#### 项目讲解原文链接:[大话系列 | 决策树—实战项目](https://mp.weixin.qq.com/s?__biz=MzI5MjYwNTU5NQ==&mid=2247484546&idx=1&sn=92de9334c676a7fc8ab5d2df64543d01&chksm=ec7f9f76db081660142d0c956312624b78df6afd355b7b95c49d4a4c7f7785b0ecb2120d7f11&token=1360579251&lang=zh_CN#rd)
<br><br>
#### 大话系列 | 决策树实战
> 你知不知道转行学习机器学习的同学,他们也太难了!
> 为什么啊?
首先,学习这个之前得先学Python,学了Python还得了解一下可视化,之后还得懂数据清洗,这还不是最最重要的。
> 那最重要的是什么?
最重要的还得回去补数学,概率论,然后还得有项目经验。
你算算,这层层过滤,最终才能有几个人看到这篇文章?
> 瞎说,看小一哥文章的同学能不懂这些?跟着做就完事了!
<br>
<br>
#### 正文
本篇是决策树算法的项目实战
如果你还不知道决策树算法,你可以选择和韩梅梅同学一起边相亲边学习决策树(手动狗头):
- [大话系列 | 决策树(上)—相亲?怎么说?](https://mp.weixin.qq.com/s?__biz=MzI5MjYwNTU5NQ==&mid=2247484478&idx=1&sn=da568b74c409382ec264b07fb5177450&chksm=ec7f9fcadb0816dcb33cd1646e774e42f577a718a71b2442efd4ad5e30a4ae59ea4ff69b6359&token=739331498&lang=zh_CN#rd)
- [大话系列 | 决策树(中)—相亲?怎么说?](https://mp.weixin.qq.com/s?__biz=MzI5MjYwNTU5NQ==&mid=2247484478&idx=1&sn=da568b74c409382ec264b07fb5177450&chksm=ec7f9fcadb0816dcb33cd1646e774e42f577a718a71b2442efd4ad5e30a4ae59ea4ff69b6359&token=739331498&lang=zh_CN#rd)
因为前面已经有了本次项目的数据分析部分,其实主要是数据清洗和可视化探索。
所以我们就直接接着往下了,数据分析部分错过的同学花几分钟补一下课
[《吊打分析师》实战—经典重现,你会怎么选择?](https://mp.weixin.qq.com/s?__biz=MzI5MjYwNTU5NQ==&mid=2247484398&idx=1&sn=58c811f106c94aa58a592f5f8322d9ac&chksm=ec7f981adb08110c7c3c54cb3066bbca720acd51745db71756de40ee4a177fb74979aa9e5c72&token=1460228086&lang=zh_CN#rd)
<br>
列一下我们的整个流程,大家心里也有个准备
- 数据清洗
- 可视化探索
- 特征工程
- 模型训练
- 模型调参
