正则表达式是一种用来进行字符串匹配的工具,它利用一套特定的规则和符号,描述字符串的构成和匹配模式。正则表达式被广泛应用于文本处理、数据验证、搜索替换等多个领域,是处理字符串的强大武器。本文将介绍正则表达式的基本原理、语法、构造方式以及如何编写高效的正则表达式。
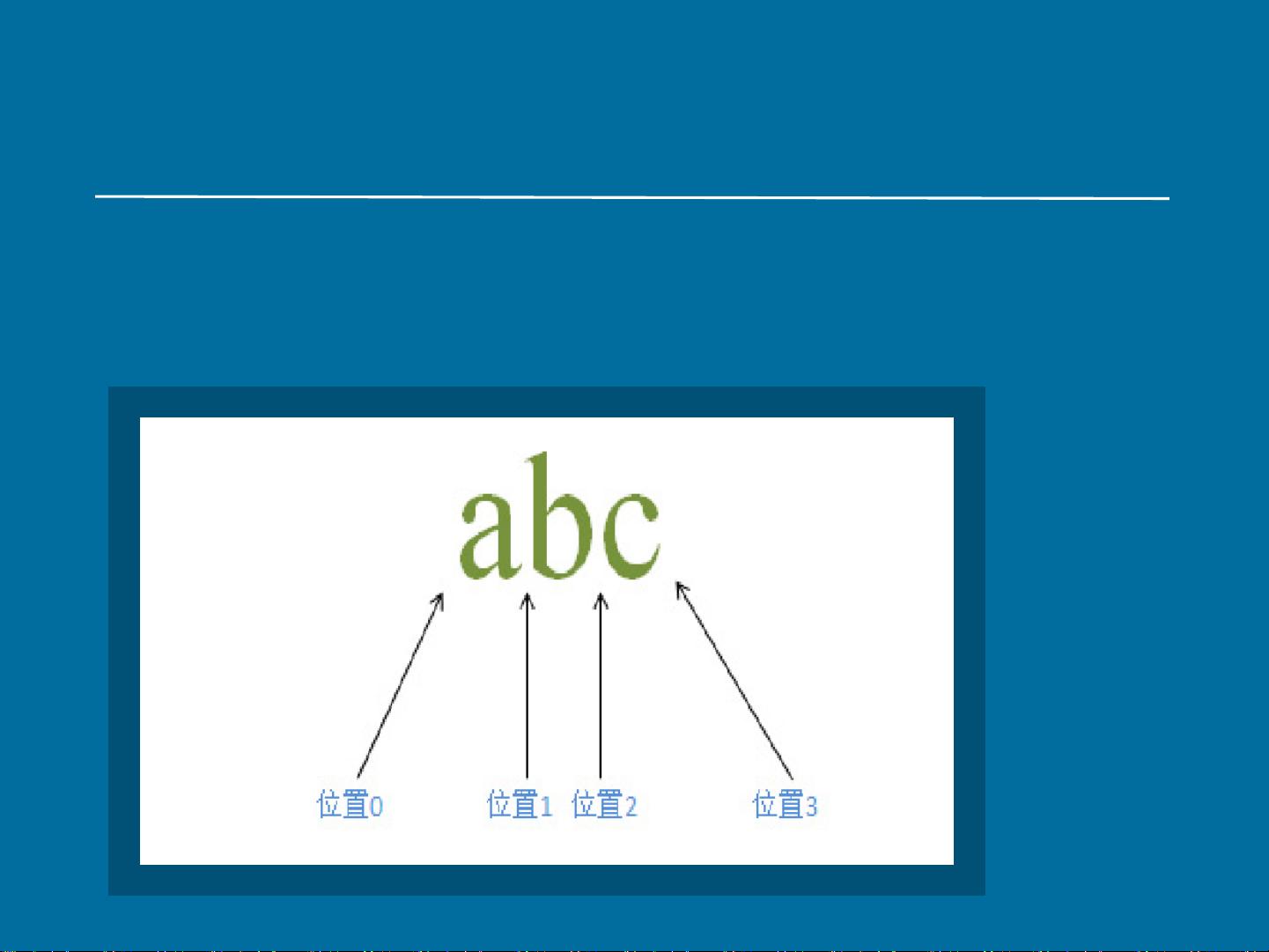
在正则表达式中,字符串由一系列字符组成,每个字符占据特定的位置。正则表达式不仅匹配字符,还可能匹配字符之间的位置。一个重要的概念是“占有字符”,它匹配并消耗字符内容,返回匹配结果;与之相对的是“零宽度匹配”,它匹配位置而不消耗字符,不返回实际的字符内容。正则表达式在匹配时,是从字符串的某个位置开始,一个子表达式匹配成功后,下一个子表达式从该结束位置继续匹配,这个过程称为控制权和传动。
正则表达式包含多种元素,如字符与字符集、元字符、限定符、分组、反向引用、分支条件OR、条件判断、环视、注释、贪婪和懒惰匹配、回溯、固化分组等。以下是这些元素的详细解释:
字符与字符集:一般字符匹配自身,如abc中的a、b、c。字符集则是匹配集合中的任意字符,例如[a-z]匹配任意一个小写字母,而[^abc]则匹配除了a、b、c之外的所有字符。
