

CHAID 算法(Chi-Square Automac Interacon Detecon)
CHAID 提供了一种在多个自变量中自动搜索能产生最大差异的变量方案。
不同于 C&R 树和 QUEST 节点,CHAID 分析可以生成非二进制树,即有些分割有两个以上的分
支。CHAID 模型需要一个单一的目标和一个或多个输入字段。还可以指定重量和频率领域。
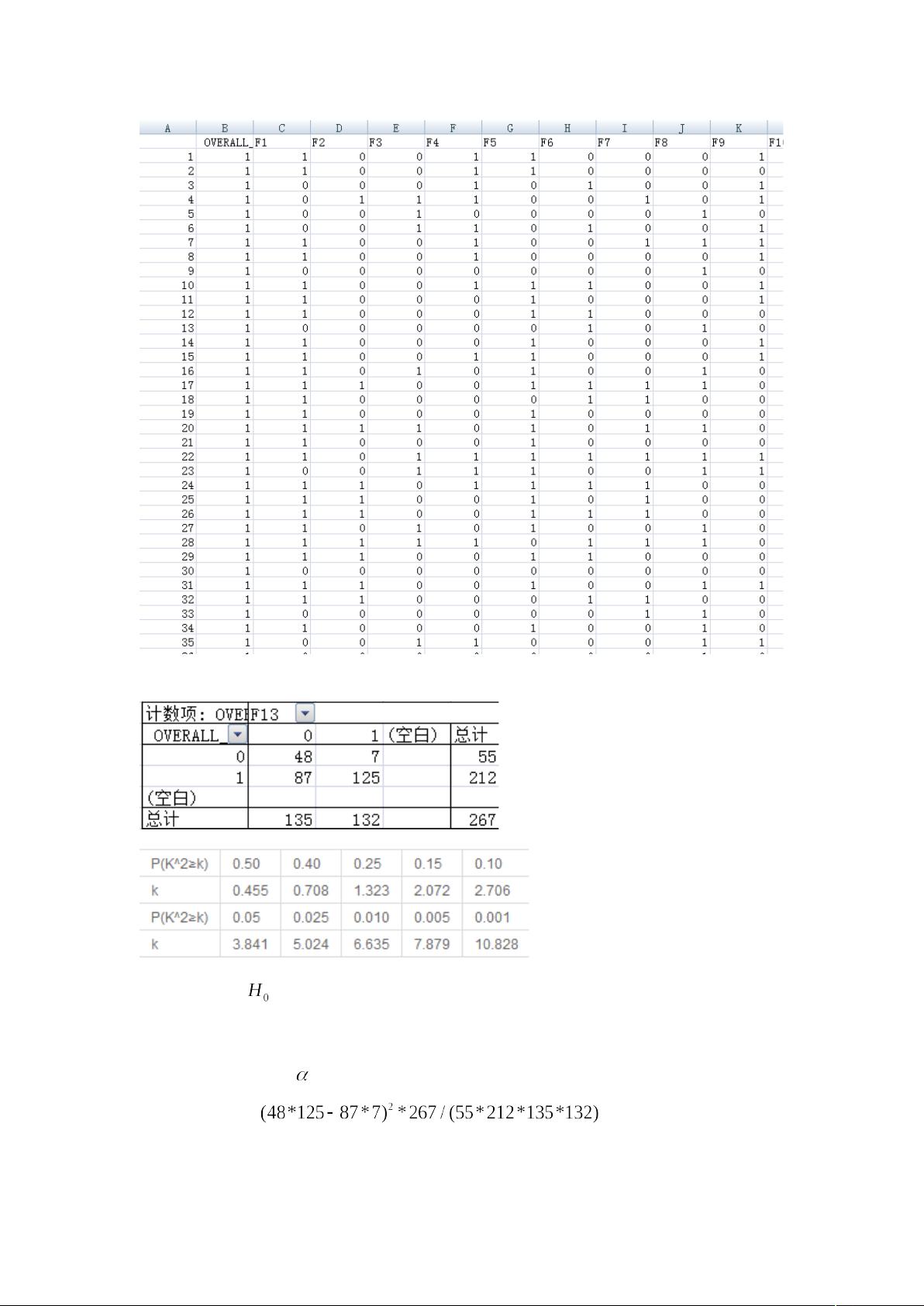
CHAID 分析,卡方自动交互检测,是一种用卡方统计,以确定最佳的分割,建立决策树的分类
方法。
1. CHAID 方法(卡方自动交叉检验)
CHAID 根据细分变量区分群体差异的显著性程度(卡方值)的大小顺序,将消费者分为不同的细
分群体,最终的细分群体是由多个变量属性共同描述的,因此属于多变量分析。
在形式上,CHAID 非常直观,它输出的是一个树状的图形。
1.它以因变量为根结点,对每个自变量(只能是分类或有序变量,也就是离散性的,如果是连
续变量,如年龄,收入要定义成分类或有序变量) 进行分类,计算分类的卡方值(Chi-Square-Test)。
如果几个变量的分类均显著,则比较这些分类的显著程度(P 值的大小),然后选择最显著的分类
法作为子节点。
2.CHIAD 可以自动归并自变量中类别,使之显著性达到最大。
3.最后的每个叶结点就是一个细分市场
CHAID 自动地把数据分成互斥的、无遗漏的组群,但只适用于类别型资料。
当预测变量较多且都是分类变量时,CHAID分类最适宜。
2. CHAID 分层的标准:卡方值最显著的变量
3. CHAID 过程:建立细分模型,根据卡方值最显著的细分变量将群体分出两个或多个群体,
对于这些群体再根据其它的卡方值相对最显著的细分变量继续分出子群体,直到没有统计意义
上显著的细分变量可以将这些子群体再继续分开为止。
4. CHAID 的一般步骤
-属性变量的预处理
-确定当前分支变量和分隔值
属性变量的预处理:
-对定类的属性变量,在其多个分类水平中找到对目标变量取值影响不显著的分类,并合并它们;
-对定距型属性变量,先按分位点分组,然后再合并具有同质性的组;
-如果目标变量是定类变量,则采用卡方检验
-如果目标变量为定距变量,则采用 F 检验
(统计学依据数据的计量尺度将数据划分为三大类,即定距型数据(Scale)、定序型数据
(Ordinal)和定类型数据(Nominal)。定距型数据通常指诸如身高、体重、血压等的连
续性数据,也包括诸如人数、商品件数等离散型数据;定序型数据具有内在固有大小或高低
顺序,但它又不同于定距型数据,一般可以数值或字符表示。如职称变量可以有低级、中级
和高级三个取值,可以分别用 1、2、3 等表示,年龄段变量可以有老、中、青三个取值,
分别用 A、B、C 表示等。这里无论是数值型的 1、2、3 还是字符型的 A、B、C,都是有大
小或高低顺序的,但数据之间却是不等距的。因为低级和中级职称之间的差距与中级和高级
职称之间的差距是不相等的;定类型数据是指没有内在固定大小或高低顺序,一般以数值或
字符表示的分类数据。)
F 检验:比较两组数据的方差 , ,假设检验两组数据没有显著差异,F<F 表,则接
受原假设,两组数据没有显著差异;F>F 表,拒绝原假设,两组数据存在显著差异。
属性变量预处理的具体策略

剩余11页未读,继续阅读
资源评论













