




Finding the best compromise in compiling compound loops to Verilog
Yosi Ben-Asher
*
, Nadav Rotem, Eddie Shochat
Computer Sci. Dep. Haifa University, Haifa, Israel
article info
Article history:
Received 31 March 2009
Received in revised form 28 June 2010
Accepted 2 July 2010
Available online 18 July 2010
Keywords:
High-level synthesis
FPGA
Compilation
abstract
In this work we consider a special optimization problem involved with compiling compound loops (com-
bining nested and consecutive sub-loops) to Verilog. Each sub-loop of the compound loop may require a
different optimized hardware configuration (OHC) for optimized executio n times. For example, one loop
requires at least two memory ports and one multiplier for an optimized execution time, while another
loop may require only one memory port but two multipliers, yet one OHC should be selected for both
loops. The goal is to compute a minimal OHC which, based on the different heat levels (expected number
of iterations) of the sub-loops, is a good compromise between all the conflicting requirements of each
sub-loop. Though synthesis of nested loops has been implemented in quite a few systems this aspect
has not been considered so far. We avoid the use of time consuming integer linear programming (ILP)
techniques and instead use a fast space exploration technique combined with an efficient variant of list
scheduling.
Another novel aspect of the proposed system is the observation that the real latencies of the hardware
units should be considered as variables of the OHC rather than fixed real values as is usually done in high-
level synthesis systems. Experimental results show a significant improvement in the OHC without a sig-
nificant increase in the execution time due to the use of this search procedure.
1
Ó 2010 Published by Elsevier B.V.
1. Introduction
Embedded systems are characterized by extensive loop process-
ing and low power budget. In many cases these loops can be com-
piled to hardware circuits that are significantly faster and more
power efficient than their software versions. Automating this pro-
cess is a fundamental problem in high-level synthesis (HLS) [13].
Synthesizing code to circuits is done in the scheduling phase of a
compiler wherein the operations in the code are scheduled to a
time hardware
resources 2D table without violating data depen-
dencies in the code. Each row in the 2D table determines the clock
cycle wherein the operations in that row will be executed. We re-
mark that the main difference between scheduling to hardware
and scheduling to a CPU is that when compiling to hardware, we
have the freedom to select the target architecture, namely the re-
sources that can be used in each clock cycle. In particular we can
generate circuits with multiple parallel memory references that
are started in the same clock cycle. There is also a freedom to chose
the partition of the schedule (the 2D table) to clock cycles (see [27]
for a detailed survey on scheduling issues in HLS).
For a given loop L
i
let toptðL
i
Þ be the latency (number of clock
cycles) of a circuit obtained by scheduling L
i
’s operations using
some known scheduling algorithm (List scheduling in our case)
with unlimited amount of resources. By the term ‘‘latency” we re-
fer to the number of clock cycles it takes for the synthesized circuit
to complete one iteration of the loop. The execution time of an iter-
ation is obtained by multiplying the latency by the clock rate.
2
An
optimized hardware configuration (OHC) of L
i
is the minimal amount
of resources for which list scheduling (LS) of L
i
will produce a circuit
C
i
¼ LSðL
i
; OHCÞ whose latency is ‘‘close enough” to toptðL
i
Þ. The term
‘‘close enough” indicates that the latency of C
i
is greater than toptðL
i
Þ
by no more that some small fraction, e.g., tðC
i
Þ < 1:2 toptðL
i
Þ. While
finding an OHC of a single loop can be done by an exhaustive search,
finding an OHC for a set of loops L
1
; ...; L
k
is problematic since each L
i
can have a different and possibly conflicting OHC. Note that we as-
sume that these set of loops is part of the same program and hence
must be executed using the same set of resources (at least partially,
share resources). Clearly if we select a common OHC which is the un-
ion of all the resources needed by each L
i
to achieve toptðL
i
Þ then all
loops will achieve their optimal latencies. However, this might be
too wasteful as there might be another common OHC that minimize
the use of resources without damaging the overall performances
significantly.