<br>
3,2,1 开始
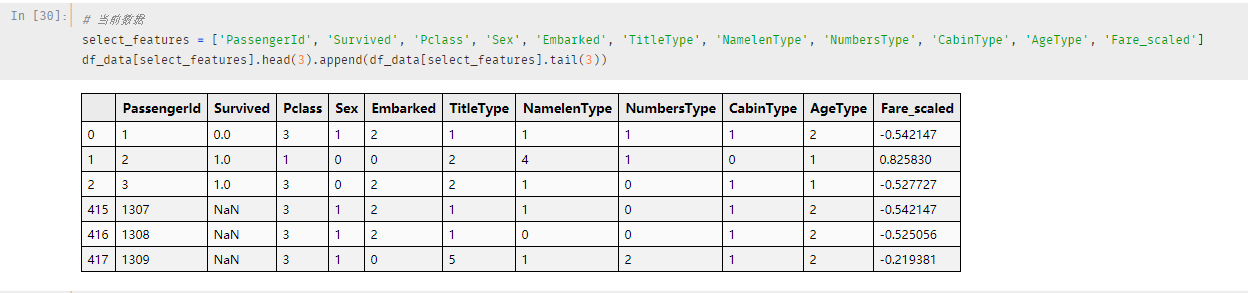
可能大家有点忘记我们现在的数据,先来看一下:
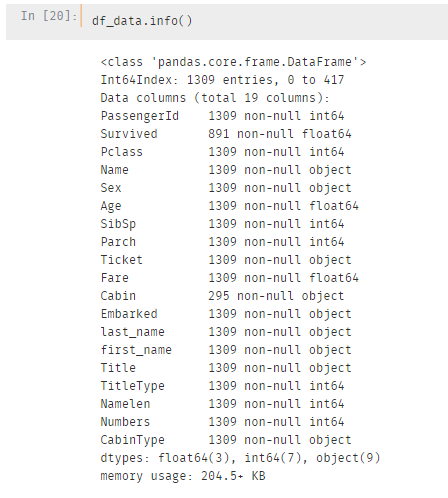
总共有19个列,在原有的基础上已经新增了7列数据
再来看具体的数据字段:
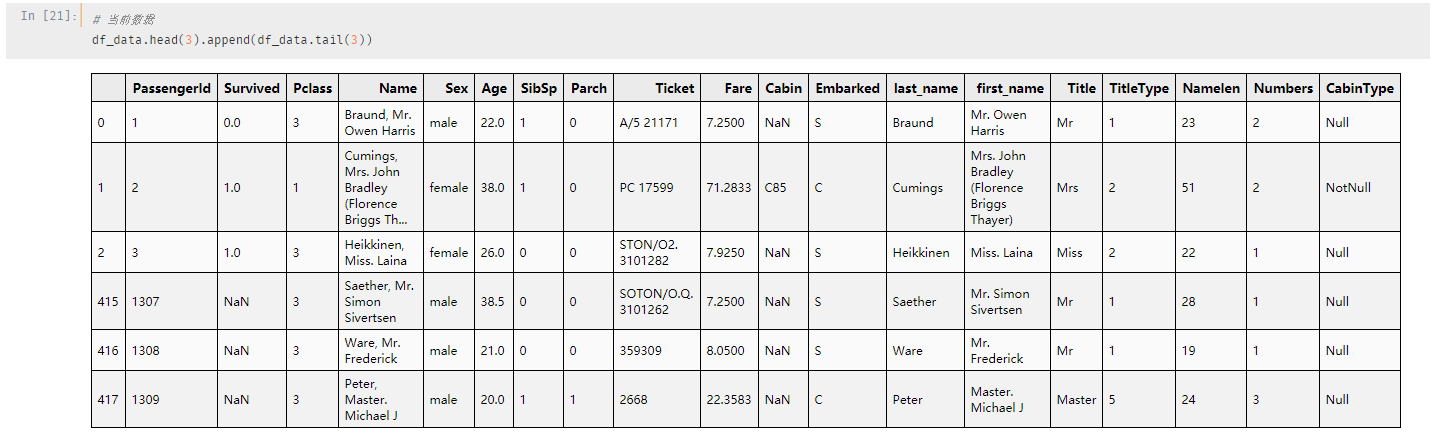
前891条数据是训练集数据,剩余的为测试集数据
一共19个字段,其中很多字段是我们处理过后的
准备好了吗,开始特征工程了
#### 特征工程
> 小一哥,特征工程听起来很高大上,具体是干什么的呢?
特征工程的目标是将数据处理成模型所需要的,然后直接在模型训练的时候丢进去
另外特征工程也需要对数据进行相应的转换,以调高模型的泛化能力
> 哦豁,听着好像还挺麻烦?
比前面的清洗工作简单很多,毕竟我们已经掌握了数据的基本特征
> 对对对,最麻烦的已经过去了,那特征工程具体都包括哪些操作呢?
**一般的特征处理包括:无量纲化、特征独热编码,以及连续数据变离散等操作。**
不能眼高手低,一起来实战一下
##### 无量纲化
`无量纲化使不同规格的数据转换到同一规格,常见的无量纲化方法有标准化和区间缩放法。`
标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。
区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
在目前的数据集中,连续数据有乘客票价和年龄,票价分布很不均匀我们已经知道,需要进行标准化
```python
"""进行特征标准化"""
scaler = preprocessing.StandardScaler()
# 对超高票价进行重新赋值
df_data.loc[df_data['Fare'] > 300, 'Fare'] = 300
# 对票价进行标准化
fare_slale_parm = scaler.fit(df_data[['Fare']])
df_data['Fare_scaled'] = scaler.fit_transform(df_data['Fare'].values.reshape(-1, 1), fare_slale_parm)
```
##### 连续数据离散化
还有一个连续型数据是乘客年龄,上节我们知道了此次事件中儿童定义是15岁,所以我们大可将乘客分为儿童,青年和老年
考虑到老年人存活的比例并不明显,小一将青年分为青年女士和青年男士
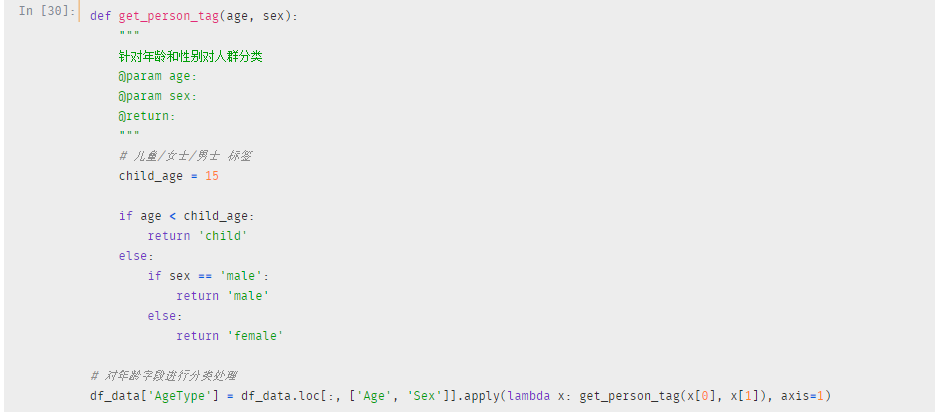
还有乘客的姓名长度、家庭成员数是我们后面衍生出来的连续性特征,同样的道理,将其连续化
> 姓名长度可以通过分段来处理,例如长度为0-20,20-30等
>
> 家庭成员数可以通过人数来分段
家庭成员数的分段标准是上一节可视化中家庭成员数,根据不同成员数的存活程度进行分布
```python
# 对Namelen 字段进行处理
df_data['Namelen'] = pd.cut(df_data['Namelen'], bins=[0, 20, 30, 40, 50, 100], labels=[0, 1, 2, 3, 4])
