
1 Introduction
Language modeling has long been an important research area since Shannon (1951) estimated the information in
language with next word prediction. Modeling began with
n
-gram based approaches (Kneser & Ney, 1995) but rapidly
advanced with LSTMs (Hochreiter & Schmidhuber, 1997; Graves, 2014). Later work showed that language modelling
also led to language understanding (Dai & Le, 2015). With increased scale and the Transformer architecture (Vaswani
et al., 2017), large language models (LLMs) have shown strong performance in language understanding and generation
capabilities over the last few years, leading to breakthrough performance in reasoning, math, science, and language tasks
(Howard & Ruder, 2018; Brown et al., 2020; Du et al., 2022; Chowdhery et al., 2022; Rae et al., 2021; Lewkowycz
et al., 2022; Tay et al., 2023; OpenAI, 2023b). Key factors in these advances have been scaling up model size (Brown
et al., 2020; Rae et al., 2021) and the amount of data (Hoffmann et al., 2022). To date, most LLMs follow a standard
recipe of mostly monolingual corpora with a language modeling objective.
We introduce PaLM 2, the successor to PaLM (Chowdhery et al., 2022), a language model unifying modeling advances,
data improvements, and scaling insights. PaLM 2 incorporates the following diverse set of research advances:
• Compute-optimal scaling
: Recently, compute-optimal scaling (Hoffmann et al., 2022) showed that data size is
at least as important as model size. We validate this study for larger amounts of compute and similarly find that
data and model size should be scaled roughly 1:1 to achieve the best performance for a given amount of training
compute (as opposed to past trends, which scaled the model 3× faster than the dataset).
• Improved dataset mixtures
: Previous large pre-trained language models typically used a dataset dominated
by English text (e.g.,
∼
78% of non-code in Chowdhery et al. (2022)). We designed a more multilingual and
diverse pre-training mixture, which extends across hundreds of languages and domains (e.g., programming
languages, mathematics, and parallel multilingual documents). We show that larger models can handle more
disparate non-English datasets without causing a drop in English language understanding performance, and apply
deduplication to reduce memorization (Lee et al., 2021)
• Architectural and objective improvements
: Our model architecture is based on the Transformer. Past LLMs
have almost exclusively used a single causal or masked language modeling objective. Given the strong results of
UL2 (Tay et al., 2023), we use a tuned mixture of different pre-training objectives in this model to train the model
to understand different aspects of language.
The largest model in the PaLM 2 family, PaLM 2-L, is significantly smaller than the largest PaLM model but uses
more training compute. Our evaluation results show that PaLM 2 models significantly outperform PaLM on a variety
of tasks, including natural language generation, translation, and reasoning. These results suggest that model scaling
is not the only way to improve performance. Instead, performance can be unlocked by meticulous data selection
and efficient architecture/objectives. Moreover, a smaller but higher quality model significantly improves inference
efficiency, reduces serving cost, and enables the model’s downstream application for more applications and users.
PaLM 2 demonstrates significant multilingual language, code generation and reasoning abilities, which we illustrate in
Figures 2 and 3. More examples can be found in Appendix B.
