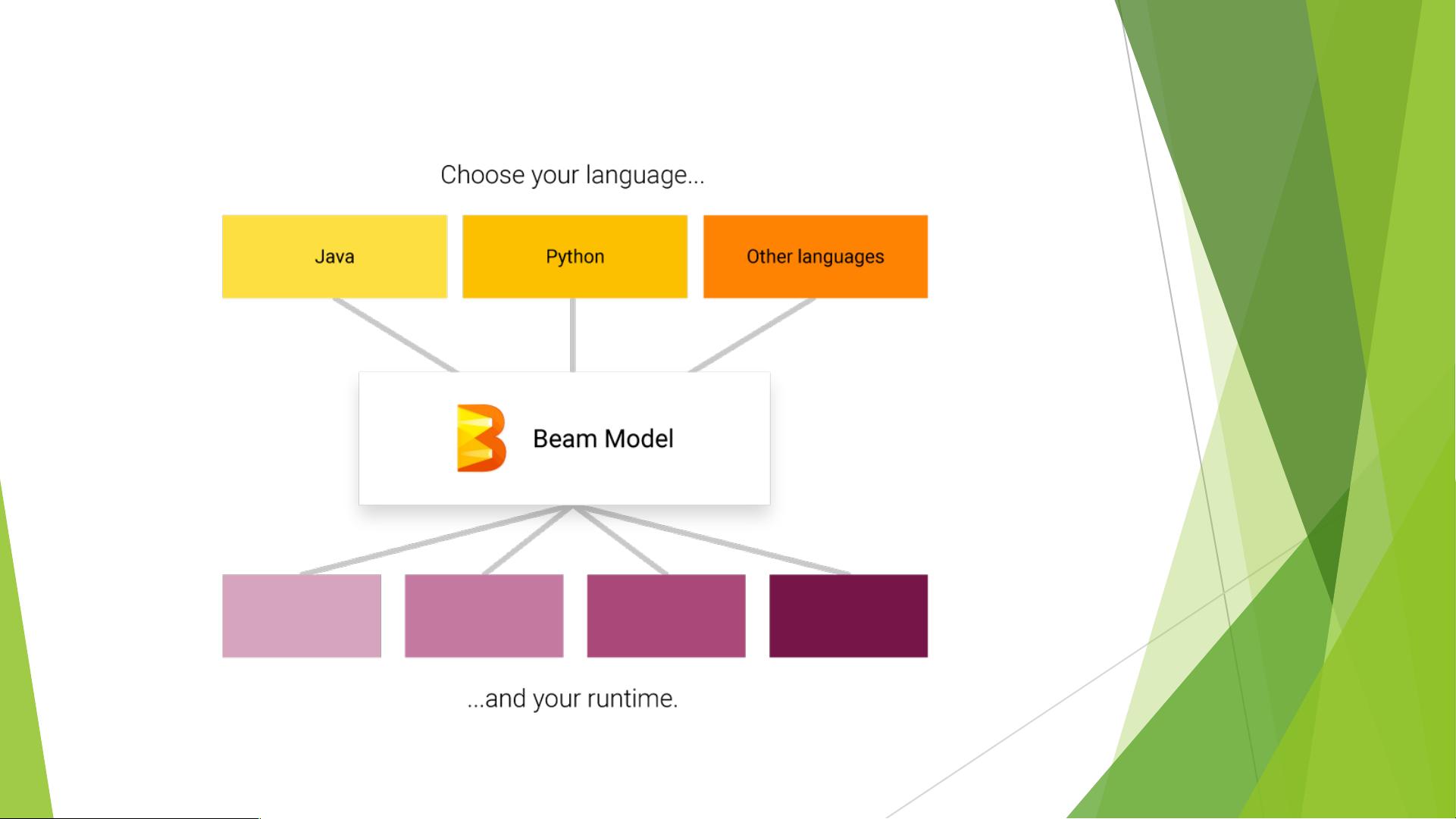
Apache Beam
u A unified model for batch and streaming applications.
u Runners for famous open-source batch and streaming engines, for instance
Spark and Flink.
u Multi-languages are available for end users to build their own pipelines, now
Java and Python are supported.
u Implement once, run almost everywhere.