
196 •
电子技术与软件工程
Electronic Technology & Software Engineering
数据库技术
•
Data Base Technique
【关键词】K-means 聚类 SSE 全局最优解 初
始聚类中心
1 引言
聚类分析能够实现数据的归类,是数据挖
掘的重要方法。K-means 在聚类算法中的收敛
速度较快,可以对数据进行预处理,产生数据
的基本分布规律,但是传统的 K-means 算法中
人为确定聚类数 k,初始聚类中心的 k 个点随
机选取,均影响到了聚类结果。本文针对 k 个
聚类点的选取提出改进,增加 K-means 算法的
稳定性。
2 K-means聚类算法
2.1 传统的K-means算法
设有数据点集 {X
u
},X
u
是 u 维空间的一
个点,u 表示全部属性个数,人工设定聚类数
为 k:
(1)在 {X
u
} 中任取 k 个初始聚类中心点,
记为 {W
u
},k<u,W
u
∈ X
u
;
(2)计算 X
u
和 W
u
的欧氏距离,归于最
近的簇;
(3)更新聚类中心点,以各簇的均值代
替原聚类中心点;
(4)重复(2)(3),直到连续两次聚
类中心的距离小于或等于某阈值。
2.2 K-means的收敛测度SSE
聚类效果体现于聚类函数 SSE 的 值,
若 SSE 的值越小,认为聚类效果越好。设
SSE= ∑ ∑ ‖Xu-Wu‖
2
,对 W
u
求偏导数,并
基于 SSE 的全局最优 K-means 算法
文/董炎焱
传统的 K-means 聚 类 算 法 对
初值敏感,随机的初始聚类中心
会造成簇的不稳定。本文采取全
局搜索的方法避免了局部最优解,
实验证明,采用 SSE 作为分类的
标准,可以提高簇的稳定性。
摘
要
取为 0,得到 ,m 是以 W
u
为聚类中
心的点个数, 就是 SSE 函数在 W
u
类的最
优解,每一次迭代,SSE 将减小,最终趋于收敛。
2.3 传统K-means的局限性
聚类数人为确定,在大多数情况下,以
人的先验知识不足以分清类别,要么 k 值偏小,
忽略差别,要么 k 值偏大,过分强调类别,因
