林轩田《机器学习基石》课程笔记4 -- Feasibility of Learning1

需积分: 0 20 浏览量
更新于2022-08-03
收藏 1.02MB PDF 举报
《机器学习基石》课程笔记4探讨了机器学习的可行性,主要围绕三个主题展开:学习的不可能性、概率的救援以及与学习的关联。它指出机器学习在面对某些问题时可能无法找到一个通用的解决方案,这是因为不同的模型可能在训练数据上表现良好,但在未见过的数据上却无法保持准确性。这一现象被称为“没有免费午餐”(No Free Lunch, NFL)定理,意味着不存在一种学习算法总能在所有问题上优于其他算法。
接着,笔记引入概率论的概念,以解决机器学习中的不确定性。通过概率理论,我们可以利用有限的样本数据对整体的未知情况进行推断。例如,通过随机抽取样本估计罐子中橙色球的比例,即使不能确定确切比例,但随着样本数量增加,我们可以得到一个大概且接近真实比例的估计,这就是Hoeffding不等式的基础。在机器学习中,这相当于通过大量独立同分布的训练样本来估计模型在所有数据上的表现,即Probably Approximately Correct (PAC)学习框架。
PAC学习理论提供了一种度量模型在未知数据上的泛化能力的方法。它将模型在训练数据上的错误率()与在所有数据上的错误率()联系起来。如果在训练数据上的错误率很低,那么在所有数据上的错误率也很可能很低。Hoeffding不等式确保了这种概率关系,允许我们在有限的样本上构建模型,同时有信心它在更大的数据集上也能表现良好。
在机器学习的上下文中,假设(hypothesis)与目标函数(target function)的匹配程度可以通过概率来量化。如果训练样本足够大且独立同分布,那么我们可以通过训练样本的错误率来近似整个数据分布的错误率。这使得机器学习模型能够在采样数据之外的全局数据上进行有效的预测。
总结而言,笔记4讨论了机器学习的局限性,揭示了学习过程中必须考虑的不确定性和泛化能力。通过概率理论和PAC学习,我们可以理解如何从有限的训练数据中构建模型,并期望这些模型能够在未见过的数据上表现出良好的性能。然而,这也依赖于一些关键条件,如样本的独立同分布和足够的样本数量。因此,在实际应用中,选择合适的学习算法、保证数据质量以及正确评估模型的泛化能力至关重要。

