聊聊Netty那些事儿之从内核角度看IO模型.doc
版权申诉
4 浏览量
2022-07-08
15:41:42
上传
评论
收藏 23.06MB DOC 举报


聊聊 Netty 那些事儿之从内核角度看 IO 模型
从内核角度介绍了经常容易混淆的阻塞与非阻塞,同步与异步的概念。以这个作
为铺垫,我们通过一个 C10K 的问题,引出了五种 IO 模型,随后在 IO 多路复用中以技术演
进的形式介绍了 select,poll,epoll 的原理和它们综合的对比。最后我们介绍了两种 IO 线程模
型以及 netty 中的 Reactor 模型。
从今天开始我们来聊聊 Netty 的那些事儿,我们都知道 Netty 是一个高性能异步事件驱动
的网络框架。
它的设计异常优雅简洁,扩展性高,稳定性强。拥有非常详细完整的用户文档。
同时内置了很多非常有用的模块基本上做到了开箱即用,用户只需要编写短短几行代码,
就可以快速构建出一个具有高吞吐,低延时,更少的资源消耗,高性能(非必要的内存拷贝
最小化)等特征的高并发网络应用程序。
本文我们来探讨下支持 Netty 具有高吞吐,低延时特征的基石----netty 的网络 IO 模型。
由 Netty 的网络 IO 模型开始,我们来正式揭开本系列 Netty 源码解析的序幕:
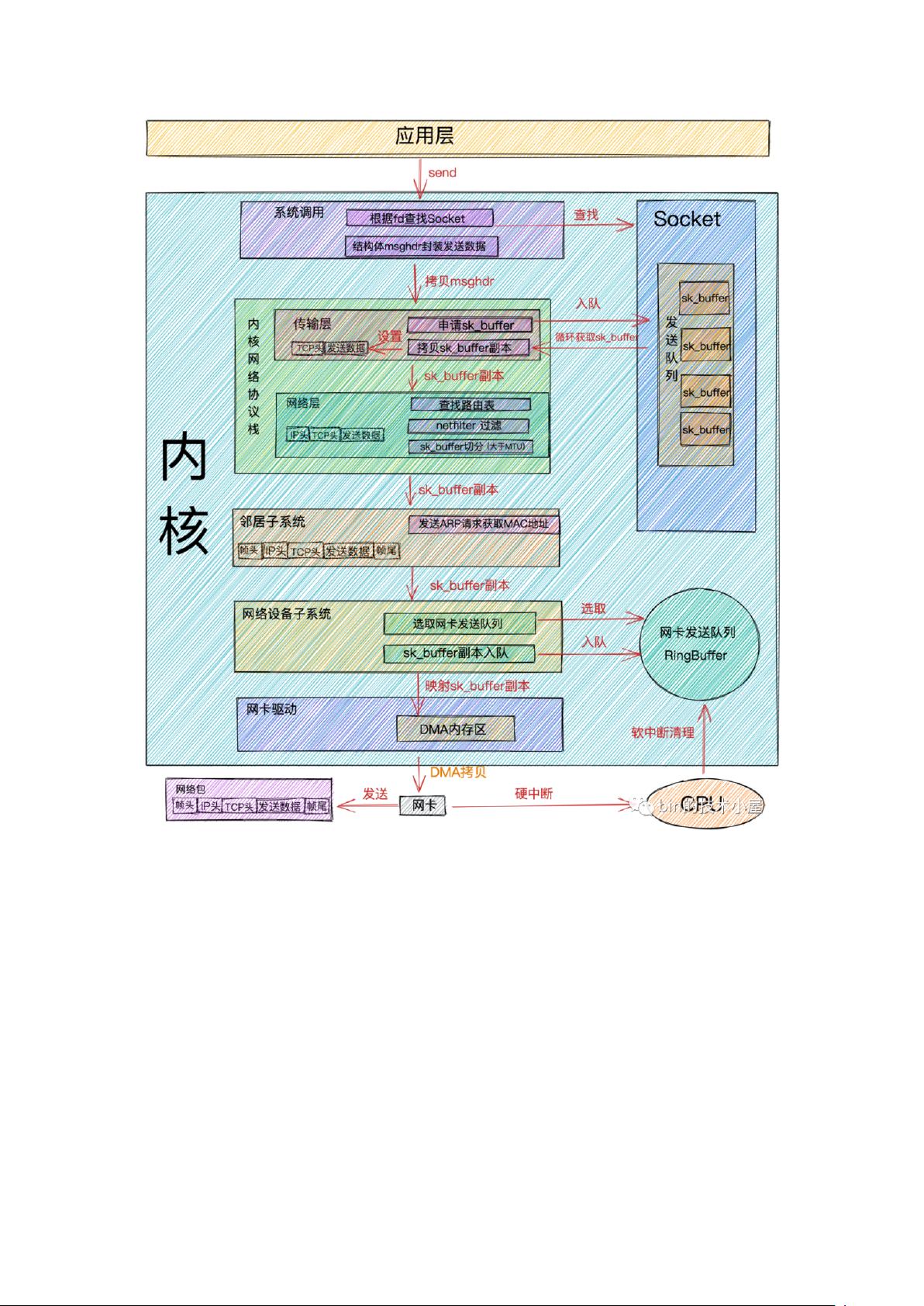
网络包接收流程



剩余54页未读,继续阅读
资源评论













