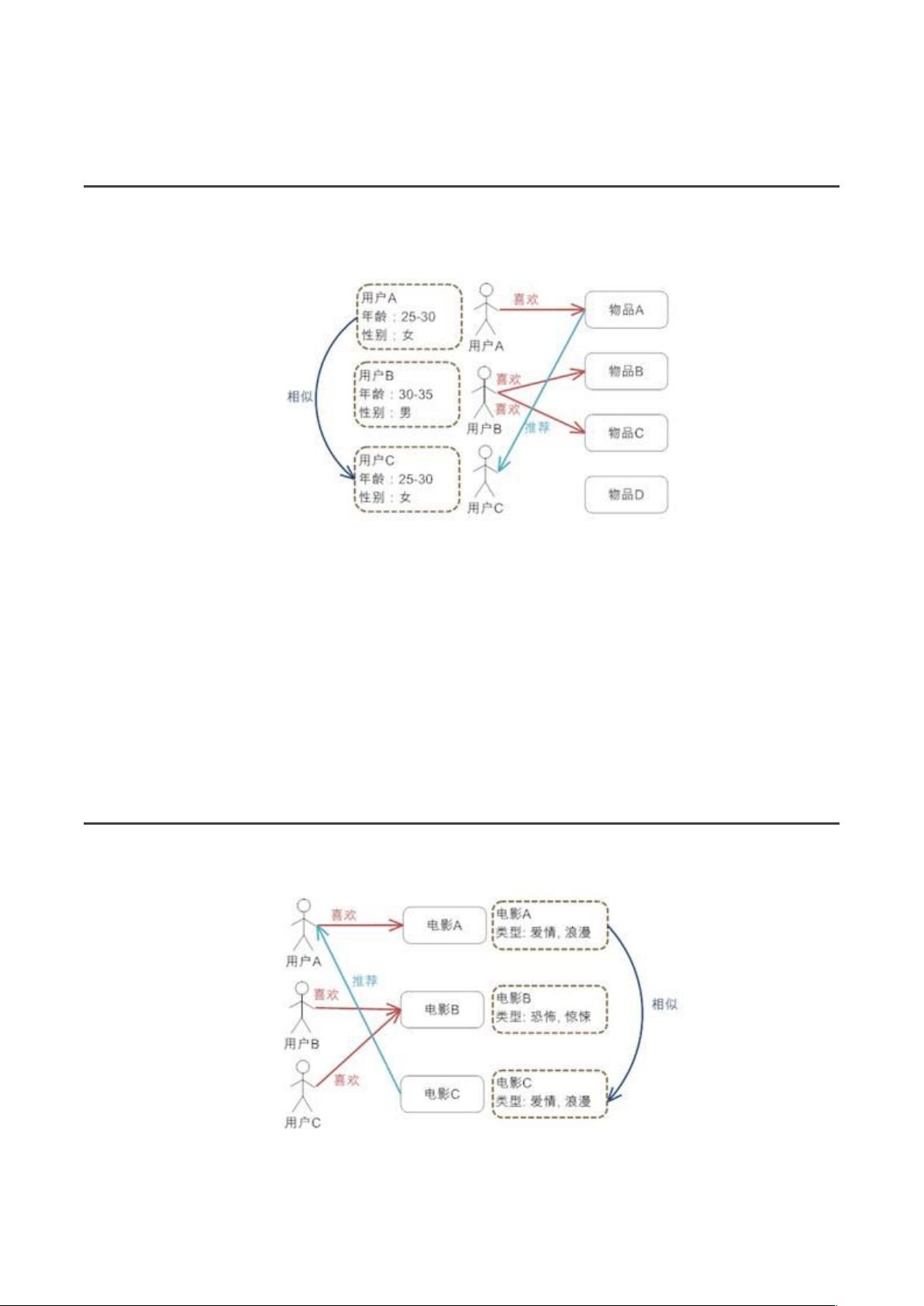
什么是推荐系统
利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模
拟销售人员帮助客户完成购买过程。
为什么要有推荐系统
随着电子商务规模的不断扩大,商品个数和种类快速增长,顾客需要花费大量的时间才能
找到自己想买的商品。这种浏览大量无关的信息和产品过程无疑会使淹没在信息过载问题
中的消费者不断流失。
为了解决这些问题,个性化推荐系统应运而生。个性化推荐系统是建立在海量数据挖掘基
