

9
Seed-Guided Topic Model for Document Filtering
and Classification
CHENLIANG LI and SHIQIAN CHEN, Wuhan University, China
JIAN XING, Hithink RoyalFlush Information Network Co., Ltd, China
AIXIN SUN, Nanyang technological University, Singapore
ZONGYANG MA, Microsoft (China) Co., Ltd, China
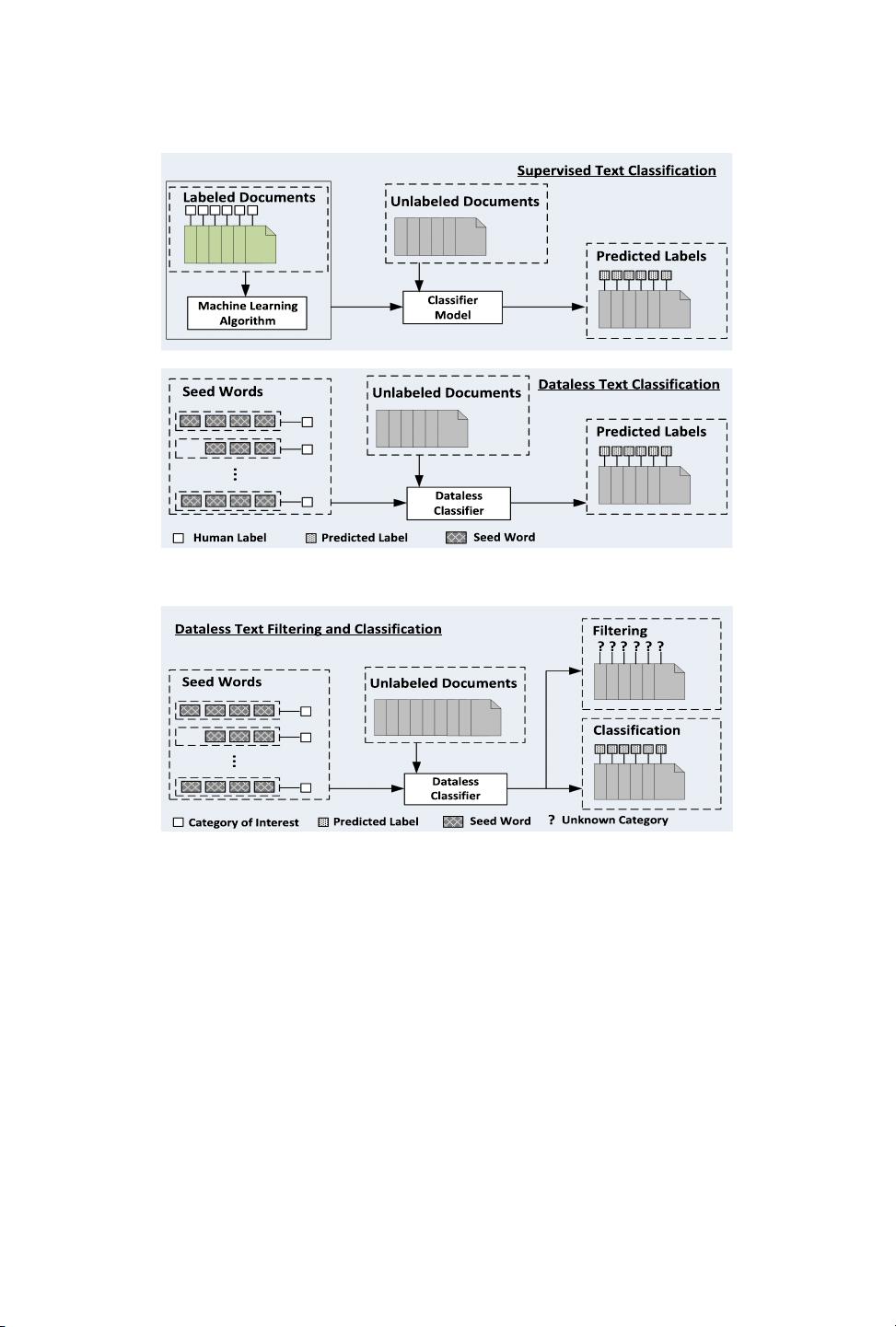
One important necessity is to lter out the irrelevant information and organize the relevant information into
meaningful categories. However, developing text classiers often requires a large number of labeled docu-
ments as training examples. Manually labeling documents is costly and time-consuming. More importantly, it
becomes unrealistic to know all the categories covered by the documents beforehand. Recently, a few methods
have been proposed to label documents by using a small set of relevant keywords for each category, known as
dataless text classication. In this article, we propose a seed-guided topic model for the dataless text ltering
and classication (named DFC). Given a collection of unlabeled documents, and for each specied category
a small set of seed words that are relevant to the semantic meaning of the category, DFC lters out the ir-
relevant documents and classies the relevant documents into the corresponding categories through topic
inuence. DFC models two kinds of topics: category-topics and general-topics. Also, there are two kinds of
category-topics: relevant-topics and irrelevant-topics. Each relevant-topic is associated with one specic cat-
egory, representing its semantic meaning. The irrelevant-topics represent the semantics of the unknown cat-
egories covered by the document collection. And the general-topics capture the global semantic information.
DFC assumes that each document is associated with a single category-topic and a mixture of general-topics.
A novelty of the model is that DFC learns the topics by exploiting the explicit word co-occurrence patterns
between the seed words and regular words (i.e., non-seed words) in the document collection. A document is
then ltered, or classied, based on its posterior category-topic assignment. Experiments on two widely used
datasets show that DFC consistently outperforms the state-of-the-art dataless text classiers for both classi-
cation with ltering and classication without ltering. In many tasks, DFC can also achieve comparable or
even better classication accuracy than the state-of-the-art supervised learning solutions. Our experimental