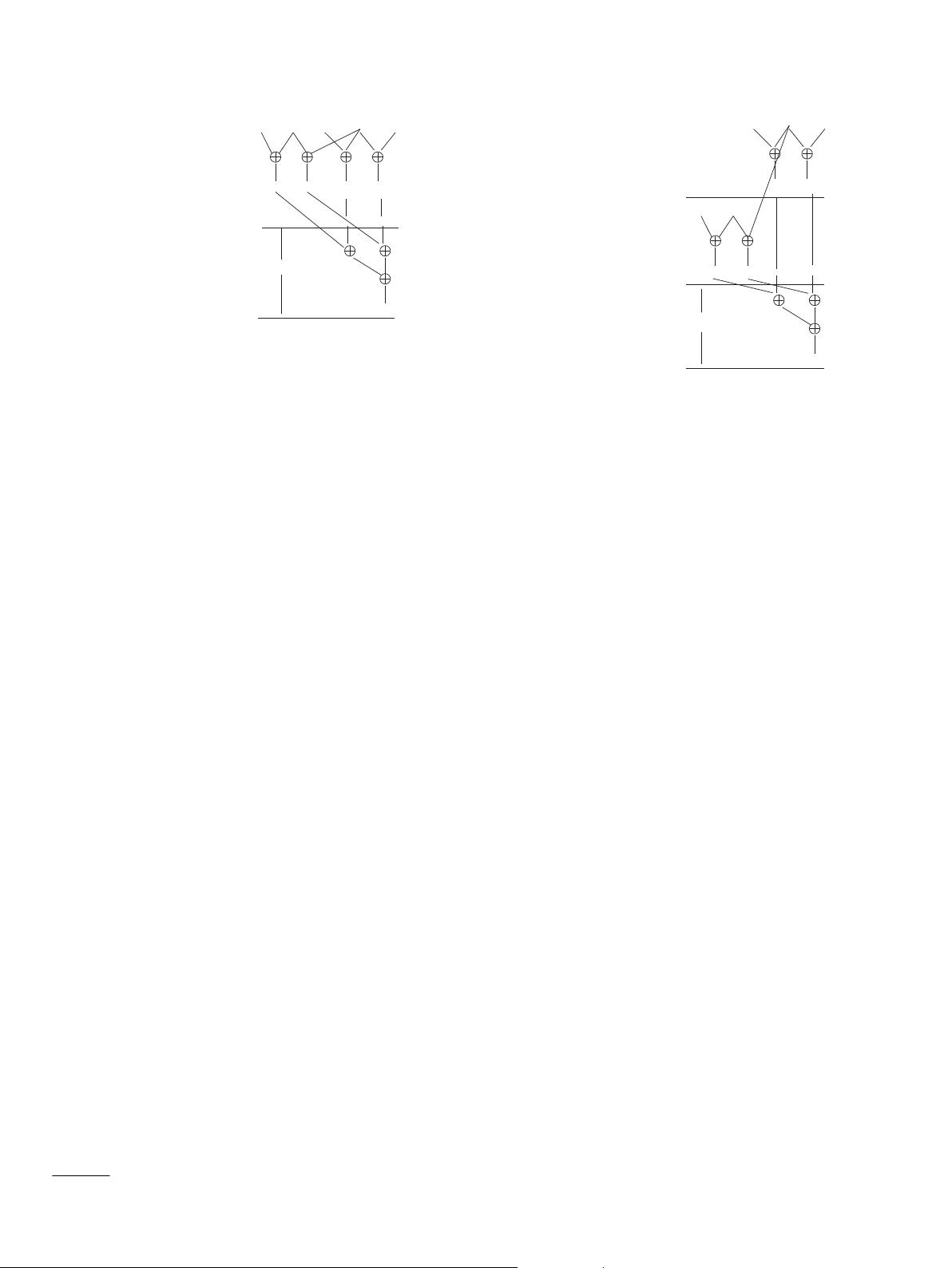
Fig. 1 depicts the synthesis (optimal scheduling) of two
consecutive loops. Each operation is described by a rectangle box
1383-7621/$ - see front matter Ó 2010 Published by Elsevier B.V.
doi:10.1016/j.sysarc.2010.07.001
* Corresponding author.
E-mail address: yosi@cs.haifa.ac.il (Y. Ben-Asher).
1
An early short version of this work appeared in ISVLSI-2008.
2
Sometimes, when the clock rate is regarded as 1 time unit, the execution time
corresponds to the latency.
Journal of Systems Architecture 56 (2010) 474–486
Contents lists available at ScienceDirect
Journal of Systems Architecture
journal homepage: www.elsevier.com/locate/sysarc















- 1
- 2
- 3
前往页