作者:红色石头 公众号:AI有道(id:redstonewill)
上节课,我们主要介绍了根据不同的设定,机器学习可以分为不同的类型。其中,监
督式学习中的二元分类和回归分析是最常见的也是最重要的机器学习问题。本节课,
我们将介绍机器学习的可行性,讨论问题是否可以使用机器学习来解决。
首先,考虑这样一个例子,如下图所示,有3个label为1的九宫格和3个label为+1的九
宫格。根据这6个样本,提取相应label下的特征,预测右边九宫格是属于1还是+1?
结果是,如果依据对称性,我们会把它归为+1;如果依据九宫格左上角是否是黑色,
我们会把它归为1。除此之外,还有根据其它不同特征进行分类,得到不同结果的情
况。而且,这些分类结果貌似都是正确合理的,因为对于6个训练样本来说,我们选择
的模型都有很好的分类效果。
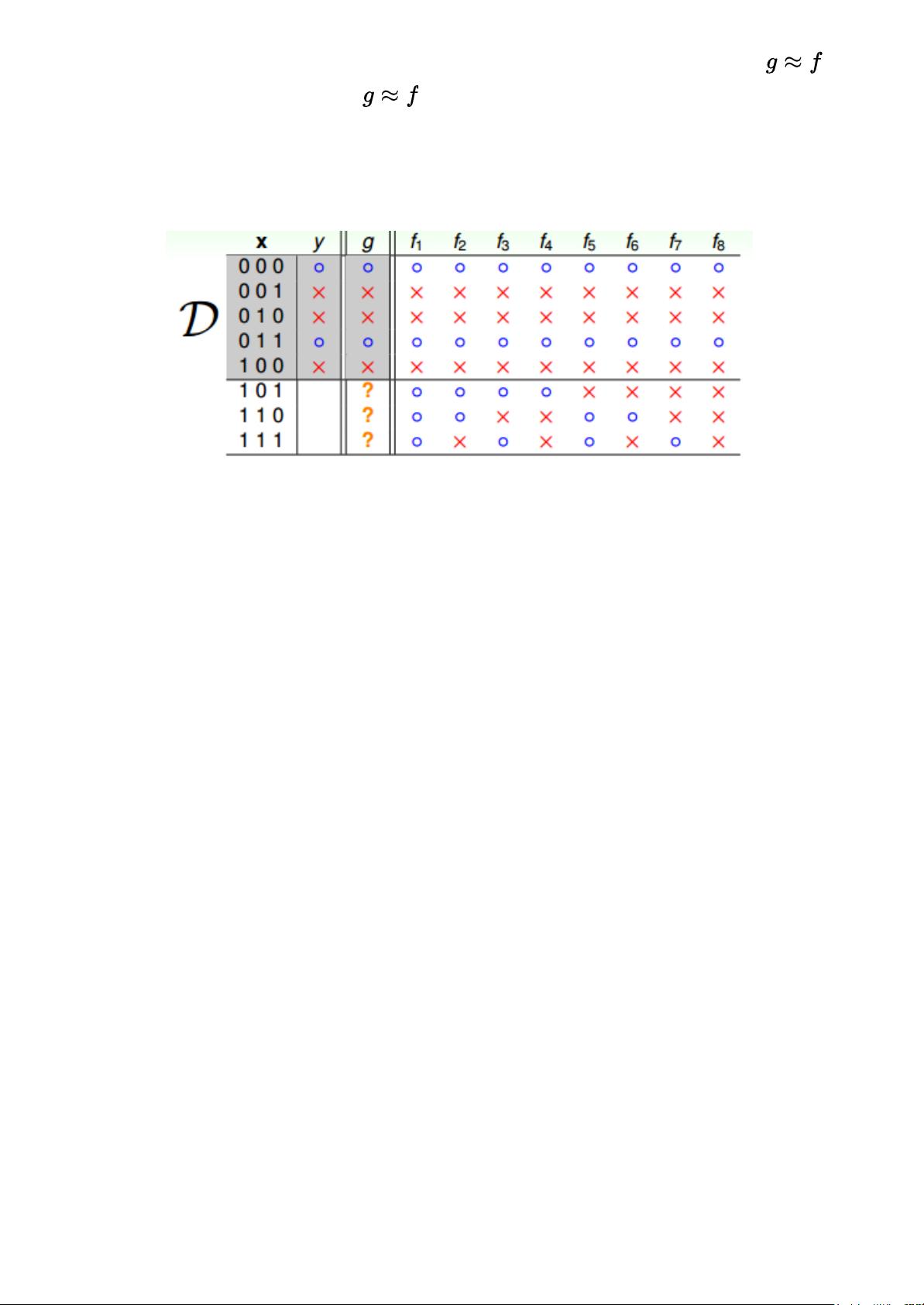
再来看一个比较数学化的二分类例子,输入特征x是二进制的、三维的,对应有8种输
入,其中训练样本D有5个。那么,根据训练样本对应的输出y,假设有8个
hypothesis,这8个hypothesis在D上,对5个训练样本的分类效果效果都完全正确。但
林轩田《机器学习基石》课程笔记4Feasibilityof
Learning
一、LearningisImpossible
剩余7页未读,继续阅读
2020-10-01 上传
2021-02-07 上传
159 浏览量
2012-11-17 上传
2021-02-11 上传
2021-02-11 上传
2009-12-15 上传
199 浏览量
186 浏览量
2015-04-26 上传
2019-05-21 上传
117 浏览量
2021-02-06 上传
2015-11-09 上传
146 浏览量
157 浏览量
113 浏览量
资源评论


尹子先生
- 粉丝: 30
- 资源: 324









最新资源
- SQL语言详细教程:从基础到高级全面解析及实际应用
- 仓库管理系统源代码全套技术资料.zip
- 计算机二级考试详细试题整理及备考建议
- 全国大学生电子设计竞赛(电赛)历年试题及备考指南
- zigbee CC2530网关+4节点无线通讯实现温湿度、光敏、LED、继电器等传感节点数据的采集上传,网关通过ESP8266上传远程服务器及下发控制.zip
- 云餐厅APP项目源代码全套技术资料.zip
- vscode 翻译插件开发,选中要翻译的单词,使用快捷键Ctrl+Shift+T查看翻译
- mrdoc-alpine0.9.2
- ACMNOICSP比赛经验分享:从知识储备到团队协作的全面指南
- 云餐厅项目源代码全套技术资料.zip
- 基于STM32的数字闹钟系统的仿真和程序
- 混合信号设计中DEF文件创建流程
- 美国大学生数学建模竞赛(美赛)详细教程:从组队到赛后总结全攻略
- 病媒生物孳生地调查和治理工作方案.docx
- 保姆的工作标准.docx
- 病媒生物防制指南.docx
