Fine-Tuning Language Models from Human Preferences.pdf
版权申诉


Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler
∗
Nisan Stiennon
∗
Jeffrey Wu Tom B. Brown
Alec Radford Dario Amodei Paul Christiano Geoffrey Irving
OpenAI
{dmz,nisan,jeffwu,tom,alec,damodei,paul,irving}@openai.com
Abstract
Reward learning enables the application of rein-
forcement learning (RL) to tasks where reward is
defined by human judgment, building a model of
reward by asking humans questions. Most work
on reward learning has used simulated environ-
ments, but complex information about values is of-
ten expressed in natural language, and we believe
reward learning for language is a key to making
RL practical and safe for real-world tasks. In this
paper, we build on advances in generative pretrain-
ing of language models to apply reward learning
to four natural language tasks: continuing text
with positive sentiment or physically descriptive
language, and summarization tasks on the TL;DR
and CNN/Daily Mail datasets. For stylistic con-
tinuation we achieve good results with only 5,000
comparisons evaluated by humans. For summa-
rization, models trained with 60,000 comparisons
copy whole sentences from the input but skip irrel-
evant preamble; this leads to reasonable ROUGE
scores and very good performance according to
our human labelers, but may be exploiting the fact
that labelers rely on simple heuristics.
1. Introduction
We would like to apply reinforcement learning to complex
tasks defined only by human judgment, where we can only
tell whether a result is good or bad by asking humans. To
do this, we can first use human labels to train a model of
reward, and then optimize that model. While there is a long
history of work learning such models from humans through
interaction, this work has only recently been applied to mod-
ern deep learning, and even then has only been applied to
relatively simple simulated environments (Christiano et al.,
2017; Ibarz et al., 2018; Bahdanau et al., 2018). By contrast,
real world settings in which humans need to specify com-
*
Equal contribution. Correspondence to paul@openai.com.
plex goals to AI agents are likely to both involve and require
natural language, which is a rich medium for expressing
value-laden concepts. Natural language is particularly im-
portant when an agent must communicate back to a human
to help provide a more accurate supervisory signal (Irving
et al., 2018; Christiano et al., 2018; Leike et al., 2018).
Natural language processing has seen substantial recent ad-
vances. One successful method has been to pretrain a large
generative language model on a corpus of unsupervised data,
then fine-tune the model for supervised NLP tasks (Dai and
Le, 2015; Peters et al., 2018; Radford et al., 2018; Khandel-
wal et al., 2019). This method often substantially outper-
forms training on the supervised datasets from scratch, and
a single pretrained language model often can be fine-tuned
for state of the art performance on many different super-
vised datasets (Howard and Ruder, 2018). In some cases,
fine-tuning is not required: Radford et al. (2019) find that
generatively trained models show reasonable performance
on NLP tasks with no additional training (zero-shot).
There is a long literature applying reinforcement learning to
natural language tasks. Much of this work uses algorithmi-
cally defined reward functions such as BLEU for translation
(Ranzato et al., 2015; Wu et al., 2016), ROUGE for summa-
rization (Ranzato et al., 2015; Paulus et al., 2017; Wu and
Hu, 2018; Gao et al., 2019b), music theory-based rewards
(Jaques et al., 2017), or event detectors for story generation
(Tambwekar et al., 2018). Nguyen et al. (2017) used RL
on BLEU but applied several error models to approximate
human behavior. Wu and Hu (2018) and Cho et al. (2019)
learned models of coherence from existing text and used
them as RL rewards for summarization and long-form gen-
eration, respectively. Gao et al. (2019a) built an interactive
summarization tool by applying reward learning to one ar-
ticle at a time. Experiments using human evaluations as
rewards include Kreutzer et al. (2018) which used off-policy
reward learning for translation, and Jaques et al. (2019)
which applied the modified Q-learning methods of Jaques
et al. (2017) to implicit human preferences in dialog. Yi
et al. (2019) learned rewards from humans to fine-tune dia-
log models, but smoothed the rewards to allow supervised
learning. We refer to Luketina et al. (2019) for a survey of
arXiv:1909.08593v2 [cs.CL] 8 Jan 2020
http://chat.xutongbao.top