# 对Numbers 字段进行处理,分别为一个人、两个人、三个人和多个人
df_data['Numbers'] = pd.cut(df_data[''], bins=[0, 1, 2, 3, 20], labels=[0, 1, 2, 3])
```
##### 独热编码
`这个操作很有必要,大家注意看`
在计算机中需要计算不同特征之间的尺度,例如性别中的male和female,计算机是无法直接计算两个特征,但是你如果将male表示1,female表示2,下次计算机遇到了就会直接用2-1=1表示距离
这样做的好处是计算机可以识别,并且可以快速的计算
在我们的字段中,乘客性别、船舱等级、客舱是否为空还有刚才的年龄标识都需要进行独热编码
```python
"""进行特征编码"""
for feature in ['Sex', 'Embarked', 'CabinType', 'AgeType', ]:
le = preprocessing.LabelEncoder()
le.fit(df_data[feature])
df_data[feature] = le.transform(df_data[feature])
```
<br>
特征工程暂时就这些,还记得上节末尾的小问题吗?
> 可视化显示明明Age 和Numbers 对结果影响很大,这里怎么得分这么低?
我们在特征工程之后用同样的代码再比较一下
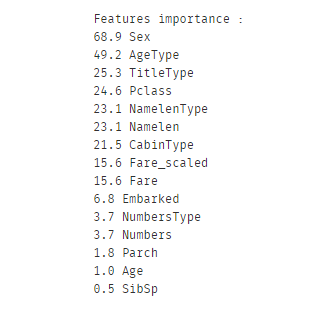
`果然,融合后的Numbers特征是优于任一个的,年龄分段后重要度也提升了`
没什么问题之后,我们取出相应的数据就可以开始建模了
现在的数据长这样,一起康康
<br><br>
#### 模型训练
在Python中,基本常用的算法都在sklearn 包里面。
我们直接两行代码调用
```python
# 决策树模型
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(criterion='entropy')
```
这里的clf 就是我们建立的决策树模型,我们只需要将数据放在模型中进行训练即可
需要注意的是我们前面一直是针对测试集和训练集的整个数据,这里需要进行分类
利用训练集训练模型,利用测试集输出测试结果
```python
"""分离训练集和测试集"""
train_data = df_data[df_data['Survived'].notnull()].drop(['PassengerId'], axis=1)
test_data = df_data[df_data['Survived'].isnull()].drop(['Survived'], axis=1)
# 分离训练集特征和标签
y = train_data['Survived']
X = train_data.drop(['Survived'], axis=1)
```
直接通过k 折交叉验证检查一下模型的准确率
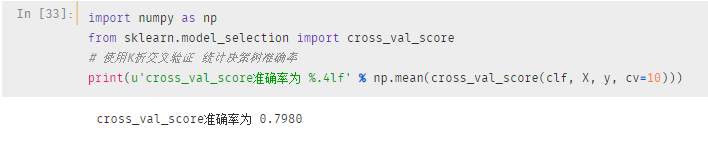
接近80%,这只是我们的一个基础模型,我们并没有进行任何的参数设置
你可以看到,在创建模型的时候,我们并没有设置参数,只是选用了信息增益算法进行节点划分,仅此而已
> 那,还能不能再次提升准确率呢?
