
分布式时序数据库分布式时序数据库QTSDB的设计与实现的设计与实现
QTSDB 简述
QTSDB是一个分布式时间序列数据库,用于处理海量数据写入与查询。实现上,是基于开源单机时序数据库influxdb 1.7开发
的分布式版本,除了具有influxdb本身的特性之外,还有容量扩展、副本容错等集群功能。
主要特点如下:
为时间序列数据专门编写的高性能数据存储, 兼顾写入性能和磁盘空间占用;
类sql查询语句, 支持多种统计聚合函数;
自动清理过期数据;
内置连续查询,自动完成用户预设的聚合操作;
Golang编写,没有其它的依赖, 部署运维简单;
节点动态水平扩展,支持海量数据存储;
副本冗余设计,自动故障转移,支持高可用;
优化数据写入,支持高吞吐量;
系统架构
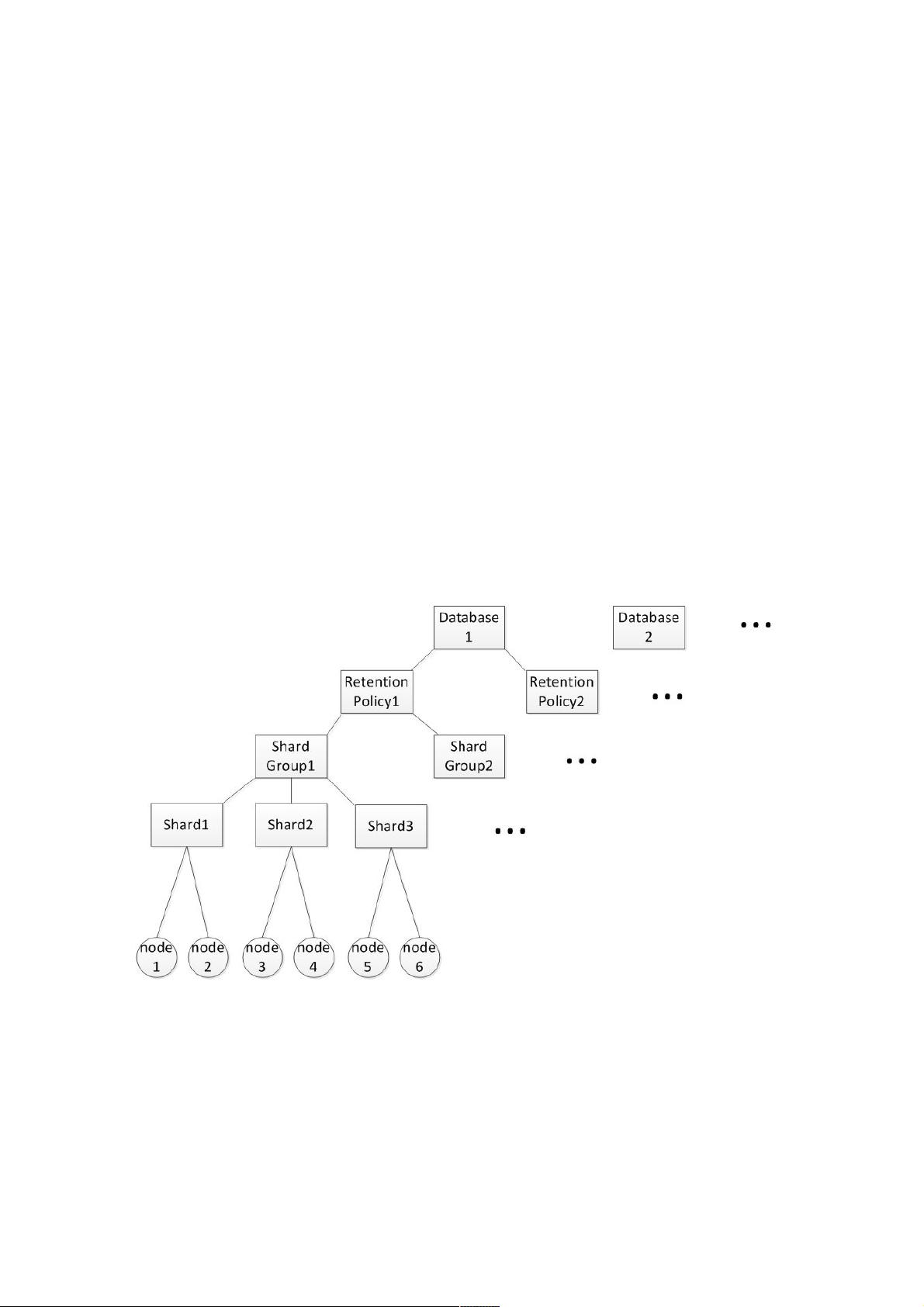
逻辑存储层次结构
influxdb架构层次最高是database,database下边根据数据保留时长不同分成了不同的retension policy,形成了database下面
的多个存储容器,因为时序数据库与时间维度关联,所以将相同保留时长的内容存放到一起,便于到期删除。除此之外,在
retension policy之下,将retension policy的保留时长继续细分,每个时间段的数据存储在一个shard group中,这样当某个分
段的shard group到期之后,会将其整个删掉,避免从存储引擎内部抠出部分数据。例如,在database之下的数据,可能是30
天保留时长,可能是7天保留时长,他们将存放在不同的retension policy之下。假设将7天的数据继续按1天进行划分,就将他
们分别存放到7个shard group中,当第8天的数据生成时,会新建一个shard group写入,并将第 1天的shard group整个删除。
到此为止,同一个retension policy下,发来的当下时序数据只会落在当下的时间段,也就是只有最新的shard group有数据写
入,为了提高并发量,一个shard group又分成了多个shard,这些shard全局唯一,分布于所有物理节点上,每个shard对应一
个tsm存储引擎,负责存储数据。
在请求访问数据时,通过请求的信息可以锁定某个database和retension policy,然后根据请求中的时间段信息,锁定某个
(些)shard group。对于写入的情况,每条写入的数据都对应一个serieskey(这个概念后面会介绍),通过对serieskey进行
哈希取模就能锁定一个shard,进行写入。而shard是有副本的,在写入的时候会采用无主多写的策略同时写入到每个副本中。
查询时,由于查询请求中没有serieskey的信息,所以只能将shard group内的shard都查询一遍,针对一个shard,会在其副本
资源评论













