
利用利用Python进行数据分析进行数据分析——基础示例基础示例
1.USA.gov Data from Bitly
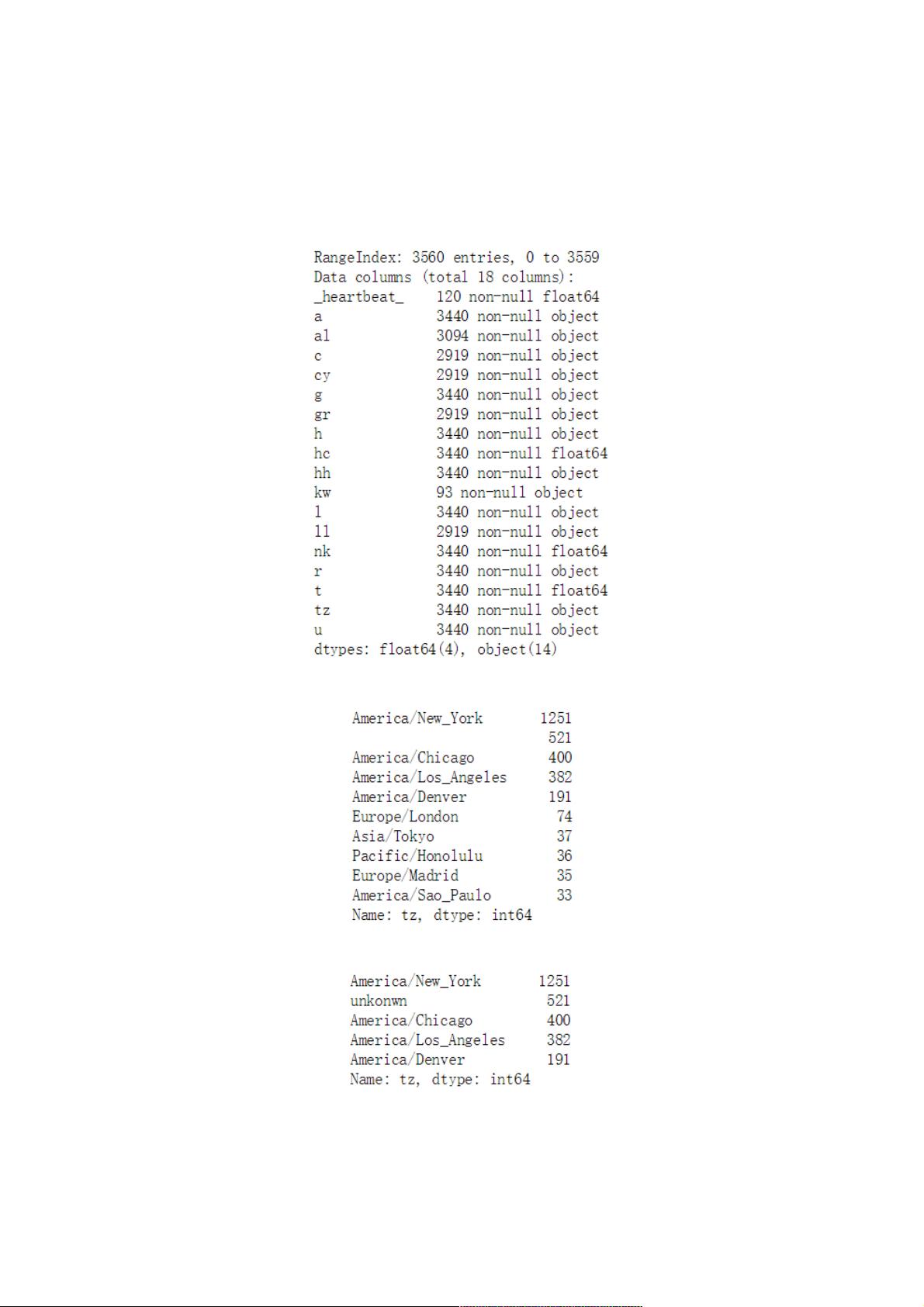
此数据是美国官方网站从用户那搜集到的匿名数据。
tz字段包含的是时区信息。
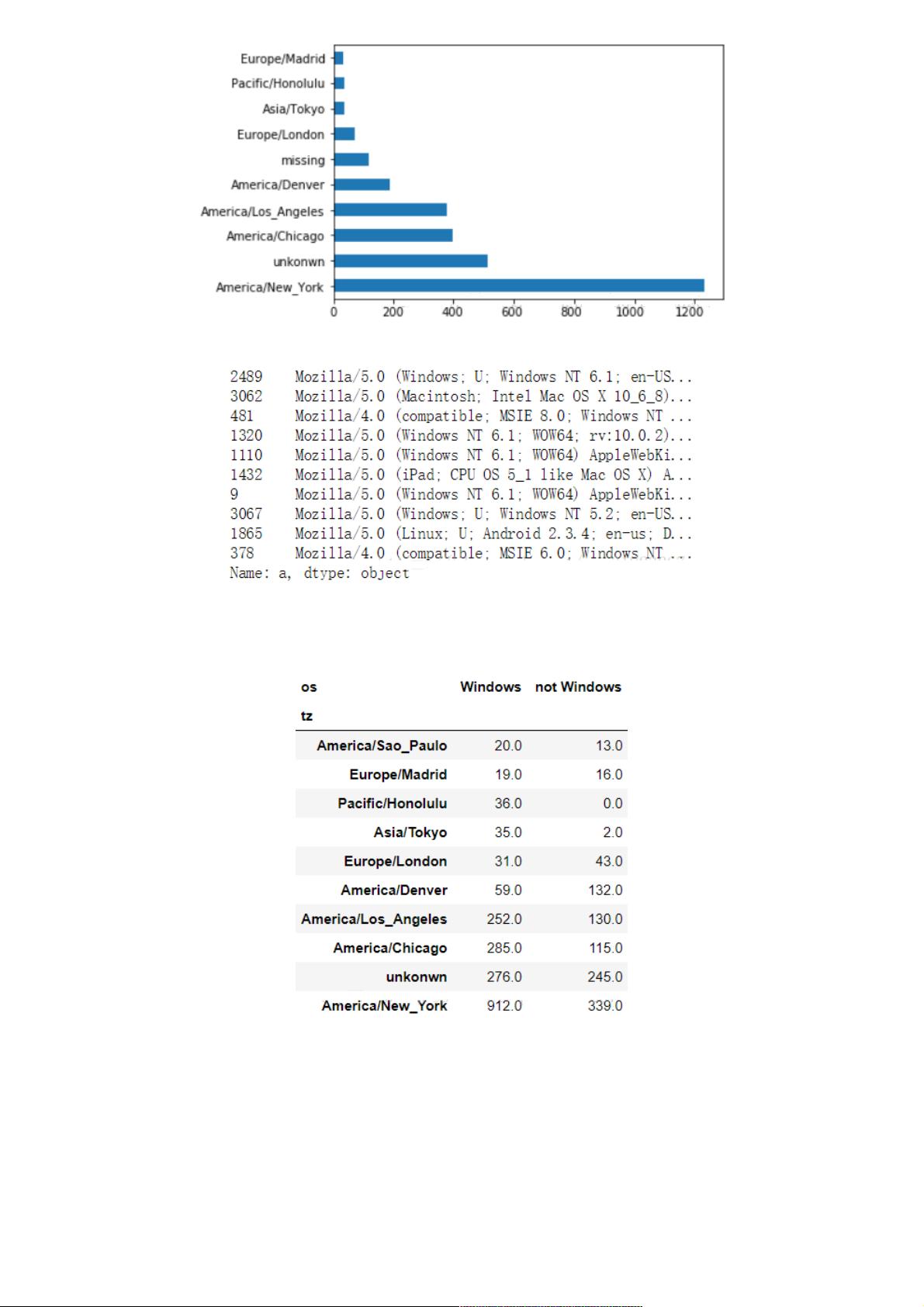
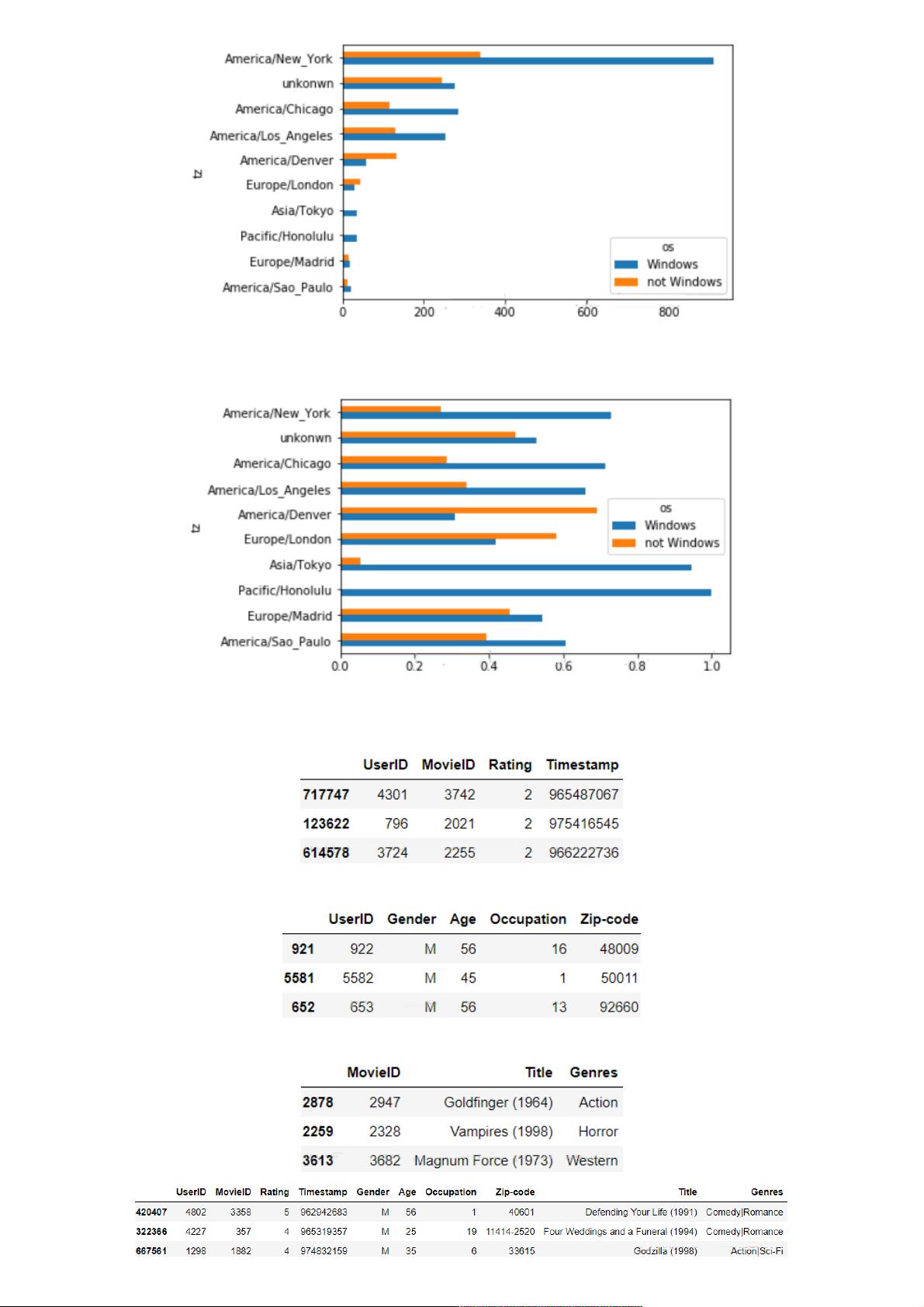
根据info()与value_counts()的返回结果来看,tz列存在缺失值与空值,首先填充缺失值,然后处理空值:
剩余13页未读,继续阅读

weixin_38688890
- 粉丝: 6
- 资源: 964









最新资源
- fish-kong,Yolov5-Instance-Seg-Tensorrt-CPP.zip
- 排球场地的排球识别 yolov7标记
- 微信小程序毕业设计-基于SSM的英语学习激励系统【代码+论文+PPT】.zip
- DOTA 中的 YOLOX 损失了 KLD (定向物体检测)(Rotated BBox)基于YOLOX的旋转目标检测.zip
- caffe-yolo-9000.zip
- 11sadsadfasfsafasf
- Android 凭证交换和更新协议 - “你只需登录一次”.zip
- 2024 年 ICONIP 展会.zip
- 微信小程序毕业设计-基于SSM的电影交流小程序【代码+论文+PPT】.zip
- 微信小程序毕业设计-基于SSM的食堂线上预约点餐小程序【代码+论文+PPT】.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



- 1
- 2
前往页