础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策
支持和信息服务。
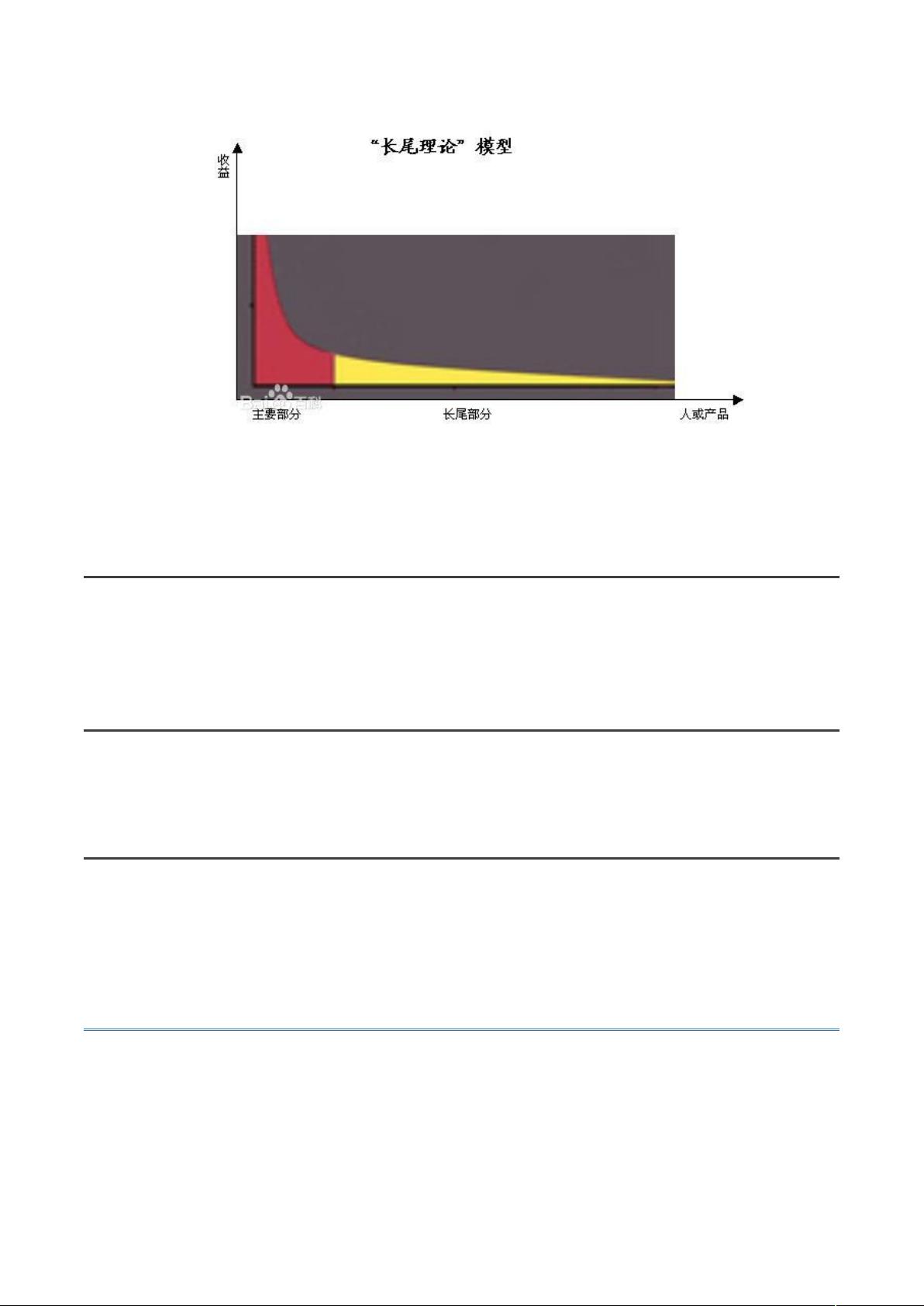
目的 1:帮助用户找到想要的商品
帮用户找到想要的东西,谈何容易。商品茫茫多,甚至是我们自己,也经常点开淘宝,
面对眼花缭乱的打折活动不知道要买啥。在经济学中,有一个著名理论叫长尾理论(
)。


剩余38页未读,继续阅读
资源评论


E_N_D123
- 粉丝: 4
- 资源: 7











