

Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Short Papers), pages 725–731
Melbourne, Australia, July 15 - 20, 2018.
c
2018 Association for Computational Linguistics
725
Autoencoder as Assistant Supervisor: Improving Text Representation for
Chinese Social Media Text Summarization
Shuming Ma
1
, Xu Sun
1,2
, Junyang Lin
3
, Houfeng Wang
1
1
MOE Key Lab of Computational Linguistics, School of EECS, Peking University
2
Deep Learning Lab, Beijing Institute of Big Data Research, Peking University
3
School of Foreign Languages, Peking University
{shumingma, xusun, linjunyang, wanghf}@pku.edu.cn
Abstract
Most of the current abstractive text sum-
marization models are based on the
sequence-to-sequence model (Seq2Seq).
The source content of social media is long
and noisy, so it is difficult for Seq2Seq to
learn an accurate semantic representation.
Compared with the source content, the an-
notated summary is short and well writ-
ten. Moreover, it shares the same mean-
ing as the source content. In this work,
we supervise the learning of the represen-
tation of the source content with that of the
summary. In implementation, we regard a
summary autoencoder as an assistant su-
pervisor of Seq2Seq. Following previous
work, we evaluate our model on a popular
Chinese social media dataset. Experimen-
tal results show that our model achieves
the state-of-the-art performances on the
benchmark dataset.
1
1 Introduction
Text summarization is to produce a brief summary
of the main ideas of the text. Unlike extractive text
summarization (Radev et al., 2004; Woodsend and
Lapata, 2010; Cheng and Lapata, 2016), which se-
lects words or word phrases from the source texts
as the summary, abstractive text summarization
learns a semantic representation to generate more
human-like summaries. Recently, most models for
abstractive text summarization are based on the
sequence-to-sequence model, which encodes the
source texts into the semantic representation with
an encoder, and generates the summaries from the
representation with a decoder.
1
The code is available at https://github.com/
lancopku/superAE
The contents on the social media are long, and
contain many errors, which come from spelling
mistakes, informal expressions, and grammatical
mistakes (Baldwin et al., 2013). Large amount of
errors in the contents cause great difficulties for
text summarization. As for RNN-based Seq2Seq,
it is difficult to compress a long sequence into an
accurate representation (Li et al., 2015), because
of the gradient vanishing and exploding problem.
Compared with the source content, it is easier
to encode the representations of the summaries,
which are short and manually selected. Since the
source content and the summary share the same
points, it is possible to supervise the learning of
the semantic representation of the source content
with that of the summary.
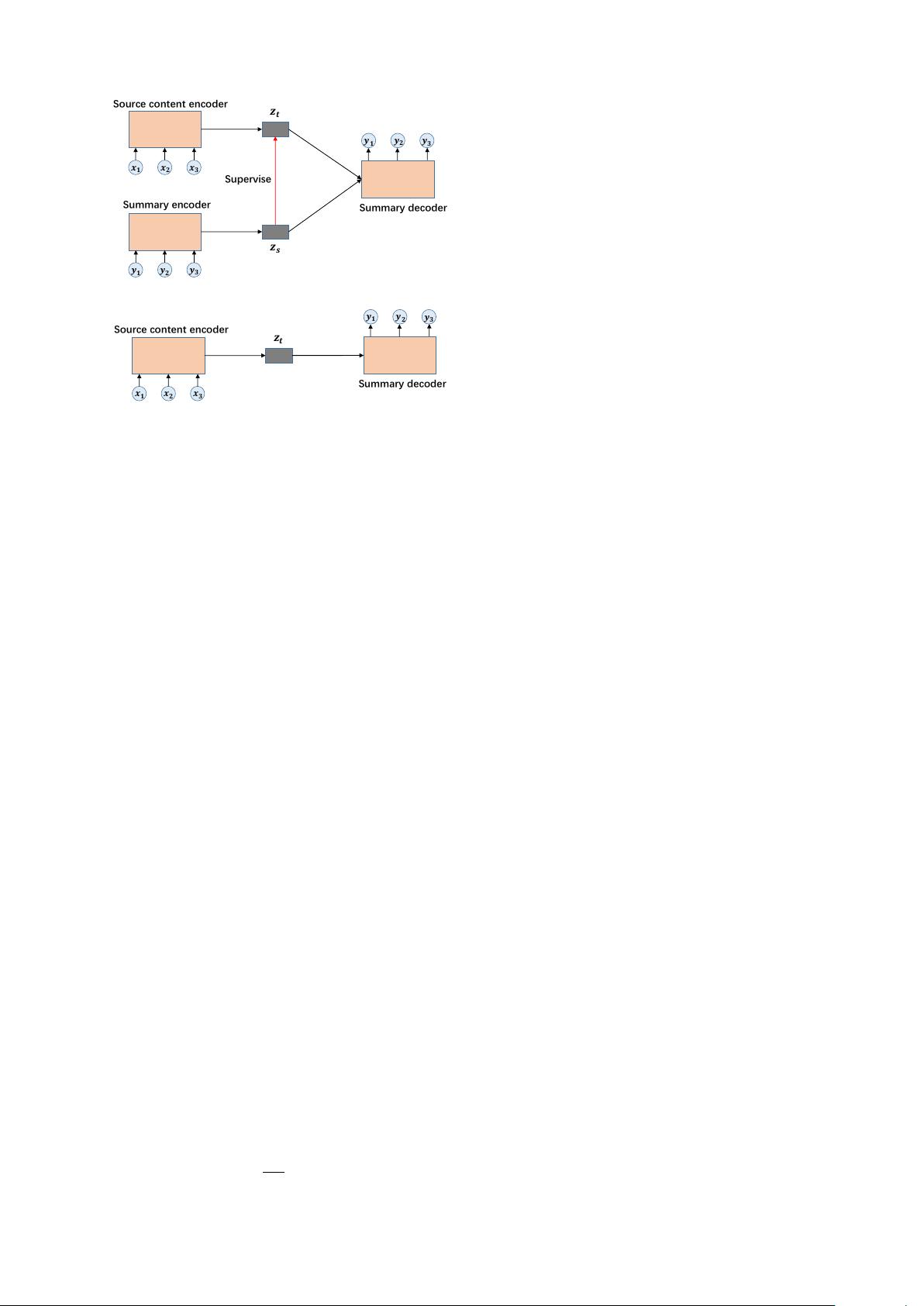
In this paper, we regard a summary autoen-
coder as an assistant supervisor of Seq2Seq. First,
we train an autoencoder, which inputs and recon-
structs the summaries, to obtain a better repre-
sentation to generate the summaries. Then, we
supervise the internal representation of Seq2Seq
with that of autoencoder by minimizing the dis-
tance between two representations. Finally, we
use adversarial learning to enhance the supervi-
sion. Following the previous work (Ma et al.,
2017), We evaluate our proposed model on a Chi-
nese social media dataset. Experimental results
show that our model outperforms the state-of-the-
art baseline models. More specifically, our model
outperforms the Seq2Seq baseline by the score of
7.1 ROUGE-1, 6.1 ROUGE-2, and 7.0 ROUGE-L.
2 Proposed Model
We introduce our proposed model in detail in this
section.
2.1 Notation
Given a summarization dataset that consists of N
data samples, the i
th
data sample (x
i
, y
i
) con-
剩余6页未读,继续阅读
资源评论













