

HotSnap: A Hot Distributed Snapshot System for Virtual Machine Cluster
Lei Cui, Bo Li, Yangyang Zhang, Jianxin Li
Beihang University, Beijing, China
{cuilei, libo, zhangyy, lijx}@act.buaa.edu.cn
Abstract
The management of virtual machine cluster (VMC) is
challenging owing to the reliability requirements, such
as non-stop service, failure tolerance, etc. Distributed s-
napshot of VMC is one promising approach to support
system reliability, it allows the system administrators of
data centers to recover the system from failure, and re-
sume the execution from a intermediate state rather than
the initial state. However, due to the heavyweight na-
ture of virtual machine (VM) technology, application-
s running in the VMC suffer from long downtime and
performance degradation during snapshot. Besides, the
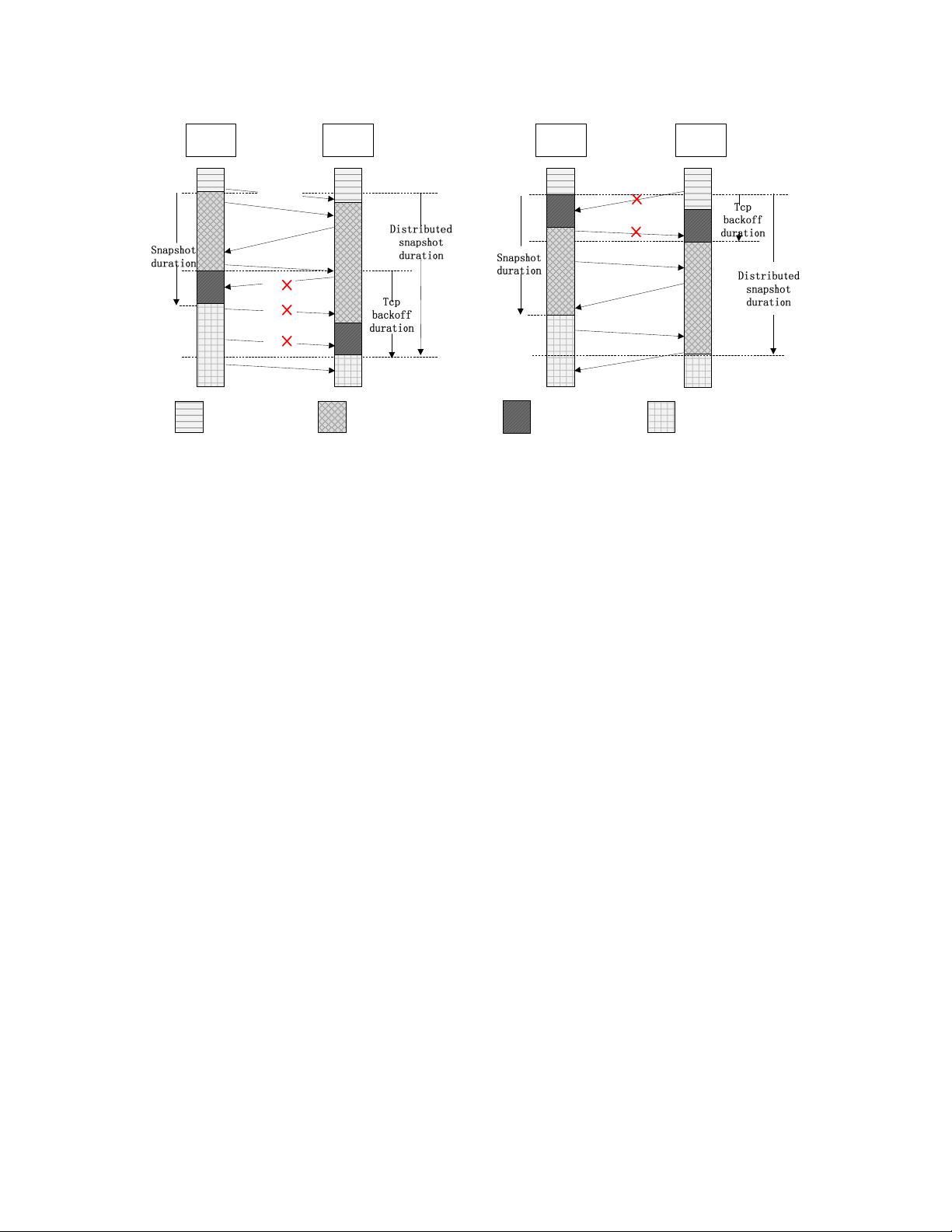
discrepancy of snapshot completion times among VMs
brings the TCP backoff problem, resulting in network in-
terruption between two communicating VMs. This paper
proposes HotSnap, a VMC snapshot approach designed
to enable taking hot distributed snapshot with millisec-
onds system downtime and TCP backoff duration. At the
core of HotSnap is transient snapshot that saves the min-
imum instantaneous state in a short time, and full snap-
shot which saves the entire VM state during normal oper-
ation. We then design the snapshot protocol to coordinate
the individual VM snapshots into the global consistent
state of VMC. We have implemented HotSnap on QE-
MU/KVM, and conduct several experiments to show the
effectiveness and efficiency. Compared to the live migra-
tion based distributed snapshot technique which brings
seconds of system downtime and network interruption,
HotSnap only incurs tens of milliseconds.
1 Introduction
With the increasing prevalence of cloud computing and
IaaS paradigm, more and more distributed application-
s and systems are migrating to and running on virtual-
ization platform. In virtualized environments, distribut-
ed applications are encapsulated into virtual machines,
which are connected into virtual machine cluster (VM-
C) and coordinated to complete the heavy tasks. For
example, Amazon EC2 [1] offers load balancing web
farm which can dynamically add or remove virtual ma-
chine (VM) nodes to maximize resource utilization; Cy-