往下看就是了,`暖男`都给你们准备好了
<br>
#### 模型调参
> 想一想,模型调参的目的是什么?
`嗯,是剪枝,通过设置相应的参数达到剪枝的目的,这里的剪枝指的是预剪枝`
知己知彼才能百战不殆,先了解一下参数的意义
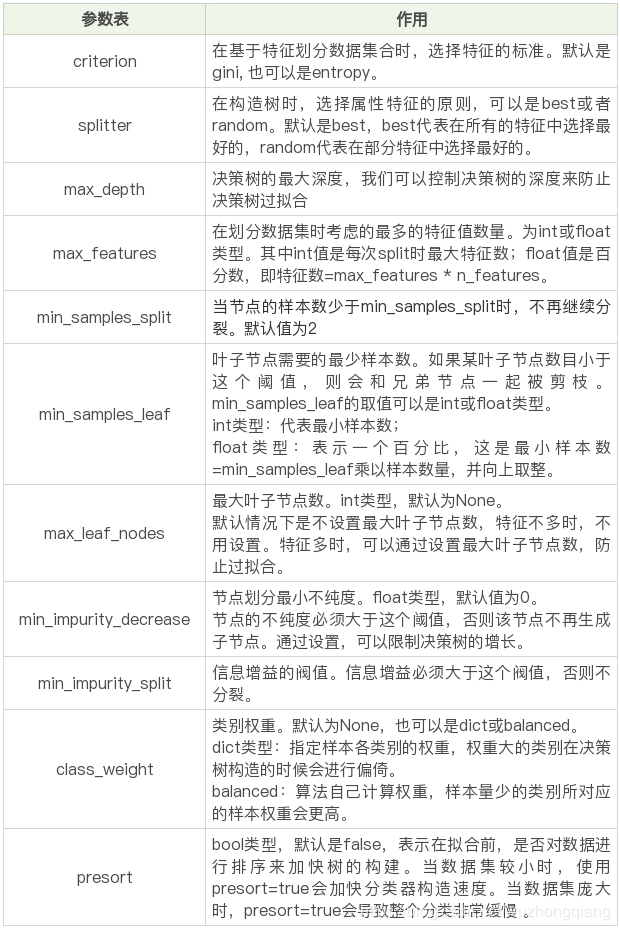
这个是sklearn 中决策树的参数对应表
在应用过程中,我们可以通过设置一个字典提前声明参数的范围
```python
# 设置参数
parameters = {
'criterion': ['gini', 'entropy'],
'max_depth': range(2, 10),
'min_impurity_decrease': np.linspace(0, 1, 10),
'min_samples_split': range(2, 30, 2),
'class_weight': ['balanced', None]
}
```
sklearn中提供了网格搜索的方法,供我们寻找最优参数
在搜索过程中,我们设置了5折交叉验证,以保证预测结果的稳定性
```python
"""通过网格搜索寻找最优参数"""
gird_clf = GridSearchCV(DecisionTreeClassifier(), parameters, cv=5, return_train_score=True)
# 模型训练
gird_clf.fit(X, y)
# 结果预测
pred_labels = gird_clf.predict(test_data.drop(['PassengerId'], axis=1))
```
在进行调参之后,模型的准确率提高了,并且相应的参数我们也可以看到
如果你觉得这个准确率可以,那就可以直接去进行预测了

需积分: 5 31 浏览量
2024-04-28
22:30:18
上传
评论
收藏 1.01MB ZIP 举报
 机器学习实战算法,搭配《大话算法系列》,一节算法讲解+一节算法实战.zip (2000个子文件)
机器学习实战算法,搭配《大话算法系列》,一节算法讲解+一节算法实战.zip (2000个子文件)  README.md 9KB README.md 5KB README.md 4KB README.md 3KB README.md 737B model.py 4KB read_data.py 2KB __init__.py 350B __init__.py 342B main.py 333B
README.md 9KB README.md 5KB README.md 4KB README.md 3KB README.md 737B model.py 4KB read_data.py 2KB __init__.py 350B __init__.py 342B main.py 333B 5_71.txt 1KB 5_41.txt 1KB 9_30.txt 1KB 3_47.txt 1KB 5_15.txt 1KB 9_40.txt 1KB 0_24.txt 1KB 9_78.txt 1KB 9_51.txt 1KB 2_54.txt 1KB 0_6.txt 1KB 1_76.txt 1KB 1_15.txt 1KB 5_3.txt 1KB 8_86.txt 1KB 7_92.txt 1KB 6_16.txt 1KB 4_69.txt 1KB 5_23.txt 1KB 3_14.txt 1KB 3_3.txt 1KB 8_27.txt 1KB 6_12.txt 1KB 8_53.txt 1KB 7_36.txt 1KB 9_74.txt 1KB 1_20.txt 1KB 9_23.txt 1KB 3_38.txt 1KB 3_78.txt 1KB 1_62.txt 1KB 5_40.txt 1KB 1_54.txt 1KB 0_84.txt 1KB 8_29.txt 1KB 2_43.txt 1KB 7_45.txt 1KB 4_41.txt 1KB 6_60.txt 1KB 2_71.txt 1KB 8_28.txt 1KB 4_22.txt 1KB 3_72.txt 1KB 2_79.txt 1KB 4_52.txt 