









针对热点新闻的 DBSCAN 聚
类模型识别预测报告
实验题目:针对热点新闻的 DBSCAN 聚类模型识别预测报告
班 级:
学 号:
姓 名:
日 期:

摘要
针对目前互联网“富信息化”现象,提出了基于机器学习的网络热点话题预
测的思想。该思想通过总结能尽量准确描述热点话题的一组特征,得到每篇新闻
各自的特征向量,并针对大量近期已知是否热门的随机新闻样本内容进行聚类处
理。
A machine learning based approach for predicting hot topics on the
internet is proposed to address the current phenomenon of "rich
informatization" in the internet. This idea summarizes a set of features
that can accurately describe hot topics as much as possible, obtains each
news feature vector, and performs clustering processing on a large number
of randomly selected news samples that are known to be popular recently.
关键词
机器学习 聚类分析 热点话题
一、实验背景
互联网信息发布的便利性使得大众每天面对爆炸性增长的信息冲击,大量文
本及文本信息在丰富大众生活的同时,也给用户带来了困扰。人们在获取固定信
息的同时,往往希望获取特定领域的流行信息。为满足人们的这种需求,互联网
新闻给出了相应的对策,如订阅热门话题、热门新闻上首页等措施。这些虽然在
一定程度上解决了上述需求,但热门信息的排序仍然需要人工手动添加完成,从
时间成本和人工成本上来说都十分浪费,并且用户也无法及时得到最新的热门资
讯。
为此,提出了基于机器学习的网络热点话题预测方法,该方法可以有效地满
足互联网用户的上述需求,并帮助新闻工作者有效减少工作量。利用机器学习带
来的便利性,不仅可以快速分类出热门新闻话题,并且可以做到按热门排序,这