此 k 值的选取需要多次的尝试,得到较为合理
的聚类数。
SSE 是非凸函数,由于初始聚类中心的选
取是随机的,会形成局部最小值,不能保证是
全局最小值,可多次更新初始聚类中心,重复
算法,取其中最小的 SSE。
3 全局最优解的K-means聚类算法
3.1 算法原理
设数据集点 {X
u
},k 为聚类个数,{W
u
}
为聚类中心点集:
(1)k=1,求解 ,其中 m 为数据点
个数,得到第一个初始聚类中心 w
u
1
;
(2)k=2,将第一个聚类中心 w
u
1
分别与
x
u
1
,x
u
2
,x
u
3
,……x
u
m
进行 K-means 聚类,分
别求出每次聚类的 SSE
i
,找到 min{SSE
i
},记
录与之对应的第二个聚类中心 w
u
2
;
(3)k=3,将 w
u
1
、w
u
2
分别与 x
u
1
,x
u
2
,
x
u
3
, ……x
u
m
进行K-means 聚类,记录与
min{SSE
i
} 对应的第三个聚类中心 w
u
3
;
(4)依次类推,其中 k<m。
3.2 对比实验
实验数据来源为中华人民共和国统计局
发布的“第六次人口普查”中“1-8 各地区分
性别、受教育程度的 6 岁及以上人口”的统计
数据,选用该数据的原因是不考虑异常数据对
实验的影响,取对数后进行聚类分析。
传统的 K-means 算法对初始聚类中心点
随机选取,得到的聚类结果不稳定,设 k=3,
三次实验分别取不同的初始聚类中心,结果如
表 1。
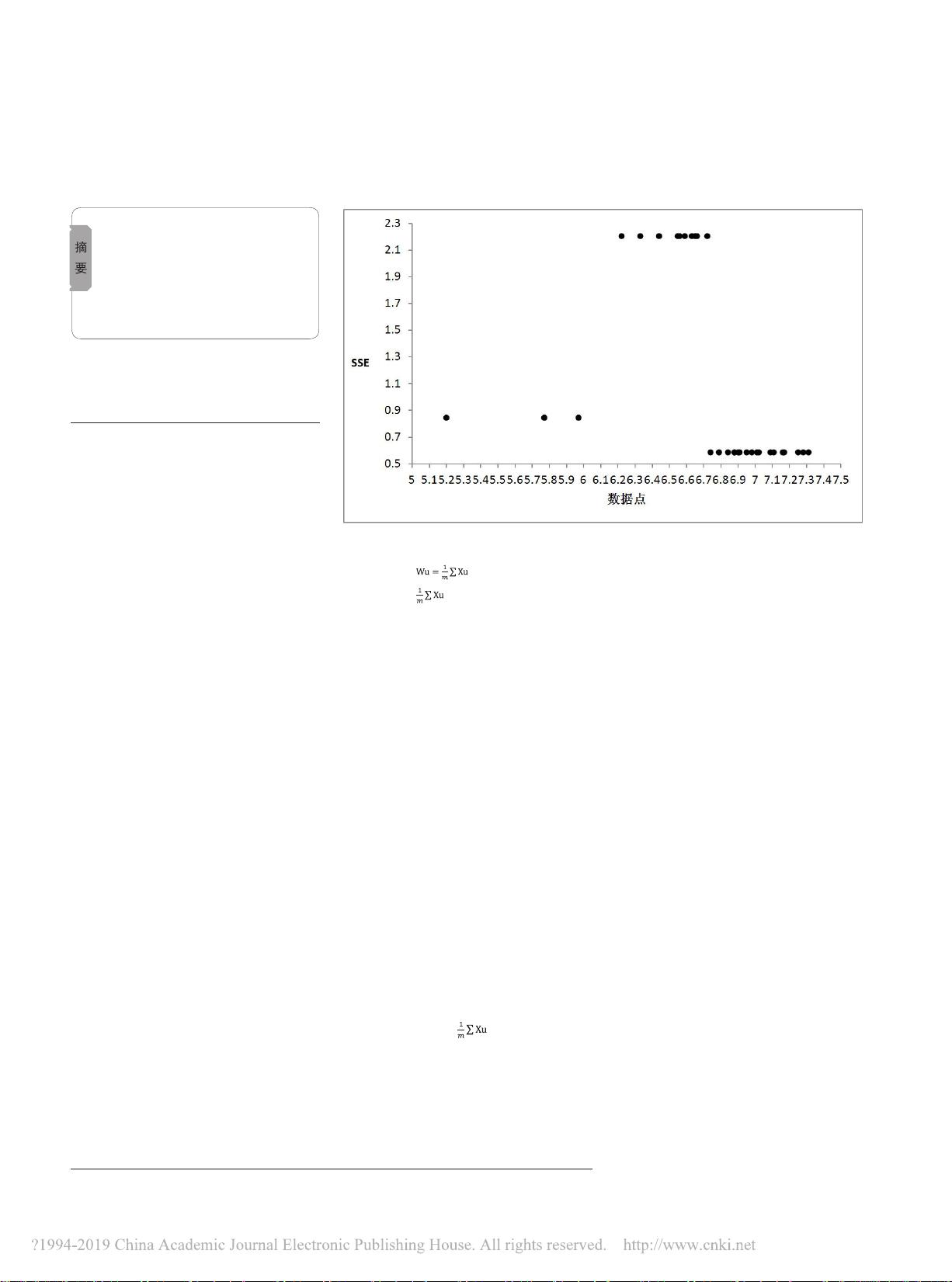
实验四为全局最优解的K-means 聚类
算法,第一个初始聚类中心是数据集的均值
w
u
1
=6.73,数据集的每个点分别作为第二个初
始聚类中心进行 K-means 聚类,得到 SSE,如
表 2。
将表 2 的数值以图形表示,如图 1。
3.3 实验分析
传统的 K-means 聚类算法对初始聚类中
●课题名称:基于职教云平台的混合式学习实践研究;课题类型:规划课题;课题编号:GH-17154。
图 1:各数据点作为初始聚类中心的 SSE













评论0