Fine-tuning Graph
版权申诉
142 浏览量
2024-06-18
14:23:10
上传
评论
收藏 8.77MB PDF 举报


Fine-tuning Graph Neural Networks by Preserving Graph Generative Patterns
Yifei Sun
1
, Qi Zhu
2
, Yang Yang
1
*
, Chunping Wang
3
, Tianyu Fan
1
, Jiajun Zhu
1
, Lei Chen
3
1
Zhejiang University, Hangzhou, China
2
University of Illinois Urbana-Champaign, USA
1
FinVolution Group, Shanghai, China
{yifeisun, yangya, fantianyu, junnian}@zju.edu.cn, qiz3@illinois.edu, {wangchunping02, chenlei04}@xinye.com
Abstract
Recently, the paradigm of pre-training and fine-tuning graph
neural networks has been intensively studied and applied in
a wide range of graph mining tasks. Its success is generally
attributed to the structural consistency between pre-training
and downstream datasets, which, however, does not hold in
many real-world scenarios. Existing works have shown that the
structural divergence between pre-training and downstream
graphs significantly limits the transferability when using the
vanilla fine-tuning strategy. This divergence leads to model
overfitting on pre-training graphs and causes difficulties in
capturing the structural properties of the downstream graphs.
In this paper, we identify the fundamental cause of structural
divergence as the discrepancy of generative patterns between
the pre-training and downstream graphs. Furthermore, we
propose G-TUNING to preserve the generative patterns of
downstream graphs. Given a downstream graph
G
, the core
idea is to tune the pre-trained GNN so that it can reconstruct
the generative patterns of
G
, the graphon
W
. However, the
exact reconstruction of a graphon is known to be computa-
tionally expensive. To overcome this challenge, we provide
a theoretical analysis that establishes the existence of a set
of alternative graphons called graphon bases for any given
graphon. By utilizing a linear combination of these graphon
bases, we can efficiently approximate
W
. This theoretical
finding forms the basis of our proposed model, as it enables
effective learning of the graphon bases and their associated
coefficients. Compared with existing algorithms, G-TUNING
demonstrates an average improvement of 0.5% and 2.6% on
in-domain and out-of-domain transfer learning experiments,
respectively.
1 Introduction
The development of graph neural networks (GNNs) has rev-
olutionized many tasks of various domains in recent years.
However, labeled data is extremely scarce due to the time-
consuming and laborious labeling process. To address this
obstacle, the “pre-train and fine-tune” paradigm has made
substantial progress (Xia et al. 2022; Li, Zhao, and Zeng
2022; Jiao et al. 2023) and attracted considerable research
interests. Specifically, this paradigm involves pre-training a
model on a large-scale graph dataset, followed by fine-tuning
its parameters on downstream graphs by specific tasks.
*
Corresponding author.
Copyright © 2024, Association for the Advancement of Artificial
The success of “pre-train and fine-tune” paradigm is gen-
erally attributed to the structural consistency between pre-