results further show that DFC is insensitive to the tuning parameters. Moreover, we conduct a thorough study
about the impact of seed words for existing dataless text classication techniques. The results reveal that it
This article is an extended version of Reference [28], a paper presented at the 25th International ACM CIKM Conference
(Indianapolis, IN, Oct. 24–28, 2016).
This research was supported by National Natural Science Foundation of China (Grant No. 61502344), Natural Science
Foundation of Hubei Province (Grant No. 2017CFB502), Natural Scientic Research Program of Wuhan University (Grants
No. 2042017kf0225 and No. 2042016kf0190), Academic Team Building Plan for Young Scholars from Wuhan University
(Grant No. Whu2016012) and Singapore Ministry of Education Academic Research Fund Tier 2 (Grant No. MOE2014-T2-
2-066).
Authors’ addresses: C. Li (corresponding author) and S. Chen, Wuhan University, School of Cyber Science and Engineering,
Bayi Road, Wuhan, Hubei, 430075, China; emails: {cllee, sqchen}@whu.edu.cn; J. Xing, Hithink RoyalFlush Information
Network Co., Ltd, Hangzhou, Zhejiang, 310023, China; email: xingjian@myhexin.com; A. Sun, Nanyang Technological
University, School of Computer Science and Engineering, 639798, Singapore; email: axsun@ntu.edu.sg; Z. Ma, Microsoft
(China) Co., Ltd, Soochow, 215123, China; email: mzyone@gmail.com.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee
provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and
the full citation on the rst page. Copyrights for components of this work owned by others than ACM must be honored.
Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires
prior specic permission and/or a fee. Request permissions from permissions@acm.org.
© 2018 ACM 1046-8188/2018/12-ART9 $15.00
https://doi.org/10.1145/3238250
ACM Transactions on Information Systems, Vol. 37, No. 1, Article 9. Publication date: December 2018.



剩余36页未读,继续阅读
资源评论


weixin_38623080
- 粉丝: 5
- 资源: 1002









最新资源
- 【培训实施】-05-培训计划及实施方案.docx.doc
- 【培训实施】-03-企业培训整体规划及实施流程.docx
- 【培训实施】-08-培训实施.docx
- 【培训实施】-06-培训实施方案.docx
- 【培训实施】-11-培训实施流程 .docx
- 【培训实施】-09-公司年度培训实施方案.docx
- 【培训实施】-10-培训实施计划表.docx
- 【培训实施】-14-培训实施流程图.xlsx
- 【培训实施】-13-培训实施流程.docx
- 【培训实施】-12-企业培训实施流程.docx
- CentOS7修改默认启动级别
- 基于web的旅游管理系统的设计与实现论文.doc
- 02-培训师管理制度.docx
- 01-公司内部培训师管理制度.docx
- 00-如何塑造一支高效的企业内训师队伍.docx
- 05-某集团内部培训师管理办法.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


