Hadoop任务调度器是Hadoop分布式计算框架中的核心组件之一,负责管理和分配集群资源,以实现任务的高效执行。Hadoop的作业调度过程可以划分为几个主要阶段,这些阶段涉及到从作业提交到任务分配的各个环节。下面详细介绍Hadoop任务调度器的基础知识。
Hadoop调度流程可以概括为以下几个主要步骤:
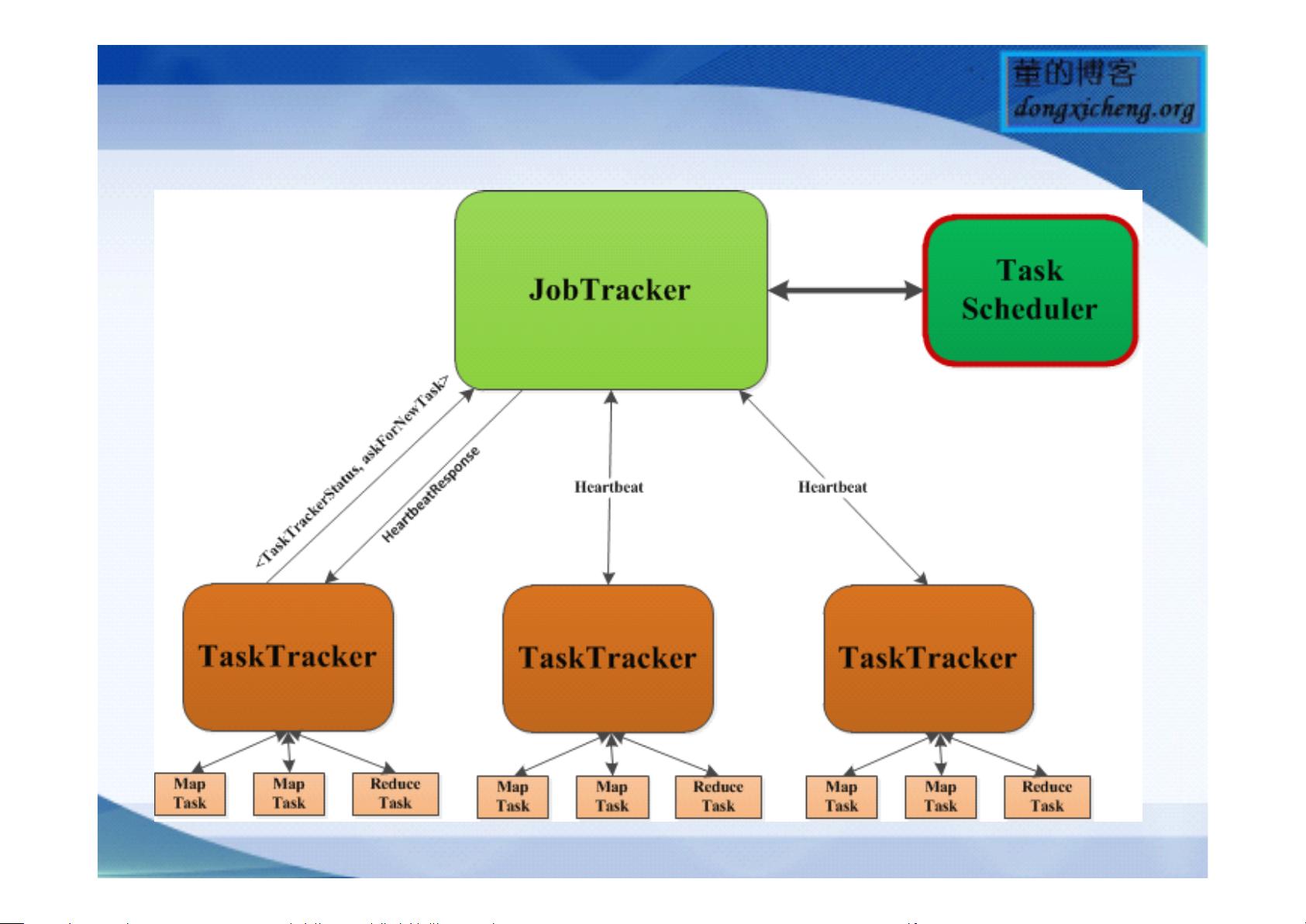
1. 客户端提交作业给JobTracker。
2. JobTracker接收作业并初始化。
3. JobTracker通过TaskScheduler进行任务调度。
4. TaskTracker周期性地通过heartbeat向JobTracker报告自身状态和任务状态。
5. JobTracker根据调度策略决定哪些任务分配给哪些TaskTracker。
6. TaskTracker接收到新任务后,开始执行任务并反馈执行结果。
7. 任务完成或者失败,作业执行完毕。
Hadoop自带的调度器主要有三种:
1. FIFO批处理调度器:按照作业提交顺序调度执行任务,先提交的作业先执行。这种方式最简单,但是不支持多用户之间的资源共享。
2. CapacityScheduler多用户调度器:允许设置多个队列,每个队列可以有最大容量限制。资源是按照队列优先级划分的,一个队列的任务可以使用其他队列的空闲资源,适合于多用户共享集群的场景。
3. FairScheduler多用户调度器:它提供了更为公平的资源共享,通过动态调整每个用户或应用程序所得到的资源比例,使所有作业都能获得公平的资源分配,特别适合于共享环境下的作业调度。
Hadoop调度器的功能还包括了slot资源的划分和管理。Slot是Hadoop集群中资源分配的基本单位,分为mapslot和reduceslot两种。一个TaskTracker可以有多个mapslot和reduceslot,具体数量由参数mapred.tasktracker.[map|reduce].tasks.maximum配置。这些slot资源被调度器用来分配给不同作业中的任务。
Hadoop的三级调度策略包括:队列、作业和任务三个层面的调度。集群中的资源首先按照队列进行划分,每个队列会分配一定的资源量;然后,作业被分配到队列中,作业的执行顺序考虑作业的提交时间、优先级等因素;任务层面的调度则根据任务的本地性原则(node locality 和 rack locality)进行。
在Hadoop的作业描述方式中,作业被抽象为三层多叉树结构,依次选择一个队列、作业和任务。每个作业包含若干个任务,任务是实际运行的实体,任务执行时又分为不同的尝试(Attempt),包括正常的尝试、重试尝试以及推测执行的尝试。
如果要编写自己的Hadoop调度器,需要深入了解Hadoop调度器的接口和扩展机制。开发者可以继承原有的调度器类,重写其调度逻辑,或者添加新的调度策略和规则。在Hadoop社区,编写自定义调度器是一个较为高级的开发任务,通常需要对Hadoop内部机制有较深的理解。
总结来说,Hadoop任务调度器是Hadoop集群高效运行的关键。通过调度器,可以将集群资源合理地分配给不同的作业和任务,以达到快速、公平、高效的集群计算目标。了解和掌握调度器的工作原理和扩展方法对于系统管理员和开发者来说是必不可少的技能。