
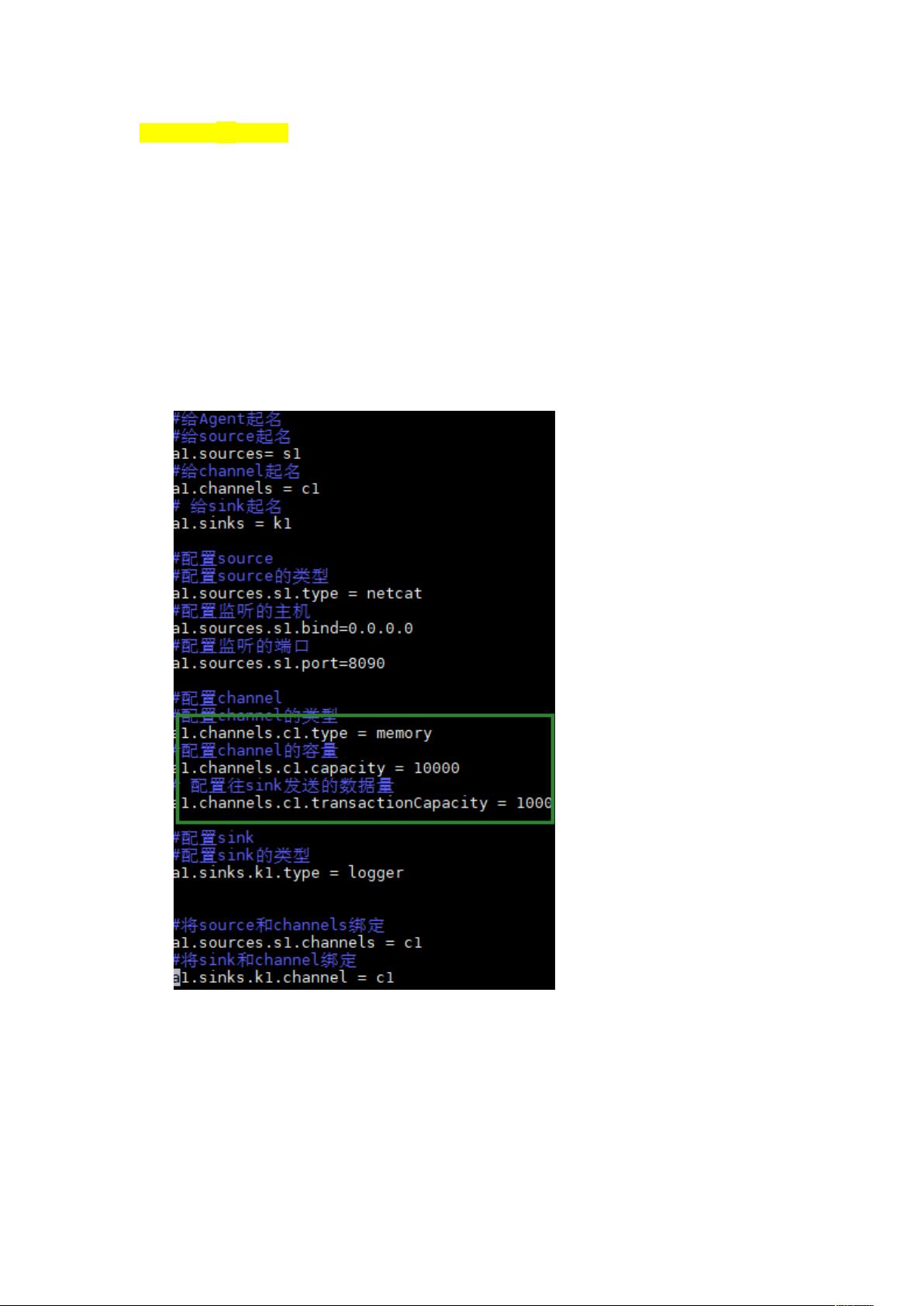
A. Flume 的 channel
Source 收集到的事件(Event 对象,一条日志就是要给 event 对象,Flume 中流动的是
event 对象)的存储位置有,内存、文件、数据库
一、Memory Channel
事件临时缓存在内存中,Memory Channel 允许数据丢失
