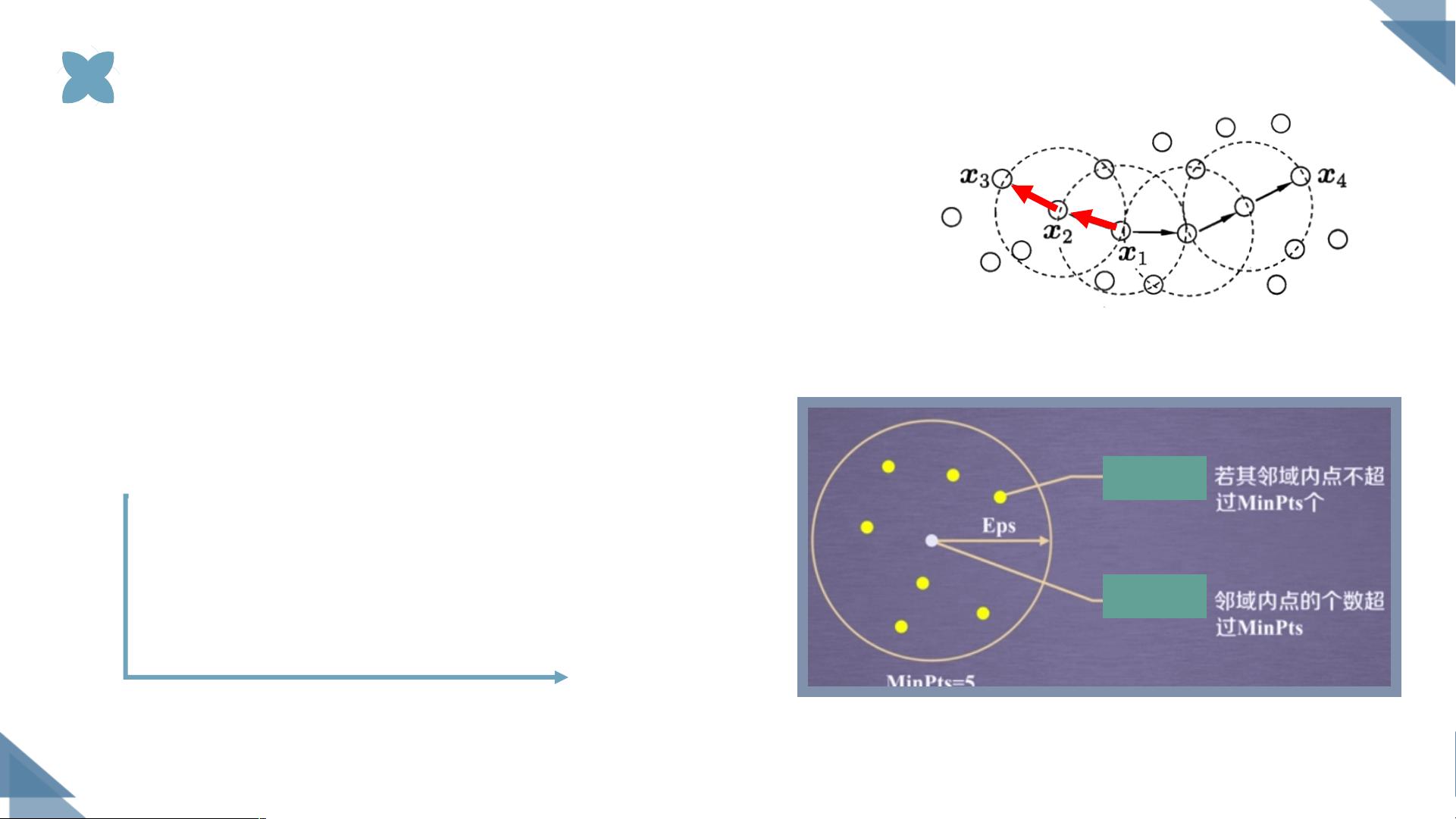
基于密度的聚类方法
基于密度的聚类方法以数据集在空间分布上的稠密程度为依据进行聚类,无需
预先设定簇的数量,因此特别适合对于未知内容的数据集进行聚类。
• DBSCAN(Density-Based Spatial Clustering of Applications with
Noise)
• OPTICS(Ordering Points To Identify the Clustering Structure)
• DENCLUE(Density-based Clustering)
• CLIQUE(Clustering In Quest)
代表性方法: