

Assimilating Cleaning Operations with Flash-Level Parallelism for NAND
Flash-Based Devices
Ronghui Wang
∗†
, Zhiguang Chen
∗
, Nong Xiao
∗
, Minxuan Zhang
∗
, Weihua Dong
†
∗
College of Computer, National University of Defense Technology, Changsha, 410073, China
†
State Key Laboratory of Astronautic Dynamics, Xi’an, 710043, China
Email: {ronghuiw, chenzhiguanghit}@gmail.com, {nongxiao,mxzhang}@nudt.edu.cn, {ttinywolf}@gmail.com
Abstract—Flash-based devices internally provide multilevel
parallelism, and parallelizing flash operations is the key to im-
proving performance. Most of existing research works dispatch
and schedule host requests so that the obtained sub-requests
can be served in parallel, however, these works seldom paral-
lelize the extra operations introduced by the internal garbage
collection (GC) process. The costly operation sequence of GC
is the main reason for I/O blocking, especially when the device
is close to be full. In this paper, we propose a novel Subdivided
Garbage Collector (SGC), which exploits both the system-level
and the flash-level parallelism to parallelize garbage-collecting
operations as well as garbage-collecting activities. SGC confines
the GC process inside a flash chip, utilizing the system-level
parallelism to overlapping garbage-collecting activities with
I/O services among different chips. The flash-level parallelism
is further exploited with a novel queue mechanism, which
schedules and packs the reordered partial steps of cleaning
sequence into parallel operations. To make more parallelization
possible, a dynamic conflict-aware address allocator is proposed
to eliminate the host writes and cleaning operations from
contending for the critical components of the device. Trace-
driven simulations demonstrate that the proposals can hide
overheads of GC, resulting in a shorter response time.
Keywords-flash-based devices, garbage collection (GC), ad-
dress allocation, parallelism, scheduling
I. INTRODUCTION
Flash-based devices have the benefits of high random
I/O performance, high robustness, low power consumption,
light weight, and small form-factor, so that they are now
crucial components in embedded devices and smart phones.
Likewise, large-capacity flash-based devices are replacing
hard disk drives (HDDs) in laptop computers, high-end
enterprise-scale storage systems and high-performance com-
puting (HPC) environments. However, NAND flash memory
has some idiosyncrasies such as erase-before-write and bulk
erase. Therefore, the flash-based devices mentioned above
introduce a firmware named as the flash translation layer
(FTL) to manage the flash address space. The FTL uses an
address mapping mechanism to support out-of-place update
and employs an internal garbage collection (GC) process to
recycle obsolete data to provide free spaces. The GC process
brings extra operations: it needs to move the valid pages out
