Kafka 万亿级消息实践之资源组流量掉零故障排查分析.doc
版权申诉
98 浏览量
2022-07-09
23:01:19
上传
评论
收藏 885KB DOC 举报

Kafka 万亿级消息实践之资源组流量掉零故障排查分析
本篇对在 kafak 万亿消息实践中一次典型的故障进行详细分析和说明。深入到 kafka
架构原理层分析故障出现的根因及对应的解决方案。
笔者:vivo 互联网服务器团队-Luo Mingbo
一、Kafka 集群部署架构
为了让读者能与小编在后续的问题分析中有更好的共鸣,小编先与各位读者朋友对齐一下
我们 Kafka 集群的部署架构及服务接入 Kafka 集群的流程。
为了避免超大集群我们按照业务维度将整个每天负责十万亿级消息的 Kafka 集群拆分成
了多个 Kafka 集群。拆分粒度太粗会导致单一集群过大,容易由于流量突变、资源隔离、
限速等原因导致集群稳定性和可用性受到影响,拆分粒度太细又会因为集群太多不易维护,
集群内资源较少应对突发情况的抗风险能力较弱。
由于 Kafka 数据存储和服务在同一节点上导致集群扩缩容周期较长,遇到突发流量时不
能快速实现集群扩容扛住业务压力,因此我们按照业务维度和数据的重要程度及是否影响商
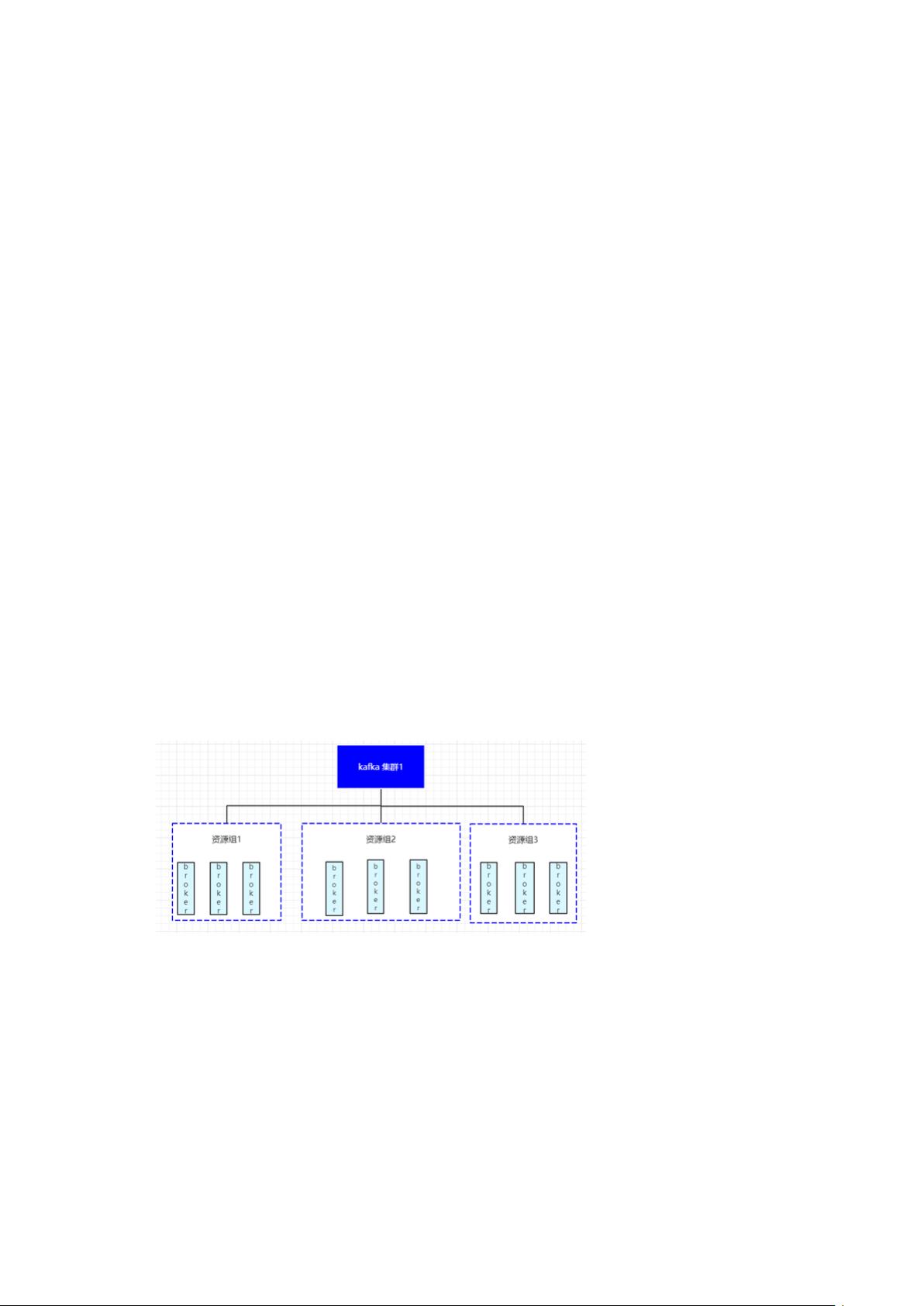
业化等维度进行 Kafka 集群的拆分,同时在 Kafka 集群内添加一层逻辑概念“资源组”,资
源组内的 Node 节点共享,资源组与资源组之间的节点资源相互隔离,确保故障发生时不
会带来雪崩效应。
二、业务接入 Kafka 集群流程
在 Kafka 平台注册业务项目。
若项目的业务数据较为重要或直接影响商业化,用户需申请创建项目独立的资源组,若项
目数据量较小且对数据的完整性要求不那么高可以直接使用集群提供的公共资源组无需申
资源评论













