
作者:红色石头 公众号:AI有道(id:redstonewill)
上节课我们主要介绍了KernelSVM。先将特征转换和计算内积这两个步骤合并起来,
简化计算、提高计算速度,再用DualSVM的求解方法来解决。KernelSVM不仅能解
决简单的线性分类问题,也可以求解非常复杂甚至是无限多维的分类问题,关键在于
核函数的选择,例如线性核函数、多项式核函数和高斯核函数等等。但是,我们之前
讲的这些方法都是HardMarginSVM,即必须将所有的样本都分类正确才行。这往往
需要更多更复杂的特征转换,甚至造成过拟合。本节课将介绍一种SoftMargin
SVM,目的是让分类错误的点越少越好,而不是必须将所有点分类正确,也就是允许
有noise存在。这种做法很大程度上不会使模型过于复杂,不会造成过拟合,而且分类
效果是令人满意的。
上节课我们说明了一点,就是SVM同样可能会造成overfit。原因有两个,一个是由于
我们的SVM模型(即kernel)过于复杂,转换的维度太多,过于powerful了;另外一
个是由于我们坚持要将所有的样本都分类正确,即不允许错误存在,造成模型过于复
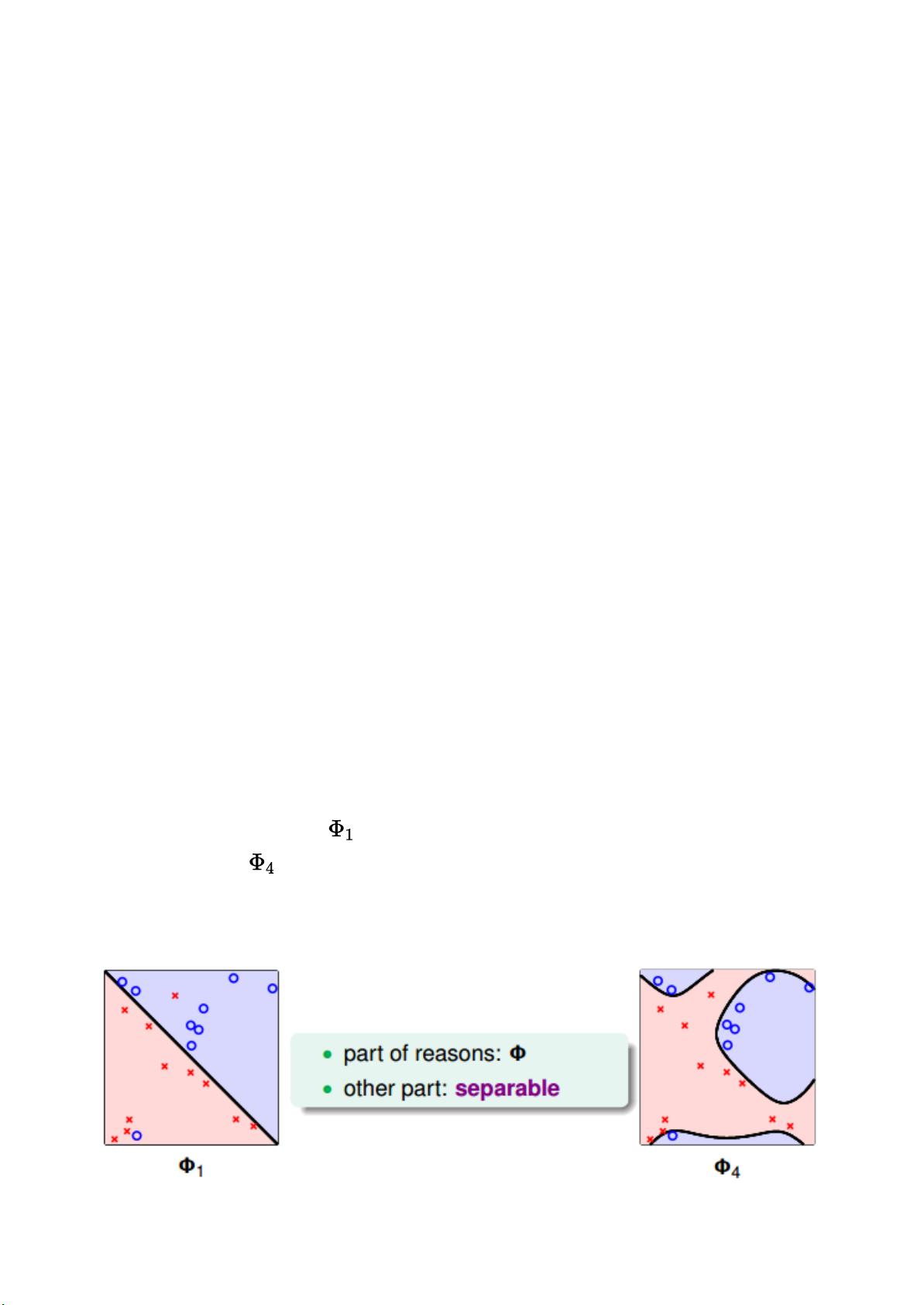
杂。如下图所示,左边的图 是线性的,虽然有几个点分类错误,但是大部分都能完
全分开。右边的图 是四次多项式,所有点都分类正确了,但是模型比较复杂,可能
造成过拟合。直观上来说,左边的图是更合理的模型。
如何避免过拟合?方法是允许有分类错误的点,即把某些点当作是noise,放弃这些
林轩田《机器学习技法》课程笔记4SoftMargin
SupportVectorMachine
MotivationandPrimalProblem

剩余10页未读,继续阅读

巧笑倩兮Evelina
- 粉丝: 26
- 资源: 335









最新资源
- GSDML-V2.3-TURCK-BL20-E-GW-EN-20140826-010300.xml
- 基于串行并行ADMM算法的主从配电网分布式优化控制研究 关键词:ADMM 串行并行算法 主动配电网 无功优化 分布式优化 参考文献: 1 参考《主动配电网分布式无功优化控制方法》配电网优化模型
- SAP ERP系统中信用控制配置详解及应用场景分析
- gsdml-v2.25-auto-sm877-pnt-20221215.xml
- 钢筋弯曲折断机step全套技术资料100%好用.zip
- gsdml-v2.31-leuze-bcl348i-20150923.xml
- 钢构复合板打胶机sw16可编辑全套技术资料100%好用.zip
- GSDML-V2.31-Pepperl+Fuchs-PXV100-20171030.xml
- 高压水阀装配生产线sw17可编辑全套技术资料100%好用.zip
- gsdml-v2.31-siemens-sinamics-g120s-vector-20170904.xml
- gsdml-v2.33-sick-dl100hf-20190312.xml
- 环模制粒机step全套技术资料100%好用.zip
- GSDML-V2.34-SICK-Lector63x-1P-20190118.xml
- 基于java的springcloud房产销售平台设计新版源码+数据库+说明
- 基于java的滴答拍摄影项目设计新版源码+数据库+说明
- 基于java的线上教学平台设计新版源码+数据库+说明
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0