of the victim block before erasing the block. Overheads of
this cleaning sequence are relatively high, which may cause
I/O blocking and performance degradation, especially when
the device is close to be full.
Flash-based devices employ multiple flash chips over
multiple channels, providing the system-level parallelism at
the channel and the chip levels. Furthermore, inside a flash
chip, manufactories provide advanced commands which can
be used to exploit the flash-level parallelism at the die and
the plane levels, though the use of advanced commands must
adhere to some strict restrictions. Existing works mainly
focus on parallelizing host requests to improve the device
performance, but they do not consider the parallelism among
garbage-collecting operations. Chang et al. [1] have found
that under realistic disk workloads, nearly the same amount
of time is spent on collecting garbage as well as writing
host data. Therefore, the garbage-collecting activities and
operations have a significant negative impact on host IO
performance.
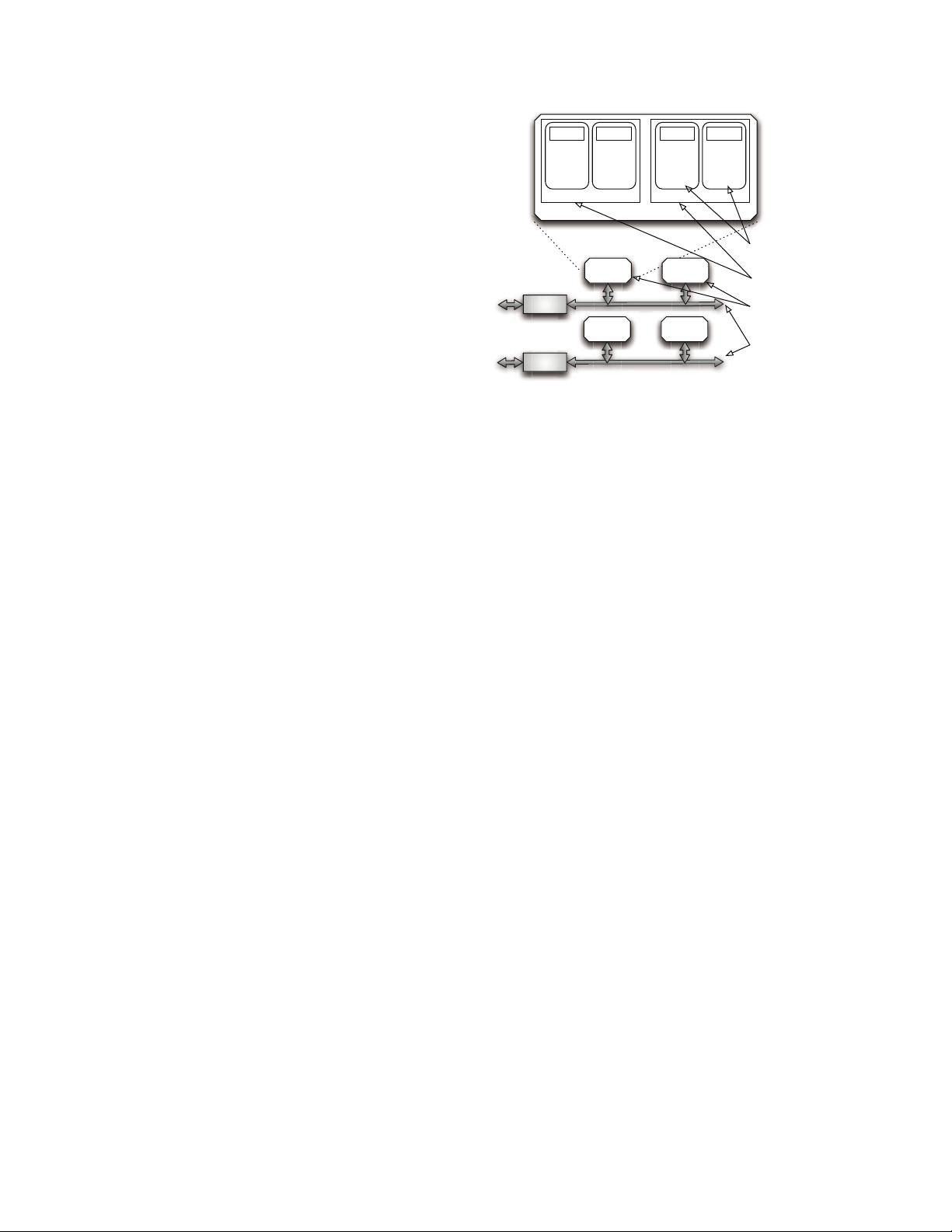
Motivated by parallelizing garbage-collecting operations
as well as garbage-collecting activities, this work exploits
both the system-level and the flash-level parallelism to as-
similate the cleaning operations into I/O services. The novel
scheme includes a Subdivided Garbage Collector (SGC),
a queue mechanism and a dynamic conflict-aware address
allocator. Our garbage collector confines the GC inside a
flash chip, which makes use of the system-level parallelism
for garbage-collecting activities since different chips can
take different tasks. For the cleaning chip, the pages to
be migrated are read out of the victim block first, during
which host reads to the chip can be served indeed in higher
priority, while no host write is assigned to the chip by
our dynamic allocator. The block can be erased after all
valid pages have been read out, and after the erasure the
allocator can assign the chip to host writes again. Therefore,
the idling of host requests waiting for cleaning sequence is
reduced since host writes are dispatched elsewhere and host
reads are scheduled as soon as possible. In addition, we
2014 IEEE International Conference on Computer and Information Technology
978-1-4799-6239-6/14 $31.00 © 2014 IEEE
DOI 10.1109/CIT.2014.68
212
剩余7页未读,继续阅读
资源评论


weixin_38741996
- 粉丝: 45
- 资源: 932









最新资源
- 创建一个Flutter todolist应用
- 2025年销售工作计划.docx
- 厦门大学大数据团队详述:大模型技术及其在多领域的应用与展望
- script2.ipynb
- TEMU官方API文档资源包(2025/03/10)
- 公司人事管理信息系统小程序
- js微信小程序花麻将胡牌分数计算器源码!
- 管家婆辉煌ERP H3 13.11.zip
- 管家婆辉煌ERP H5 V1311.zip
- 管家婆辉煌ERP V13.02.zip
- 水火箭————————————————————————
- elastcsearch-7.10.2 docker镜像压缩包
- 教育管理教研组全维发展蓝图:全景学术成长体系优化与命名策略设计 这篇文章详细分析并优化了原有的“全景学术成长体系”名称,旨在创建一个更具吸引力且准确反
- 姓名+新员工花名册.xlsx
- 5G接入网架构基础及其相关部署方法
- kernel-uek-3.8.13-44.1.1.el6uek.x86_64.rpm
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