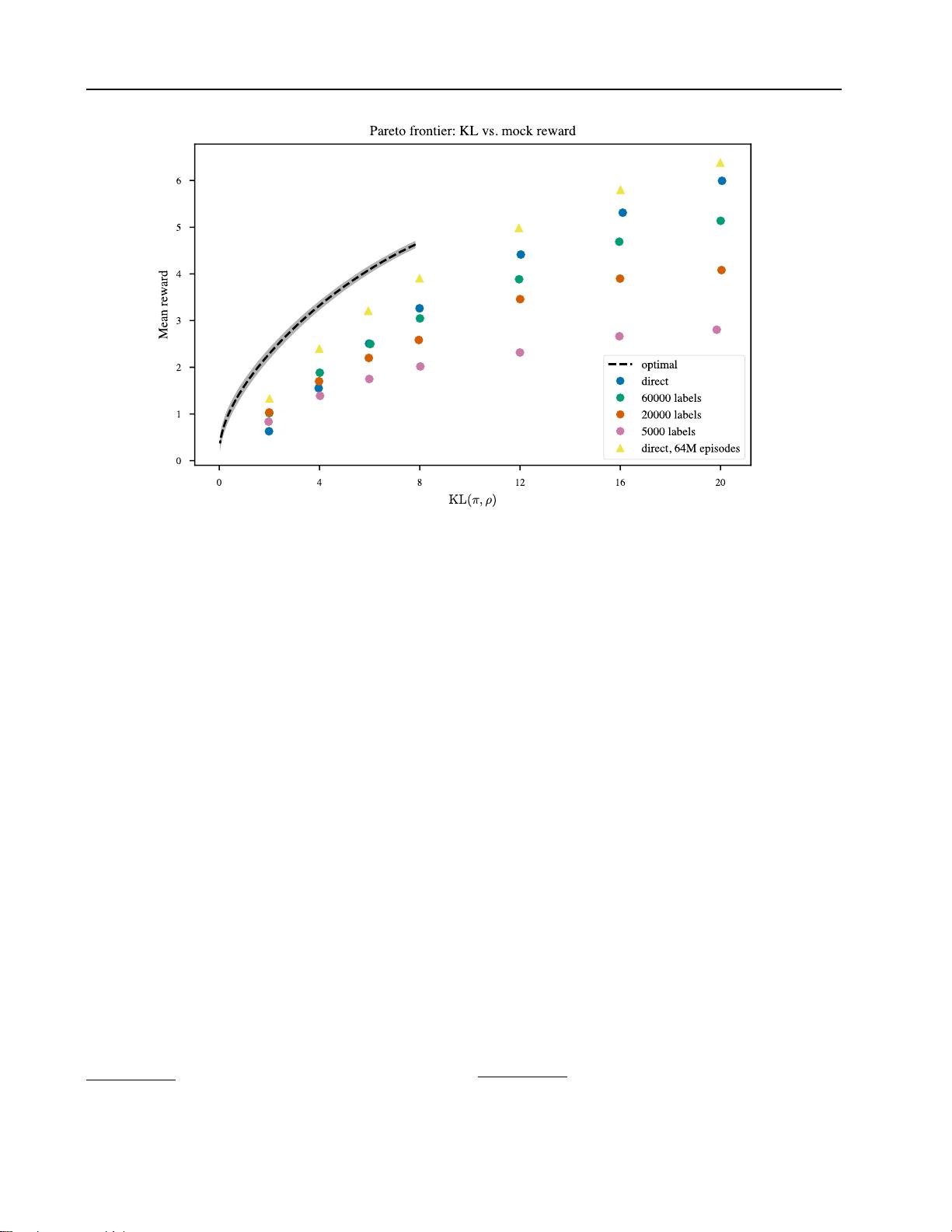
剩余25页未读,继续阅读
资源评论

 李需要2023-07-28感谢大佬分享的资源,对我启发很大,给了我新的灵感。
李需要2023-07-28感谢大佬分享的资源,对我启发很大,给了我新的灵感。