berGuarder [22] encapsulates security services such as
IDS and firewalls into VMs, and deploys them over a
virtual network to provide virtual network security ser-
vice; Emulab [12] leverages VMC to implement on-
demand virtual environments for developing and testing
networked applications; the parallel applications, such as
map-reduce jobs, scientific computing, client-server sys-
tems can also run on the virtual machine cluster which
provides an isolated, scaled and closed running environ-
ment.
Distributed snapshot [13, 27, 19] is a critical technique
to improve system reliability for distributed applications
and systems. It saves the running state of the application-
s periodically during the failure-free execution. Upon a
failure, the system can resume the computation from a
recorded intermediate state rather than the initial state,
thereby reducing the amount of lost computation [15]. It
provides the system administrators the ability to recover
the system from failure owing to hardware errors, soft-
ware errors or other reasons.
Since the snapshot process is always carried out peri-
odically during normal execution, transparency is a key
feature when taking distributed snapshot. In other word-
s, the users or applications should be unaware of the
snapshot process, neither the snapshot implementation
scheme nor the performance impact. However, the tra-
ditional distributed systems either implement snapshot
in OS kernel [11], or modify the MPI library to sup-
port snapshot function [17, 24]. Besides, many systems
even leave the job to developers to implement snapshot
on the application level [3, 25]. These technologies re-
quire modification of OS code or recompilation of appli-
cations, thus violating the transparency from the view of
implementation schema.
The distributed snapshot of VMC seems to be an ef-

剩余14页未读,继续阅读
资源评论


weixin_38682086
- 粉丝: 6
- 资源: 984









最新资源
- 【岗位说明】办事处经理岗位职责.doc
- 【岗位说明】办事处经理职能说明书.doc
- 【岗位说明】仓库管理员岗位职责说明书.doc
- 【岗位说明】采购专员岗位职责.doc
- 【岗位说明】厂长岗位职责.doc
- 【岗位说明】财务助理岗位职责.doc
- 【岗位说明】采购经理岗位职责.doc
- 【岗位说明】大区经理岗位职责.doc
- 【岗位说明】大区经理的职能描述书.doc
- 【岗位说明】车间主任岗位职责.doc
- 【岗位说明】服务业各部门职能描述.doc
- 【岗位说明】副总经理岗位职责.doc
- 【岗位说明】副厂长职务描述书.doc
- 【岗位说明】副厂长岗位职责.doc
- 【岗位说明】副总经理职务描述书.doc
- 【岗位说明】工厂人事经理岗位说明书.doc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