样既能方便用户快速聚焦社会生活中的热门话题,同时也能帮助网页新闻工作者
大量减少因为排序而带来的简单重复的工作量。
在国际上,热门话题的发掘工作层出不穷。彭菲菲等人针对信息冗余等现象
提出了资源整合方法,对热点话题发现的关键技术做了一些改进
[1]
;王巍等人

针对Chen Kuan新闻报道侧重点的变化提出了基于多中心模型的热点话题发现算
法
[2]
;赖锦辉等人针对微博中孤立点较多的现象提出了消除孤立点的微博热点
话题发现方法,消除孤立点再用 CURE 算法聚类,效果较好,但仅针对特征明显
的微博进行研究
[3]
;基于微博进行了负面新闻的早期预测研究工作
[4]
,由于微
博特有的转发量、点赞数等多维度为其研究成果在其他领域的应用带来了一定的
局限性
[5]
。除了以上学术界的相关工作研究,商业领域也存在许多热点话题资
讯系统,比如常用的谷歌手机软件 Google Currents2.0 在最近的更新中就特别
加入了 Breaking Stories 版块
[6]
。总结以上研究成果,国内外仍没有很好的热
点话题预测研究,有的侧重点在挖掘而不在预测,有的着眼于预测却不具有很好
的扩展性。
本文提出一种实用性广、可预测性强的热点话题预测方法,总结出一组能尽
量准确描述热点话题特征,得到每篇新闻各自的特征向量,然后基于这组特征对
大量近期随机已知是否热门的样本新闻文本内容进行聚类处理,利用支持向量机
对数据进行分类。由于机器学习是一个需要反复修改的过程,该方法的另一个研
究重点就是在大量试验中修改并完善特征向量的组成、度量以及权重,最终希望
能达到准确作出热点话题分类即预测的目的。
二、原理方法
基于健壮精准的分类算法,利用支持向量机将向量映射到高维空间达到分类
目的。在机器学习过程中,采用大量试验的方法修改并完善特征向量的组成、度
量及权重,最终达到准确作出热点话题预测的目的。
(1)原理结构图
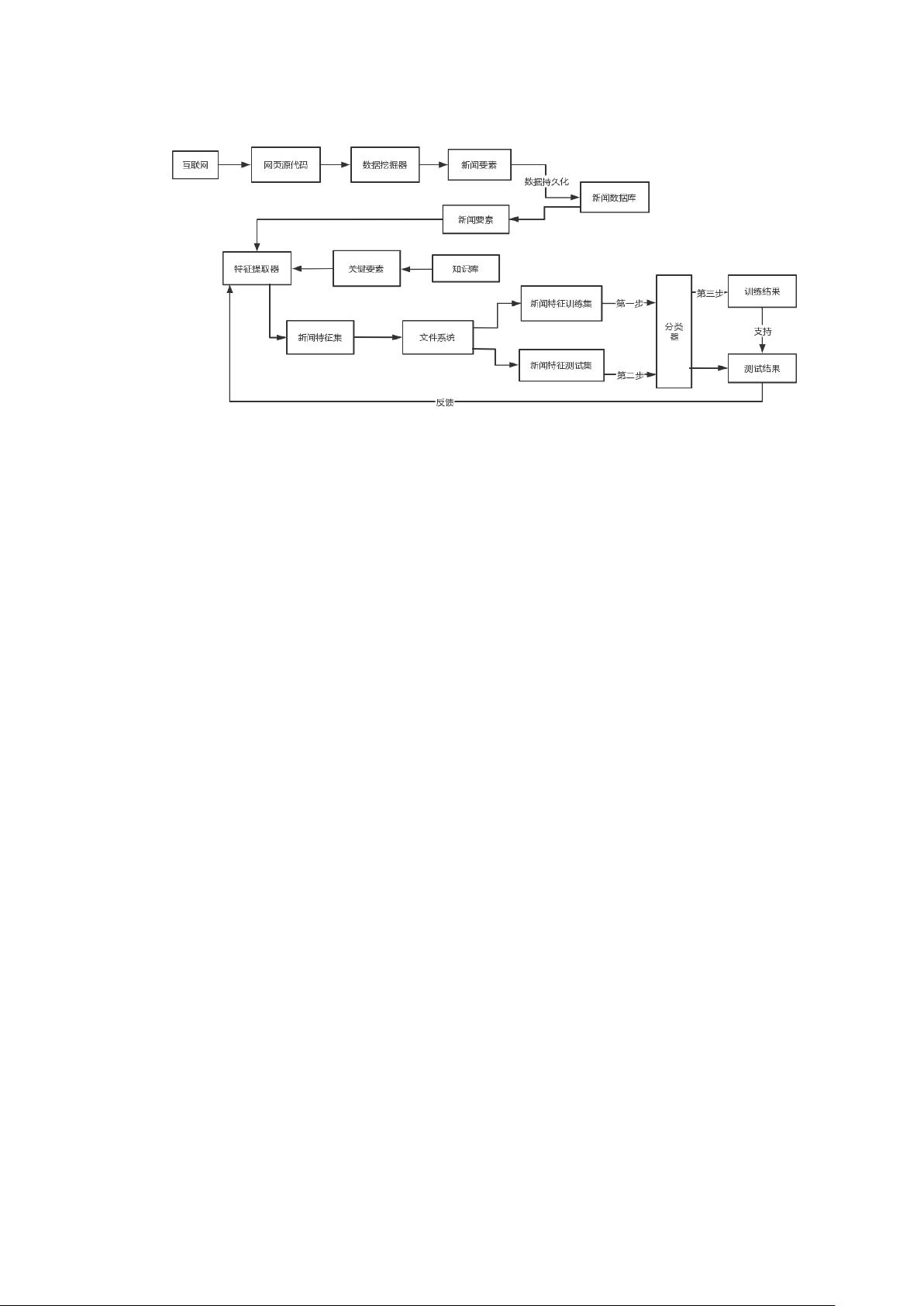
新闻热点预测结构图
根据互联网数据挖掘技术和已有的新闻话题预测模型,得到上图所示的整体
设计结构图。该结构图主要由数据挖掘器、特征提取器以及分类器 3 部分构成。
从第三步训练结果→支持→测试结果→反馈→特征提取器可以看出,该步骤
是一个不断循环的过程,目的在于根据测试结果不断调整特征值,直到达到满意