可配置选项
Type:memory
Capacity:事件存储在信道中的最大数量,默认 100 个 event(一个 event 对象最大 100B)
对象。实际工作中调节到 100W(约等于占用 1M 内存)
transactionCapacity: 默认 100 个 event 对象,每个事务中的 event 对象,建
议调节 1000-3000
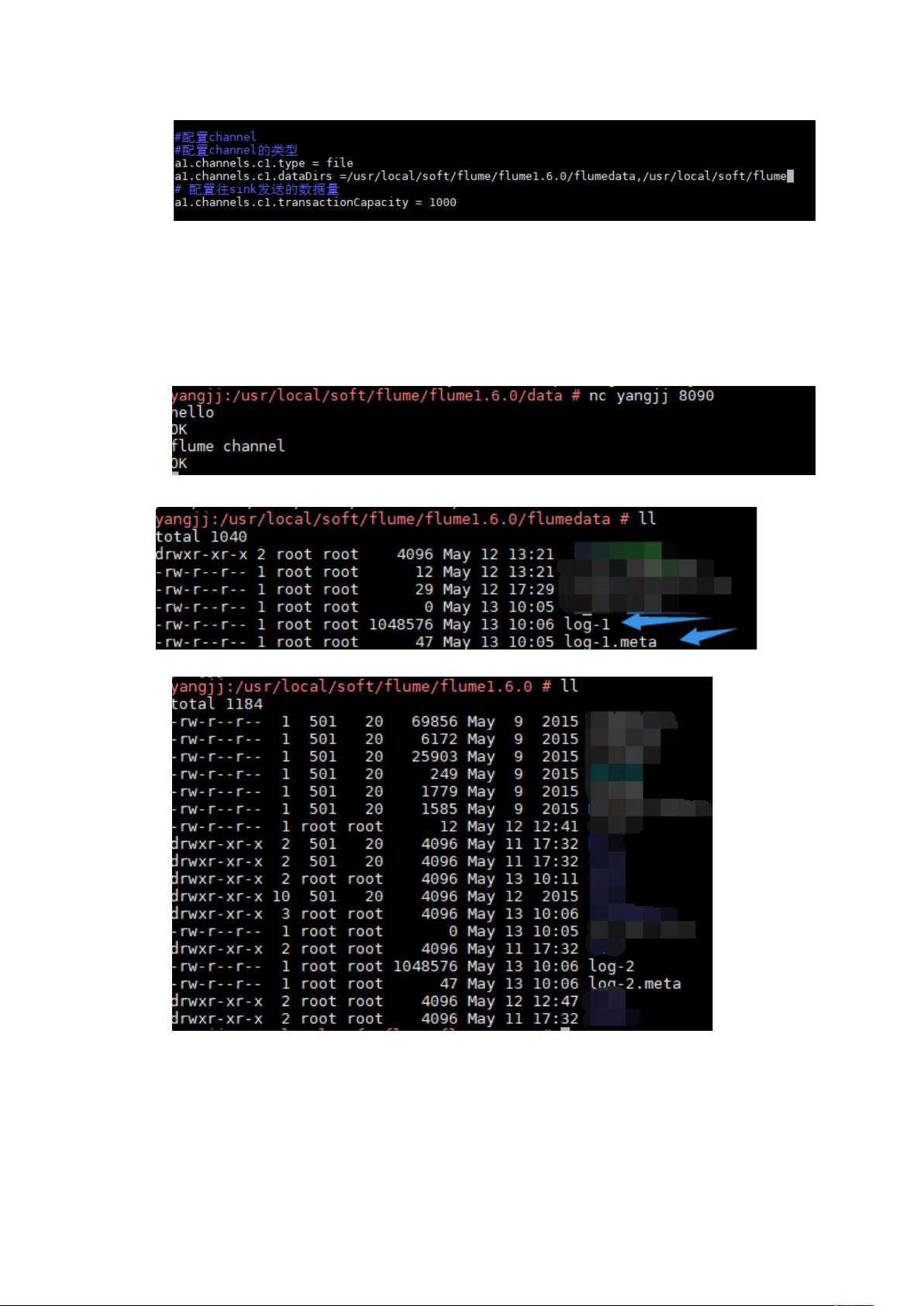
二、 File Channel
事件(Evnent 对象)存储到文件中,不易丢失
可配置选项:
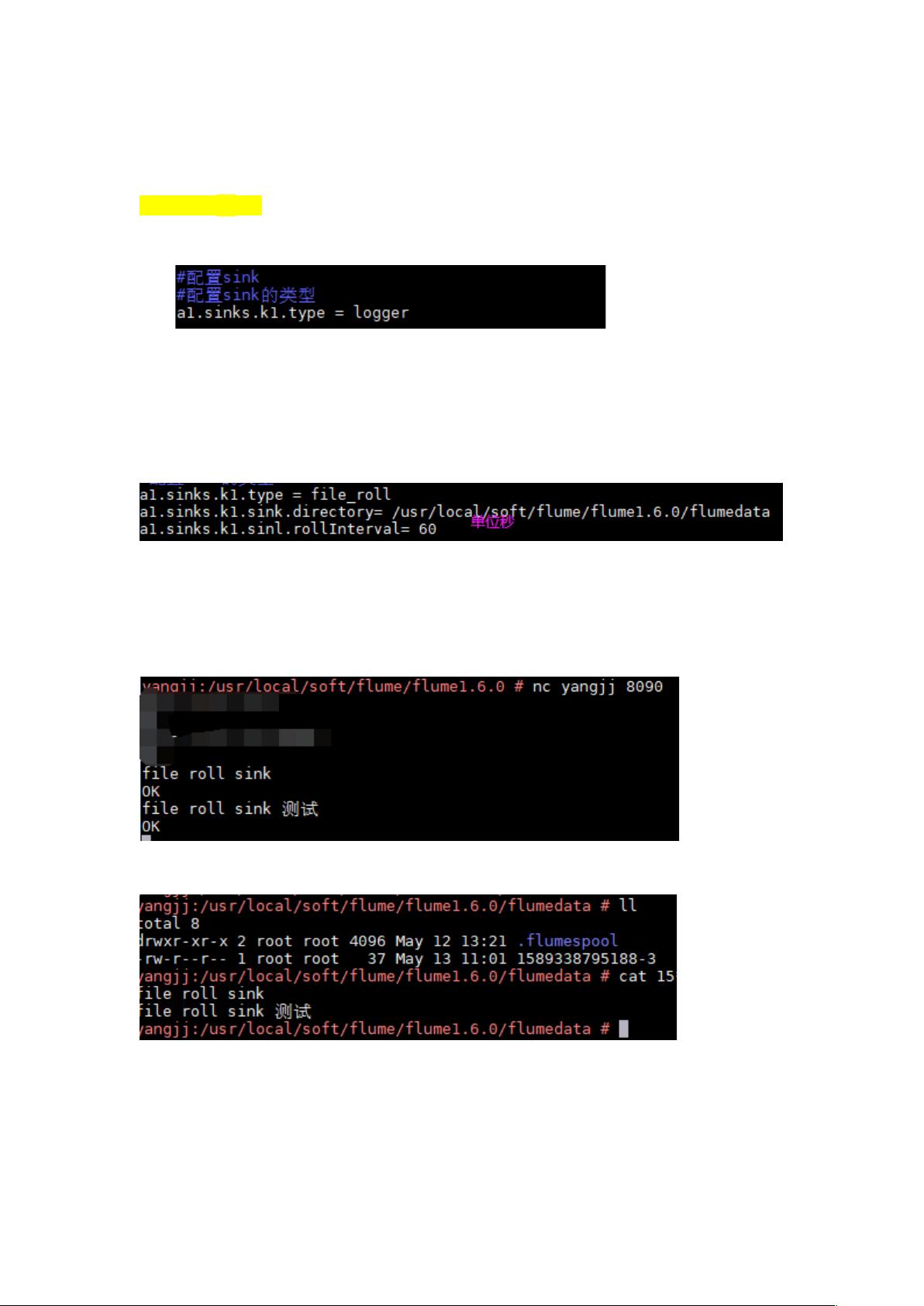
剩余18页未读,继续阅读
资源评论