元字符:是一些具有特殊意义的字符,例如^匹配字符串的开始,$匹配字符串的结束,.匹配除换行符以外的任意字符,\w匹配字母、数字、下划线或中文字符,\d匹配数字,\s匹配空白字符等。取反操作可以使用大写的元字符,如\W匹配非字母数字字符。
限定符:用来指定字符或者字符组出现的次数,如*表示零次或多次,+表示一次或多次,?表示零次或一次,{n}表示恰好n次,{n,}表示至少n次,{n,m}表示至少n次且不超过m次。
分组:通过括号()来定义,分组可以用来捕获匹配的内容,也可以用来应用限定符到多个字符。分组还有命名功能,即(?<name>...),这样可以通过名字引用匹配的组内容。
反向引用:在正则表达式中可以引用前面已经定义的分组,例如(\d)\1匹配两个连续的相同数字。
分支条件OR:使用|表示“或”,用来匹配多个可能的表达式中的任意一个,例如abc|def匹配abc或def。
条件判断:正则表达式可以包含条件判断逻辑,例如(?(id/name)yes|no)用来判断某个组是否匹配。
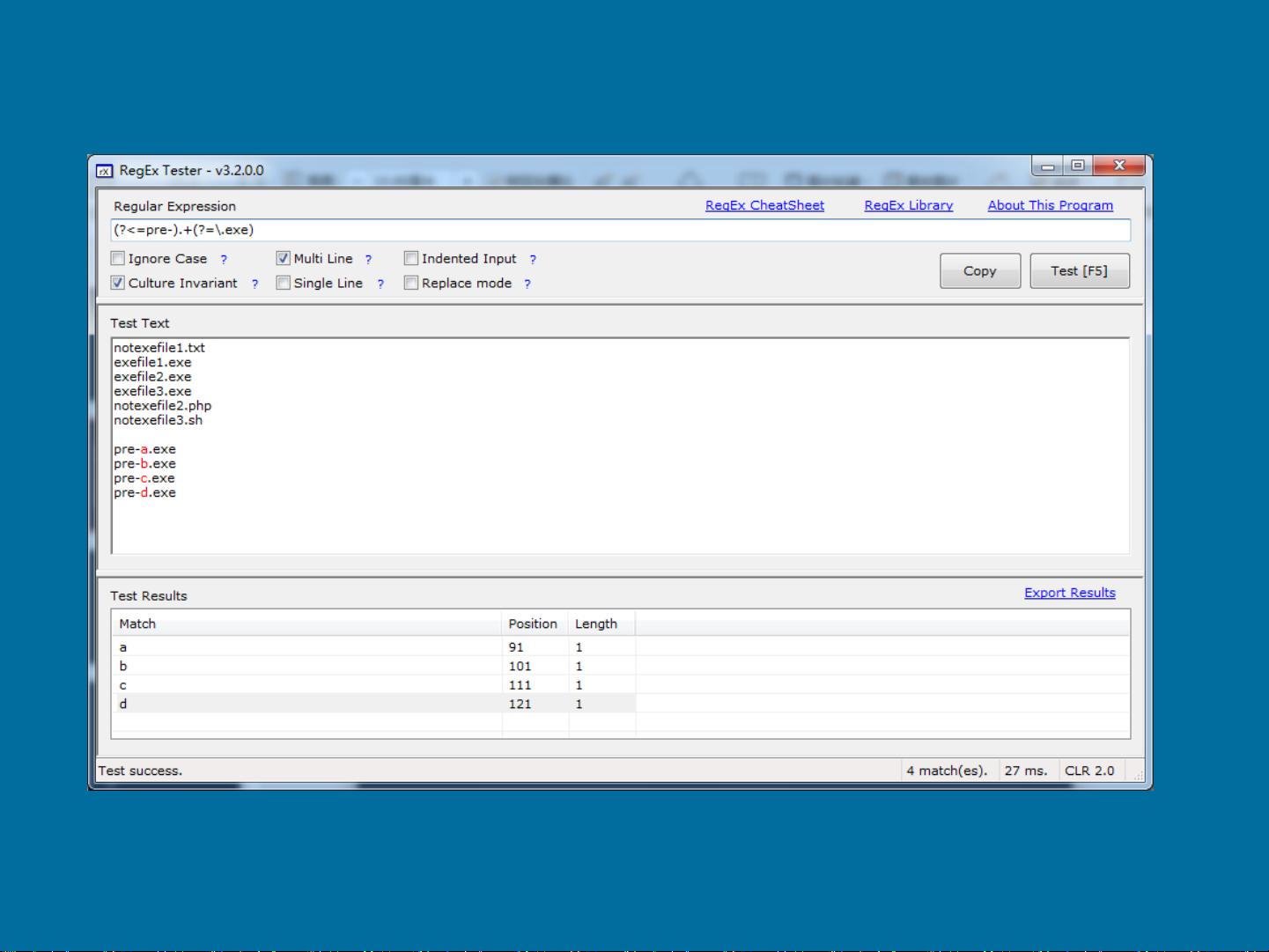
