Kafka 负载均衡在 vivo 的落地实践.doc
版权申诉
88 浏览量
2022-07-08
23:02:50
上传
评论
收藏 2.92MB DOC 举报


Kafka 负载均衡在 vivo 的落地实践
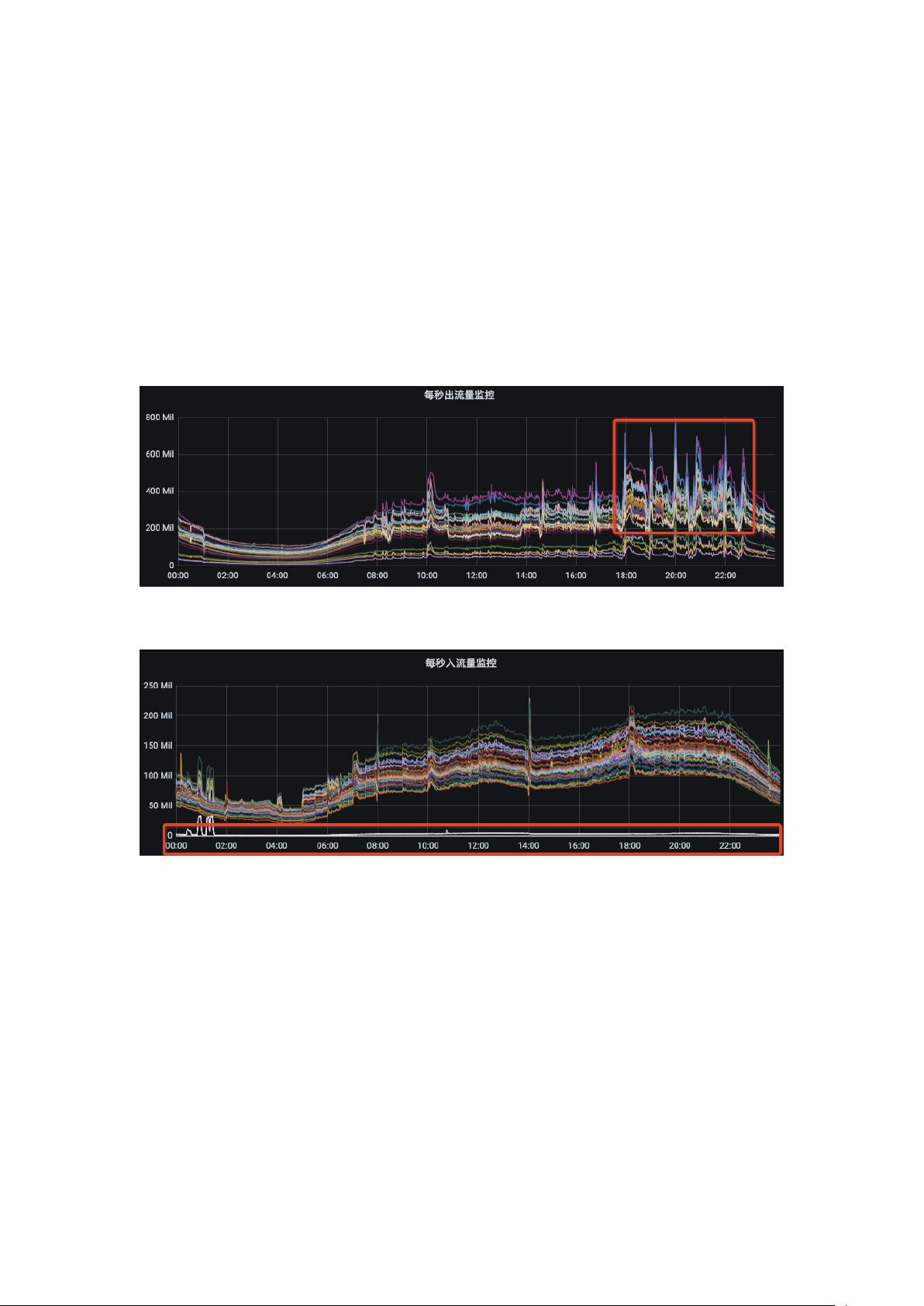
副本迁移是 Kafka 最高频的操作,对于一个拥有几十万个副本的集群,通过人工
去完成副本迁移是一件很困难的事情。Cruise Control 作为 Kafka 的运维工具,它包含了
Kafka 服务上下线、集群内负载均衡、副本扩缩容、副本缺失修复以及节点降级等功能。
vivo 互联网服务器团队-You Shuo
副本迁移是 Kafka 最高频的操作,对于一个拥有几十万个副本的集群,通过人工去完成副
本迁移是一件很困难的事情。Cruise Control 作为 Kafka 的运维工具,它包含了 Kafka 服务
