大数据技术之Kylin.docx
需积分: 13 169 浏览量
2020-02-13
15:27:42
上传
评论
收藏 9.11MB DOCX 举报

大数据技术之 Kylin
版本:V1.0
第 1 章 概述
1.1 Kylin 定义
Apache Kylin 是一个开源的分布式分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口
及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它
能在亚秒内查询巨大的 Hive 表。
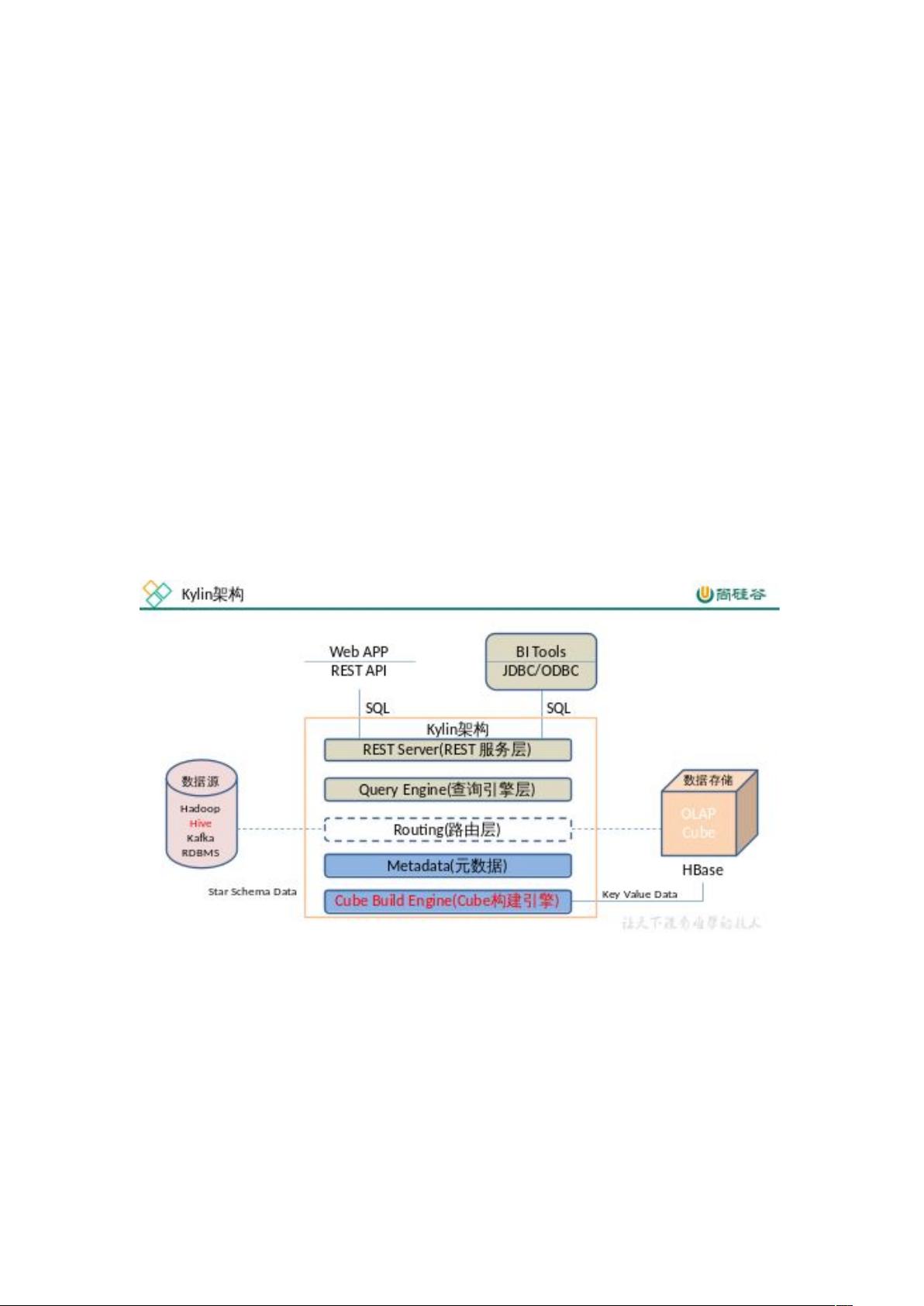
1.2 Kylin 架构
1)REST Server
REST Server 是一套面向应用程序开发的入口点,旨在实现针对 Kylin 平台的应用开发
工作。 此类应用程序可以提供查询、获取结果、触发 cube 构建任务、获取元数据以及获
取用户权限等等。另外可以通过 Restful 接口实现 SQL 查询。
2)查询引擎(Query Engine)
当 cube 准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它
组件进行交互,从而向用户返回对应的结果。



剩余40页未读,继续阅读






评论0
最新资源