1
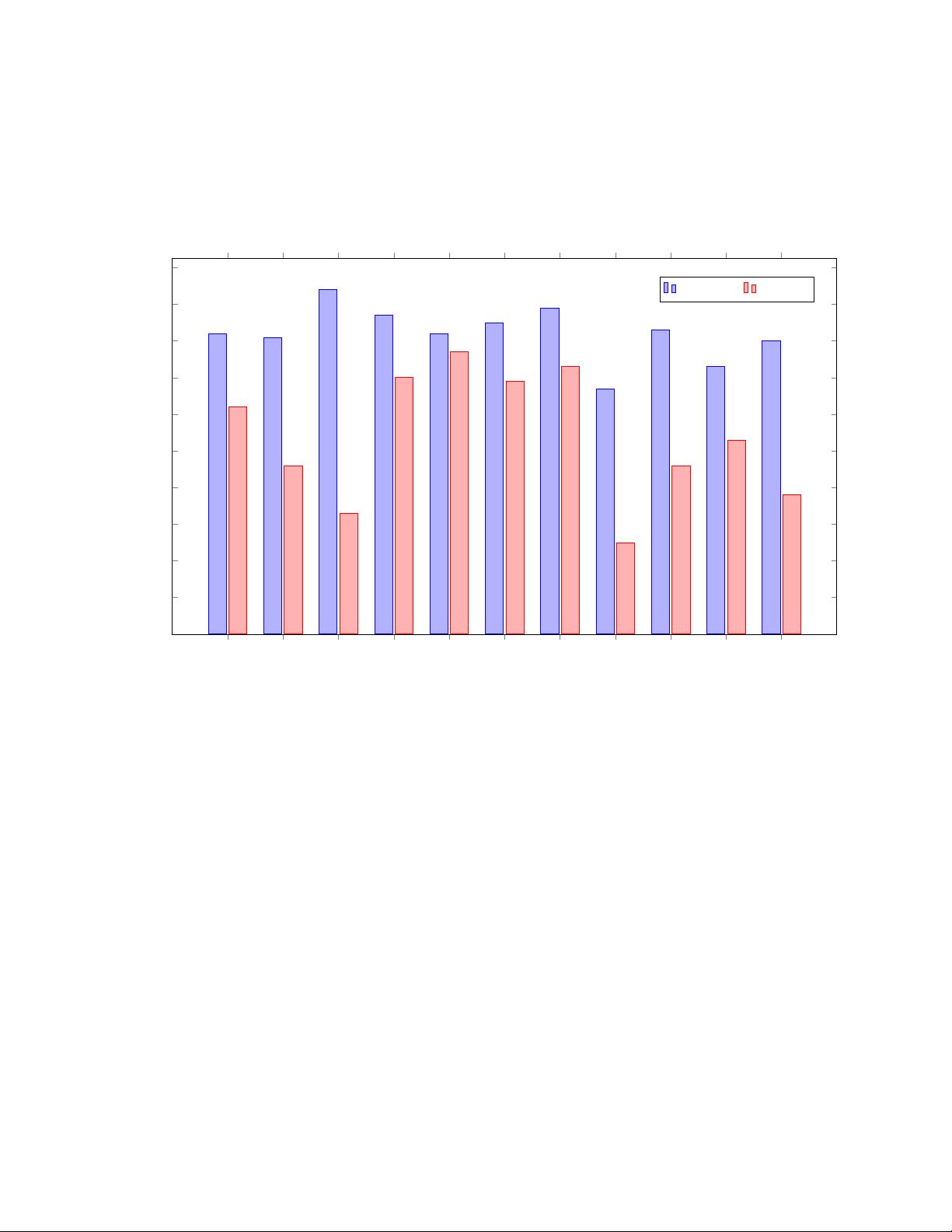
PaLM 2 performs significantly better than PaLM on
real-world advanced language proficiency exams and passes exams in all evaluated languages (see Figure 1). For some
exams, this is a level of language proficiency sufficient to teach that language. In this report, generated samples and
measured metrics are from the model itself without any external augmentations such as Google Search or Translate.
PaLM 2 includes control tokens to enable inference-time control over toxicity, modifying only a fraction of pre-training
as compared to prior work (Korbak et al., 2023). Special ‘canary’ token sequences were injected into PaLM 2 pre-
training data to enable improved measures of memorization across languages (Carlini et al., 2019, 2021). We find
that PaLM 2 has lower average rates of verbatim memorization than PaLM, and for tail languages we observe that
memorization rates increase above English only when data is repeated several times across documents. We show that
PaLM 2 has improved multilingual toxicity classification capabilities, and evaluate potential harms and biases across a
range of potential downstream uses. We also include an analysis of the representation of people in pre-training data.
These sections help downstream developers assess potential harms in their specific application contexts (Shelby et al.,
2023), so that they can prioritize additional procedural and technical safeguards earlier in development. The rest of this
report focuses on describing the considerations that went into designing PaLM 2 and evaluating its capabilities.
1
Note that not all capabilities of PaLM 2 are currently exposed via PaLM 2 APIs.
3

















- 1
- 2
前往页