环视:它匹配一个位置,不消耗字符,包括正向前瞻(?(?=[a-z])[a-z0-9]+)和负向前瞻(?(?![a-z])[a-z0-9]+)。这些构造使得正则表达式可以匹配位于某个上下文中的字符串。
注释:在正则表达式中添加注释可以提高代码的可读性,例如(?#comment)。
贪婪和懒惰匹配:默认情况下,限定符是贪婪的,尽可能多地匹配字符;懒惰匹配则是尽可能少地匹配字符,通过在限定符后加?变为懒惰模式,如*?、+?。
回溯:正则表达式匹配过程中,如果匹配失败,引擎会回溯到上一个状态,尝试其他的匹配路径,直到找到匹配或失败为止。
固化分组:这是一个较高级的特性,用来防止回溯影响匹配效率,例如(?>[abc]+)。
编写高效的正则表达式需要注意几个方面:合理使用限定符、避免不必要的回溯、尽可能简化表达式、使用非捕获分组减少资源消耗、在必要时使用条件判断等。此外,利用工具测试和调试正则表达式也非常重要,这里推荐两个工具:regextester和regex101,它们能够帮助我们检验正则表达式的效果,并提供调试信息。
在理解和掌握了上述正则表达式的知识点后,我们可以编写出既能正确匹配目标字符串,又能尽可能减少计算资源消耗的高效正则表达式。由于内容量庞大,这里不再列举所有知识点的示例。读者可以在实践中不断应用这些知识,提高处理字符串问题的技能。