training and downstream graphs (Hu et al. 2020b,a; Qiu et al.
2020; Sun et al. 2021; Jiarong et al. 2023). However, in real-
world scenarios, structural patterns vary dramatically across
different graphs, and patterns in the downstream graphs may
not be readily available in the pre-training graph. In the con-
text of molecular graphs, a well-known out-of-distribution
problem arises when the training and testing graphs originate
from different environments, characterized by variations in
size or scaffold. As a consequence, the downstream molecular
graph data often encompasses numerous novel substructures
that has not been encountered during training. Hence, struc-
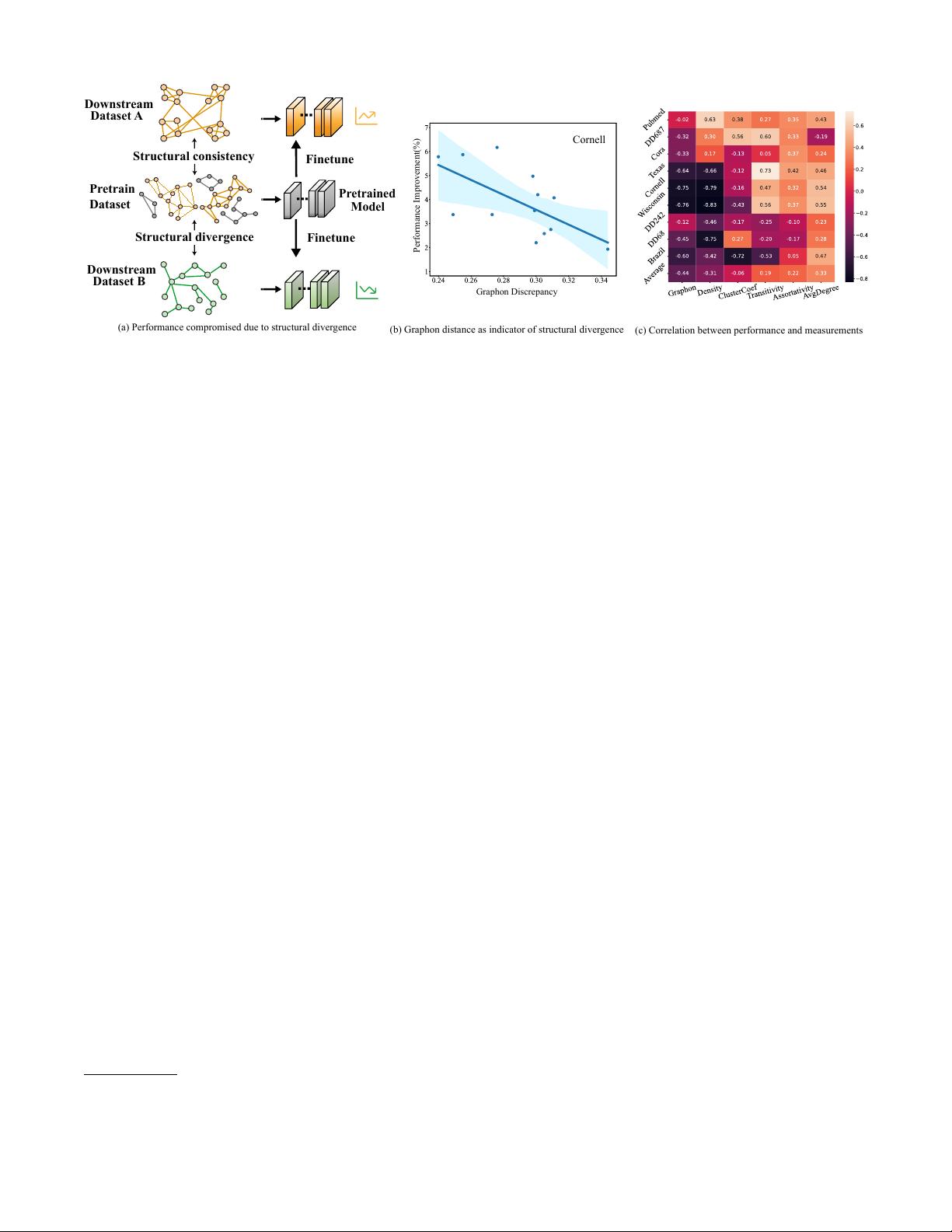
tural consistency does not always hold. Fig 1(a) shows that
while structural consistency (shown in orange) between the
pre-training and downstream dataset A ensures the promo-
tion of performance, the structural divergence (shown in
green) causes a degradation of performance when fine-tuned
on downstream dataset B. In some cases, it can even lead to
worse results than those obtained without pre-training.
In light of this, we are intrigued by the relationship be-
tween structural divergence and the extent of performance im-
provements on downstream graphs. Specifically, graphon is a
well-known non-parametric function on graph that has been
proved to effectively describe the generative mechanism of
graphs (i.e., generative patterns) (Lovász 2012). In Fig 1(b),
we calculate the Gromov-Wasserstain (GW) discrepancy (a
distance metric between geometry objects) of graphons be-
tween different pre-training and one test graph and report
the corresponding performance on the same downstream
graph. Interestingly, as the difference between graphons of
pre-training dataset and that of downstream dataset increases,
the performance improvement diminishes. To further validate
this, we compute the Pearson CC (Correlation Coefficient)
between other representative graph measurements (e.g., den-
sity, transitivity, etc.) and the performance improvement. As
Fig 1(c) suggests, most of them cannot reflect the degree
of performance improvement, and only the graphon discrep-
ancy is consistently negatively correlated with the degree
of performance promotion. Hence, we attribute the subpar
performance of fine-tuning to the disparity in the genera-
tive patterns between the pre-training and fine-tuning graphs.
Intelligence (www.aaai.org). All rights reserved.
arXiv:2312.13583v1 [cs.LG] 21 Dec 2023


剩余17页未读,继续阅读
资源评论


东方佑
- 粉丝: 8232
- 资源: 773

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- elasticsearch数据库下载、配置、使用案例
- springboot的概要介绍与分析
- C语言的概要介绍与分析
- 第一个较大的Android项目,基于Android平台的图书管理系统(Android studio).zip
- Cisco Packet Tracer 6.2 for Windows Instructor Version
- 使⽤pyIAST计算⽓体吸附选择性
- tmp_b056727e59b8123365486983f32baa9732607ec3c6137b12.pdf
- C代码实现文件的拆分和合并,本质上就是文件的读写操作.zip
- TVMP3player.apk.1
- 出马出马出马出马出马出马出马
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


