

Robust and efficient face recognition via low-rank
supported extreme learning machine
Tao Lu
1,2
& Yingjie Guan
1
& Yanduo Zhang
1
&
Shenming Qu
3
& Zixiang Xiong
2
Received: 18 April 2017 / Revised: 23 November 2017 / Accepted: 29 November 2017 /
Published online: 23 December 2017
#
Springer Science+Business Media, LLC, part of Springer Nature 2017
Multimed Tools Appl (2018) 77:11219–11240
https://doi.org/10.1007/s11042-017-5475-2
* Tao Lu
lutxyl@gmail.com
* Zixiang Xiong
zx@ece.tamu.edu
1
School of Computer Science and Engineering, Wuhan Institute of Technology, Wuhan 430073, China
2
Department of Electrical and Computer Engineering, Texas A&M University, College Station, TX
77843, USA
3
School of Software, Henan University, Kaifeng 475001, China
Abstract Recently, face recognition algorithms have made great progress in various real-
world applications, e.g., authentication and criminal investigation. Deep-learning offers an
end-to-end paradigm for vision recognition tasks and achieves good performance. However,
designing and training the complex network architecture are time-consuming and labor-
intensive. Moreover, under complex scenarios, illumination change, noise or occlusion in
images degrade the performance of recognition algorithms. In order to ameliorate these issues,
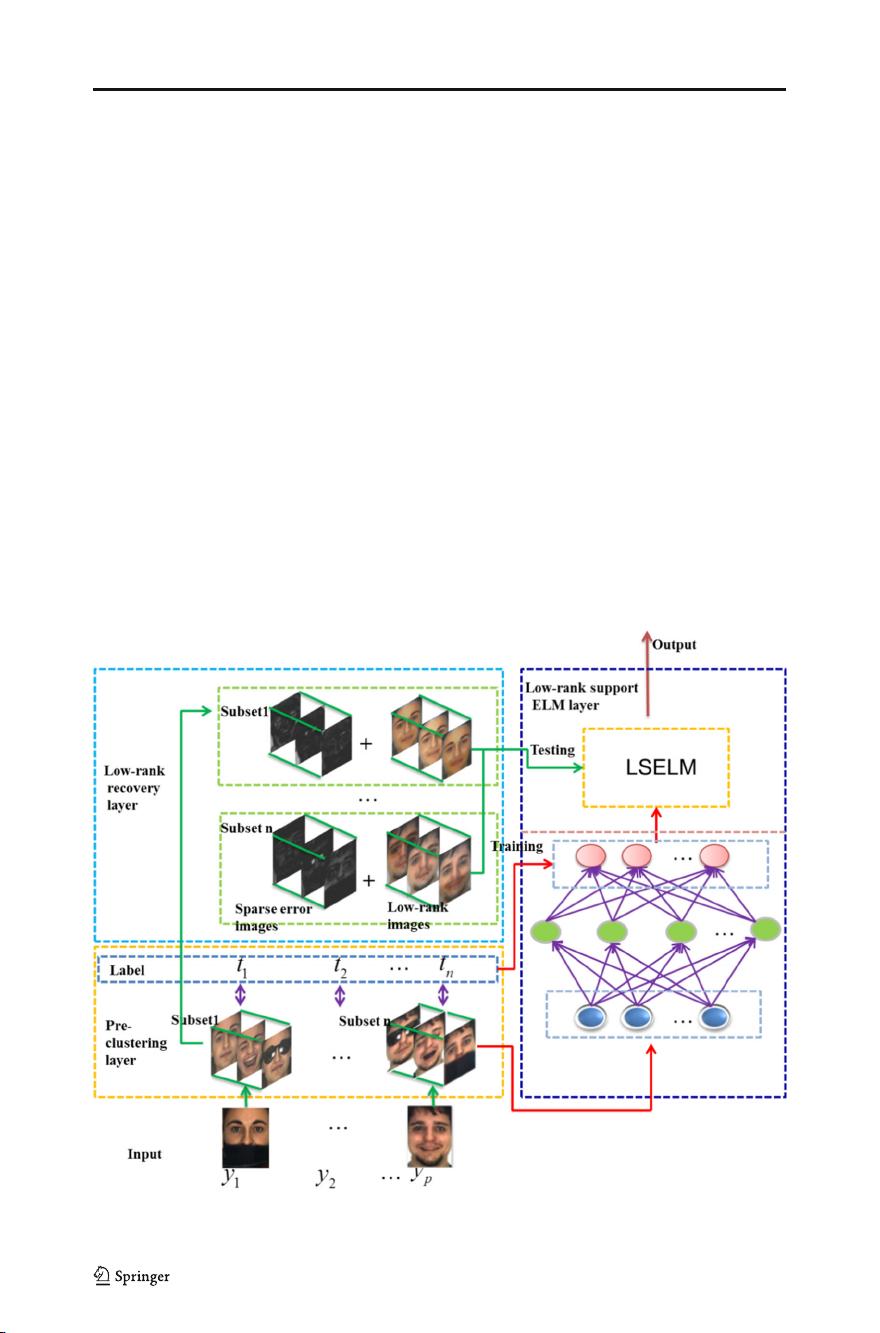
we propose an efficient three-layered low-rank supported extreme learning machine (LSELM)
algorithm for face recognition which improves the recognition performance under complex
scenarios with high efficiency. In the first layer, a given probe sample is clustered into certain
training subspace as pre-clustering. In the second laye r, with this subspace, a low-rank
subspace of probe sample as robust feature which is insensitive to disguise, noise, v ariant
expression or illumination will be recovered by low-rank decomposition. Furthermore,
these low-rank discriminative features are coded to support training a forward neural
network termed LSELM. Experimental results indicate that the proposed approach is on
par with some deep-learning based face recognition algorithms on recognition perfor-
mance but with less time complexity over some popular face datasets e.g., A R, Extend
Yale-B, CMU PIE and LFW datasets.


剩余21页未读,继续阅读
资源评论


weixin_38617851
- 粉丝: 4
- 资源: 923









最新资源
- XR3DI Rendering Engine Advanced 3.27 材料渲染器
- chrome-plugin-demo-啊哦111
- Dejahu-Safety-Helmet-Wearing-Dataset-肆十二
- love-u.js-js
- guage-bigdata-note-hadoop安装与配置
- enphp_opensource-echo命令
- 无线Xilinx FPGA调试器ESP32-XVC-FPGA开发资源
- js-leetcode题解之第36-valid-sudoku.js
- CSP 题解-CSP竞赛资源
- js-leetcode题解之35-search-insert-position.js
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


