
2 万字 + 30 张图 | 细聊 MySQL undo log、redo log、binlog 有什么用?
笔者:小林 coding
计算机八股文网站:/
大家好,我是小林。
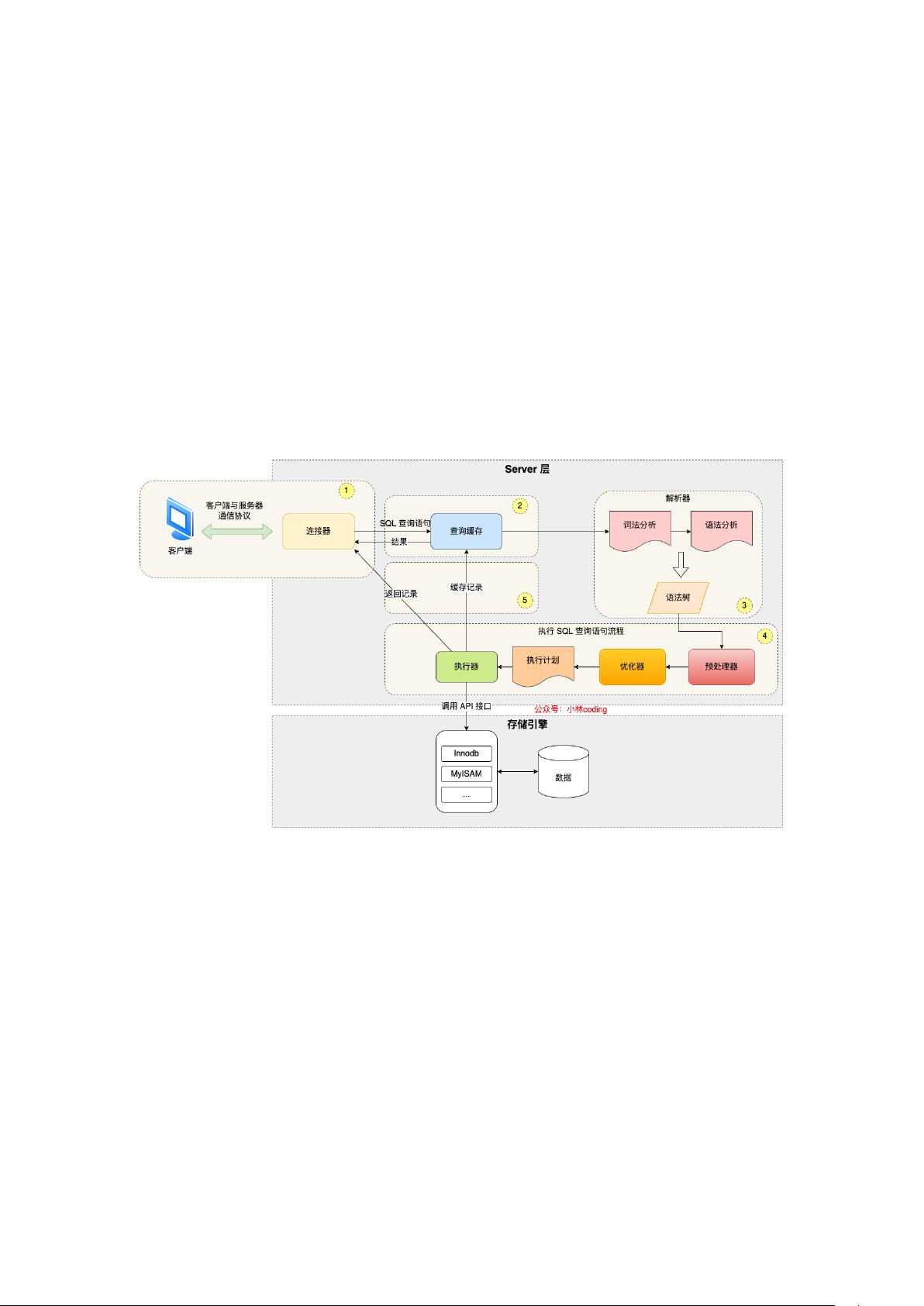
从这篇「执行一条 SQL 查询语句,期间发生了什么?」中,我们知道了一条查询语句经
历的过程,这属于「读」一条记录的过程,如下图:
查询语句执行流程
那么,执行一条 update 语句,期间发生了什么?,比如这一条 update 语句:
UPDATEt_userSETname=‘xiaolin’WHEREid=1;
查询语句的那一套流程,更新语句也是同样会走一遍:
客户端先通过连接器建立连接,连接器自会判断用户身份;
因为这是一条 update 语句,所以不需要经过查询缓存,但是表上有更新语句,是会把整
个表的查询缓存情空的,所以说查询缓存很鸡肋,在 MySQL 8.0 就被移除这个功能了;
解析器会通过词法分析识别出关键字 update,表名等等,构建出语法树,接着还会做语
法分析,判断输入的语句是否符合 MySQL 语法;
预处理器会判断表和字段是否存在;


剩余35页未读,继续阅读













- 1
- 2
前往页