上下线、集群内负载均衡、副本扩缩容、副本缺失修复以及节点降级等功能。显然,Cruise
Control 的出现,使得我们能够更容易的运维大规模 Kafka 集群。
备注:本文基于 Kafka 2.1.1 开展。
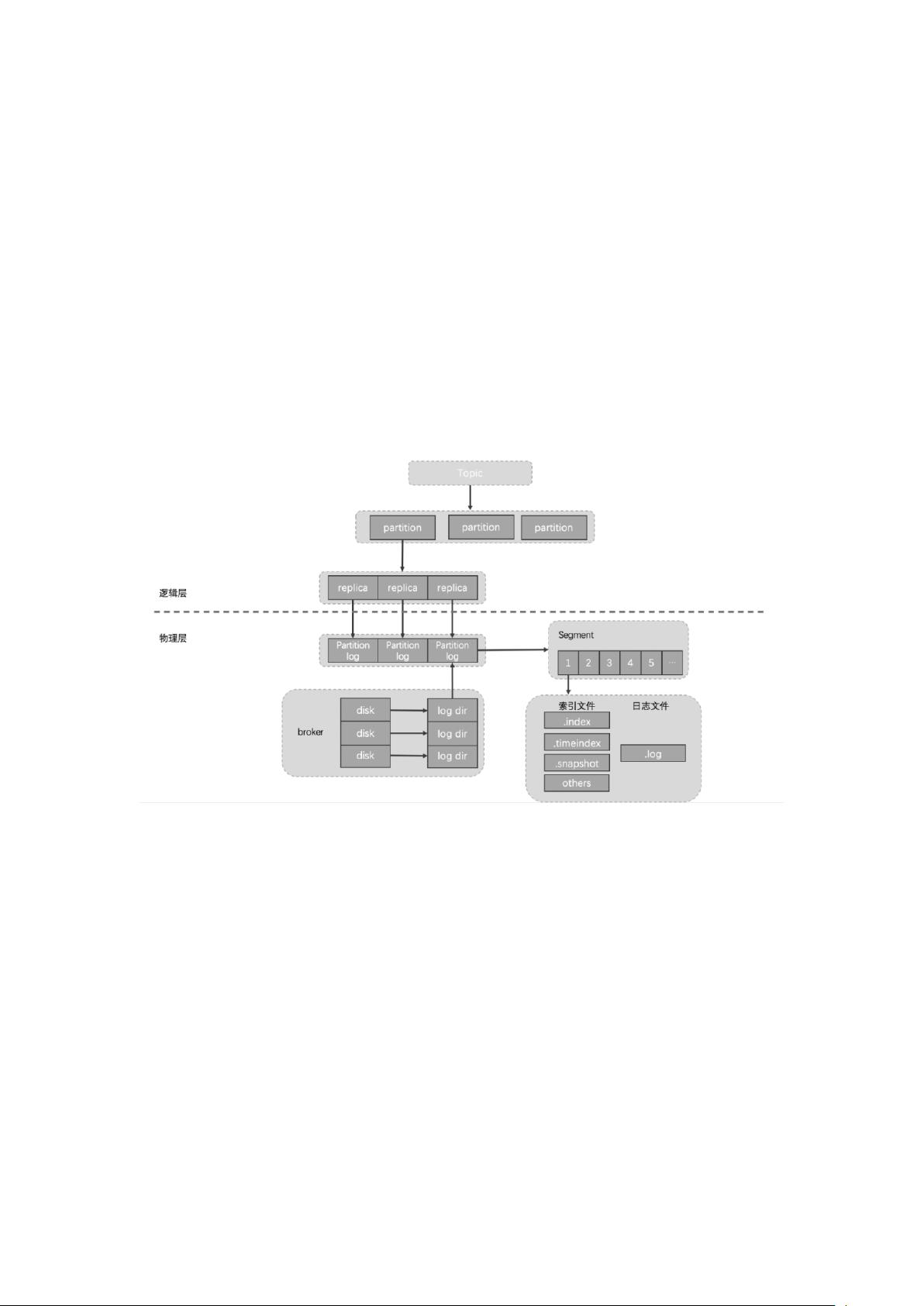
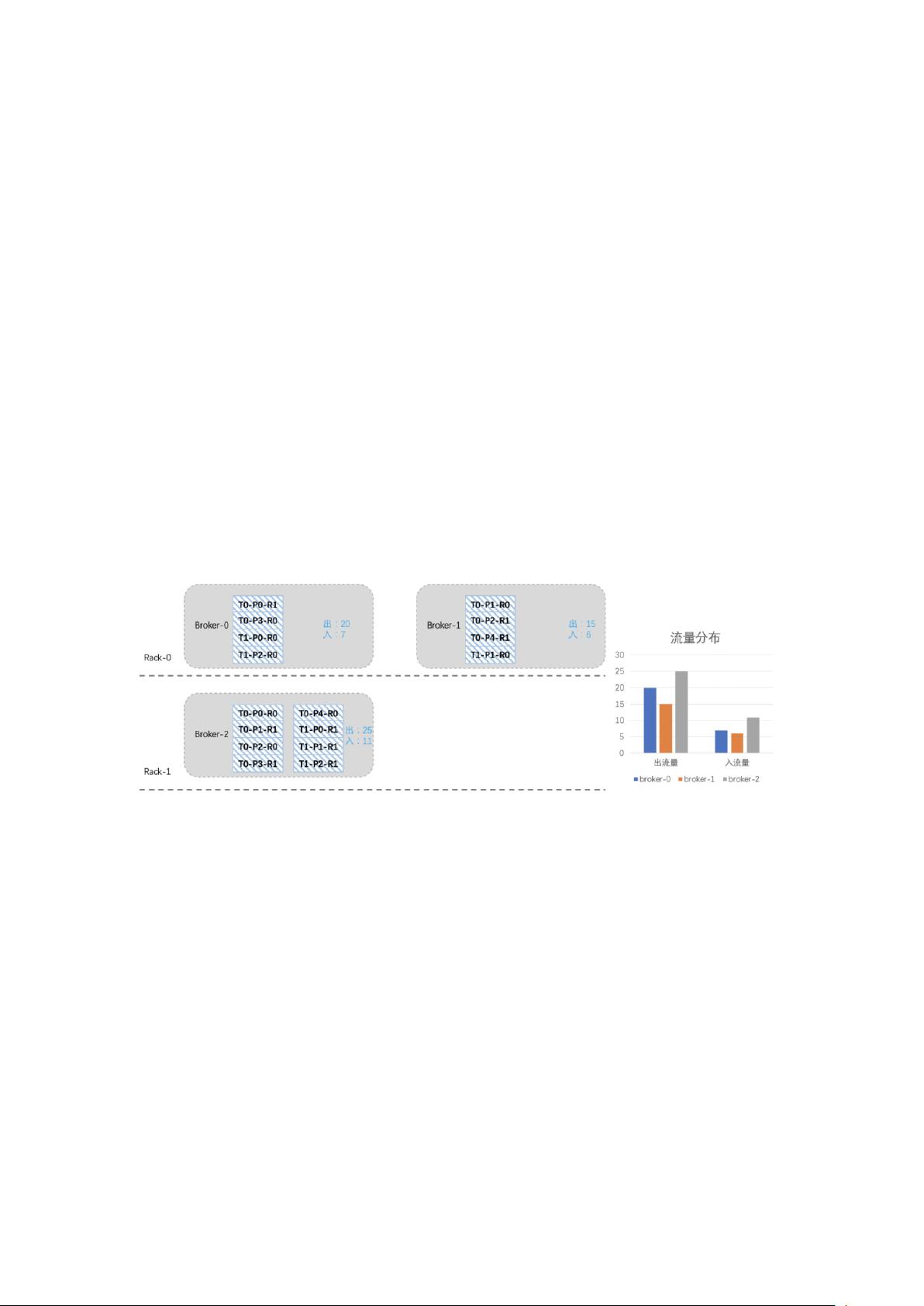
一、 Kafka 负载均衡
1.1 生产者负载均衡
Kafka 客户端可以使用分区器依据消息的 key 计算分区,如果在发送消息时未指定 key,
则默认分区器会基于 round robin 算法为每条消息分配分区;
否则会基于 murmur2 哈希算法计算 key 的哈希值,并与分区数取模的到最后的分区编号。
很显然,这并不是我们要讨论的 Kafka 负载均衡,因为生产者负载均衡看起来并不是那么
的复杂。
1.2 消费者负载均衡
考虑到消费者上下线、topic 分区数变更等情况,KafkaConsumer 还需要负责与服务端交
互执行分区再分配操作,以保证消费者能够更加均衡的消费 topic 分区,从而提升消费的性
能;
Kafka 目 前 主 流 的 分 区 分 配 策 略 有 2 种 ( 默 认 是 range , 可 以 通 过
partition.assignment.strategy 参数指定):
range: 在保证均衡的前提下,将连续的分区分配给消费者,对应的实现是 RangeAssignor;
round-robin:在保证均衡的前提下,轮询分配,对应的实现是 RoundRobinAssignor;
0.11.0.0 版本引入了一种新的分区分配策略 StickyAssignor,其优势在于能够保证分区均衡
的前提下尽量保持原有的分区分配结果,从而避免许多冗余的分区分配操作,减少分区再分
剩余15页未读,继续阅读
资源评论