1KB 4_62.txt 1KB 7_48.txt 1KB 7_93.txt 1KB 7_9.txt 1KB 9_63.txt 1KB 7_40.txt 1KB 4_51.txt 1KB 5_53.txt 1KB 6_30.txt 1KB 8_22.txt 1KB 9_11.txt 1KB 1_25.txt 1KB 5_12.txt 1KB 7_15.txt 1KB 8_8.txt 1KB 3_70.txt 1KB 7_77.txt 1KB 2_83.txt 1KB 5_24.txt 1KB 5_60.txt 1KB 1_29.txt 1KB 8_54.txt 1KB 2_37.txt 1KB 4_97.txt 1KB 2_32.txt 1KB 0_17.txt 1KB 4_70.txt 1KB 5_79.txt 1KB 4_88.txt 1KB 2_23.txt 1KB 7_73.txt 1KB 9_66.txt 1KB 4_79.txt 1KB 1_73.txt 1KB 2_78.txt 1KB 8_10.txt 1KB 2_12.txt 1KB 2_90.txt 1KB 1_48.txt 1KB 2_28.txt 1KB 1_22.txt 1KB 6_42.txt 1KB 2_77.txt 1KB 3_39.txt 1KB 1_33.txt 1KB
5_71.txt 1KB 5_41.txt 1KB 9_30.txt 1KB 3_47.txt 1KB 5_15.txt 1KB 9_40.txt 1KB 0_24.txt 1KB 9_78.txt 1KB 9_51.txt 1KB 2_54.txt 1KB 0_6.txt 1KB 1_76.txt 1KB 1_15.txt 1KB 5_3.txt 1KB 8_86.txt 1KB 7_92.txt 1KB 6_16.txt 1KB 4_69.txt 1KB 5_23.txt 1KB 3_14.txt 1KB 3_3.txt 1KB 8_27.txt 1KB 6_12.txt 1KB 8_53.txt 1KB 7_36.txt 1KB 9_74.txt 1KB 1_20.txt 1KB 9_23.txt 1KB 3_38.txt 1KB 3_78.txt 1KB 1_62.txt 1KB 5_40.txt 1KB 1_54.txt 1KB 0_84.txt 1KB 8_29.txt 1KB 2_43.txt 1KB 7_45.txt 1KB 4_41.txt 1KB 6_60.txt 1KB 2_71.txt 1KB 8_28.txt 1KB 4_22.txt 1KB 3_72.txt 1KB 2_79.txt 1KB 4_52.txt 1KB 4_62.txt 1KB 7_48.txt 1KB 7_93.txt 1KB 7_9.txt 1KB 9_63.txt 1KB 7_40.txt 1KB 4_51.txt 1KB 5_53.txt 1KB 6_30.txt 1KB 8_22.txt 1KB 9_11.txt 1KB 1_25.txt 1KB 5_12.txt 1KB 7_15.txt 1KB 8_8.txt 1KB 3_70.txt 1KB 7_77.txt 1KB 2_83.txt 1KB 5_24.txt 1KB 5_60.txt 1KB 1_29.txt 1KB 8_54.txt 1KB 2_37.txt 1KB 4_97.txt 1KB 2_32.txt 1KB 0_17.txt 1KB 4_70.txt 1KB 5_79.txt 1KB 4_88.txt 1KB 2_23.txt 1KB 7_73.txt 1KB 9_66.txt 1KB 4_79.txt 1KB 1_73.txt 1KB 2_78.txt 1KB 8_10.txt 1KB 2_12.txt 1KB 2_90.txt 1KB 1_48.txt 1KB 2_28.txt 1KB 1_22.txt 1KB 6_42.txt 1KB 2_77.txt 1KB 3_39.txt 1KB 1_33.txt 1KB共 2000 条
- 1
- 2
- 3
- 4
- 5
- 6
- 20
资源评论