的效果。
由于步骤模块化,该结构设计可应对多种不同需求的话题预测,支持不同新
闻网站、不同类别下新闻预测以及热点或非热点的新闻话题预测。
(2)特征提取
关键词模式匹配技术简介
模式(Schema)是指按照某种结构组织起来的多个元素的集合,模式匹配是
指将两个模式作为输入,计算模式元素之间语义上的对应关系的过程
[7]
。本文
中特征向量中的两个元素——知名度和敏感度,需要计算新闻文章中出现的名人
数或敏感词的个数,为了实现这一计算,故选用模式匹配技术。由于热点话题的
特点,在新闻话题预测中不需要找出具体匹配位置。
2.1 知名度。
建立名人库
[8]
,匹配新闻,若出现词库中人名则该特征记为 1,否则记为
0。
famous=0(初始值)(1)
2.2 敏感度。
建立敏感词词库(如 explosion,death 等),新闻标题及内容中出现的敏
感词次数记为 a,敏感词库总次数为 b,定义敏感度为 a/b(0-1)。
Sensitivity=a/b(2)
2.3 文本长度。
新闻正文长度过长或过短都会影响其热度,首先设定该长度阈值为 500,该
值根据实验测试结果不断调整。
Length=500(初始值)(3)
2.4 时效性。
当前时间与发表时间求差,差值 x 以 24 为阈值。
2.5 生动性。
统计一篇新闻的形容词个数 m 占整篇新闻词数 n 的比例(0~1),比例高者
权重高,新闻话题热度更高。
Vivid=m/n(5)
(3)分类器问题
3.1 支持向量机技术简介
支持向量机(Support Vector Machine)是 Cortes 和 Vapnik 于 1995 年首先
提出的,它的原理是寻找一个最优的分类超平面,在保证精度的同时能够使平面
两侧的空白做到最大化,所以理论上来说支持向量机可以实现线性数据的最优分
类
[9]
。上文提到的特征向量就是一组可分的线性数据,故选用支持向量机技术。
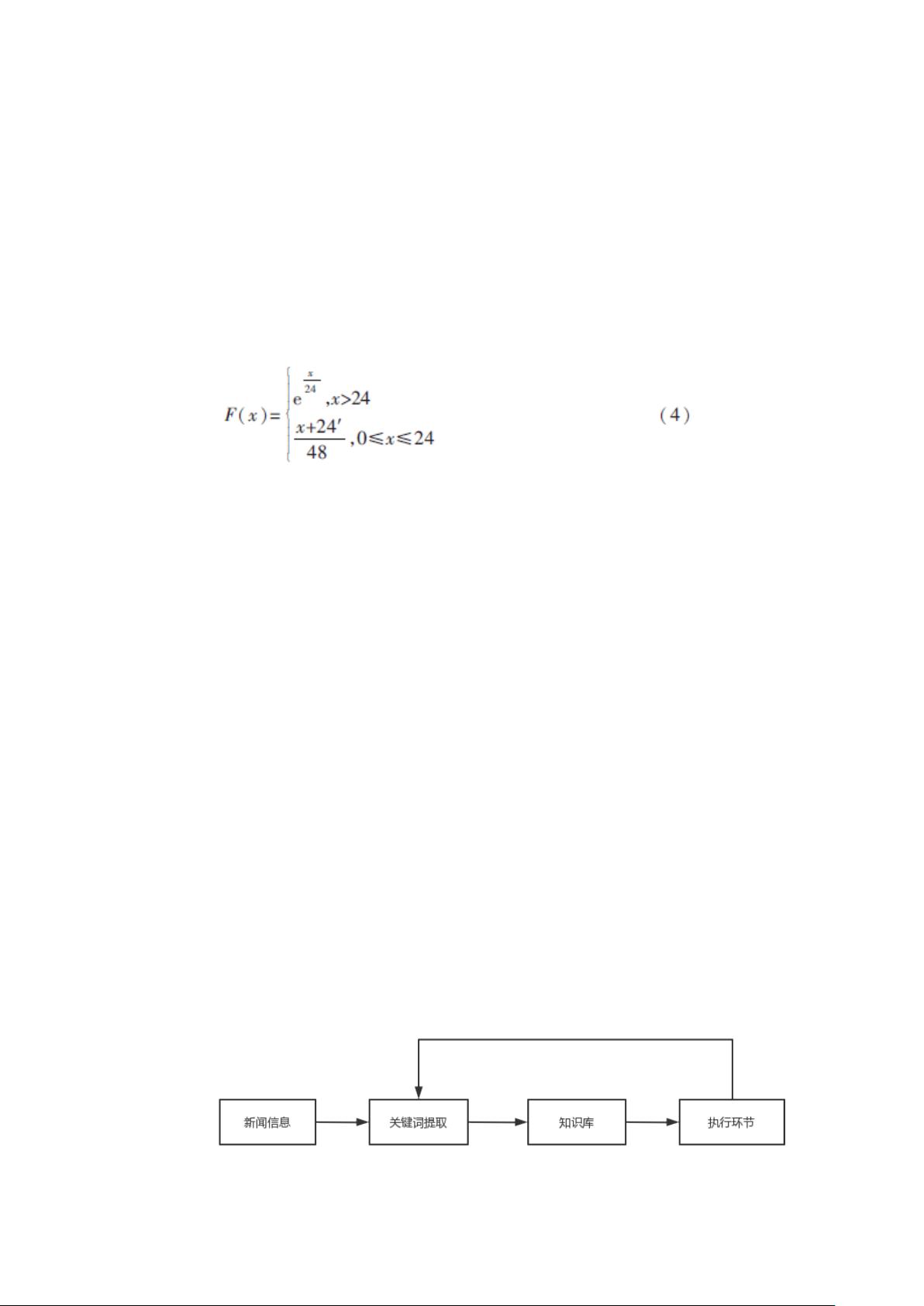
3.2 机器学习技术简介
机器学习就是让机器来模拟人类的学习功能,是一门研究怎样用机器来模拟
或实现人类学习活动的学科,要使计算机具有某种学习能力,就需要为其建立相
应的学习系统。本文背景下的学习系统基本模型如图 2 所示。













