

本节内容
王道考研/CSKAOYAN.COM
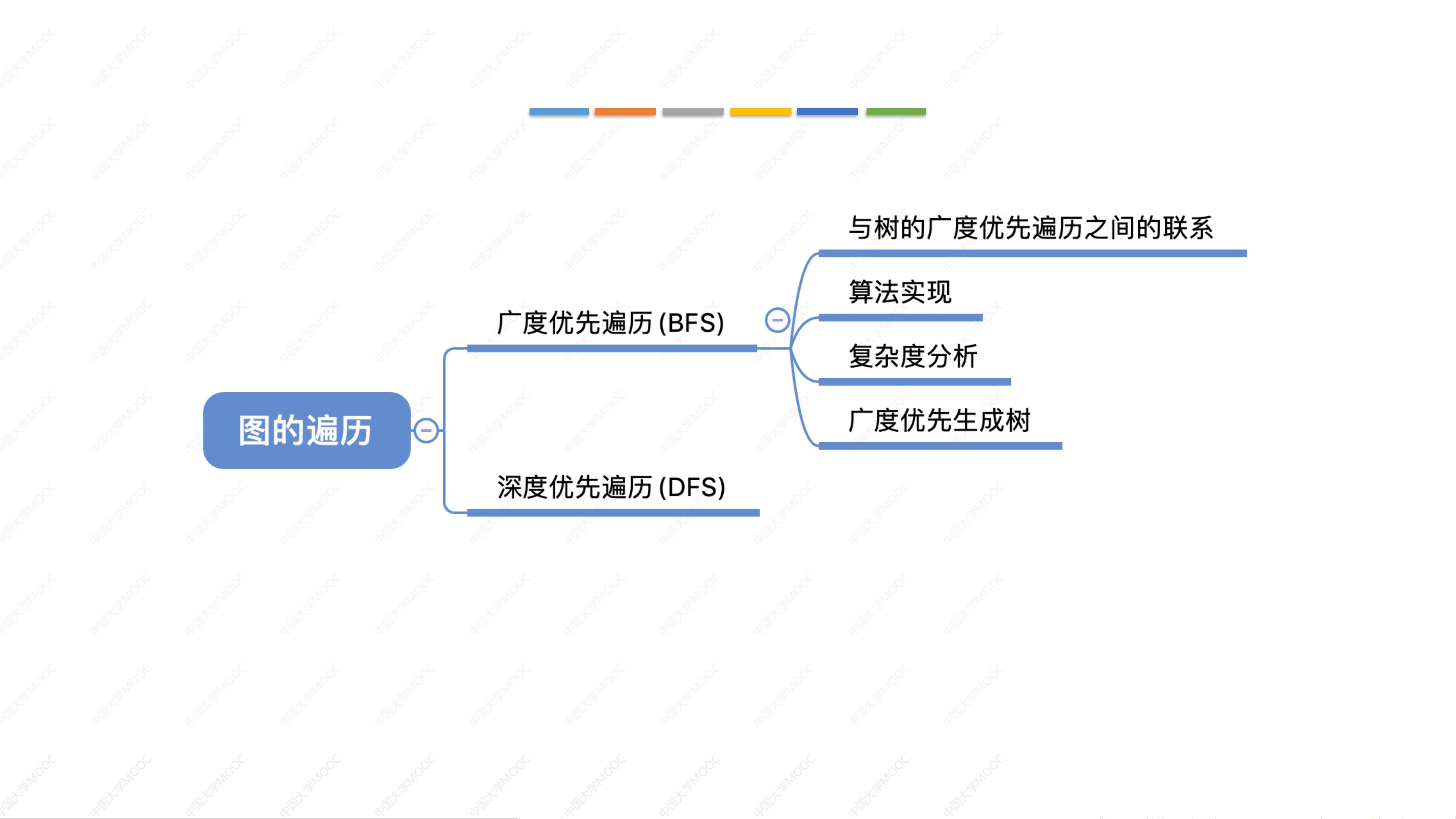
图的遍历
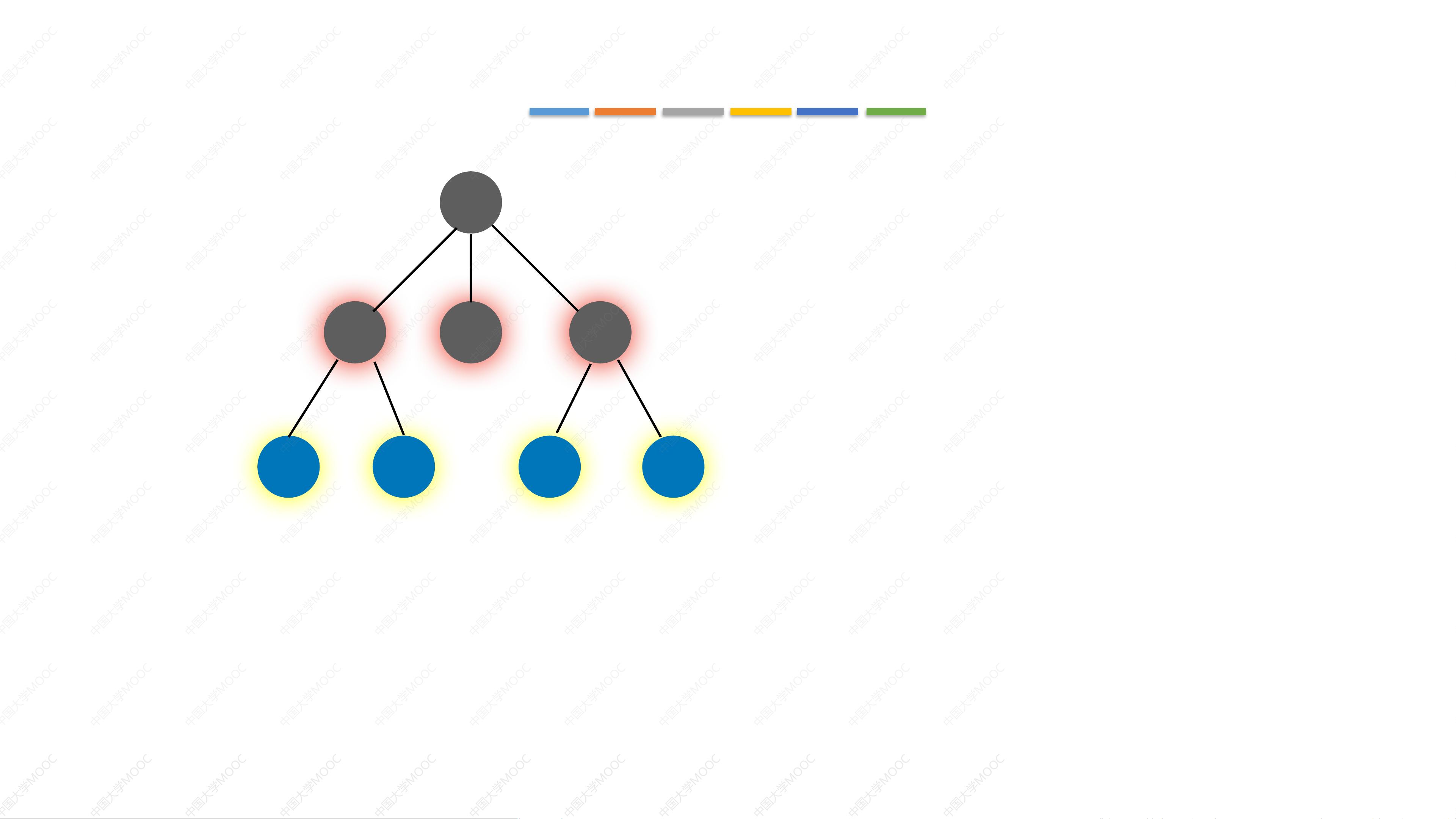
BFS
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
剩余43页未读,继续阅读
资源评论


心碎烤肠
- 粉丝: 1866
- 资源: 67









最新资源
- 基于Java的语音识别系统设计源码
- 基于Java和HTML的yang_home766个人主页设计源码
- 基于Java与前端技术的全国实时疫情信息网站设计源码
- 基于鸿蒙系统的HarmonyHttpClient设计源码,纯Java实现类似OkHttp的HttpNet框架与优雅的Retrofit注解解析
- 基于HTML和JavaScript的廖振宇图书馆前端设计源码
- 基于Java的Android开发工具集合源码
- 通过 DirectX 12 Hook (kiero) 实现通用 ImGui.zip
- 基于Java开发的YY网盘个人网盘设计源码
- 通过 DirectX 11 基于 GPU 调整图像大小.zip
- 通用 DirectX.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


