本文档来自公众号:五分钟学大数据
2 / 11
目录
一、Apache Spark
............................................................................................................
3
二、Spark SQL 发展历程
.................................................................................................
3
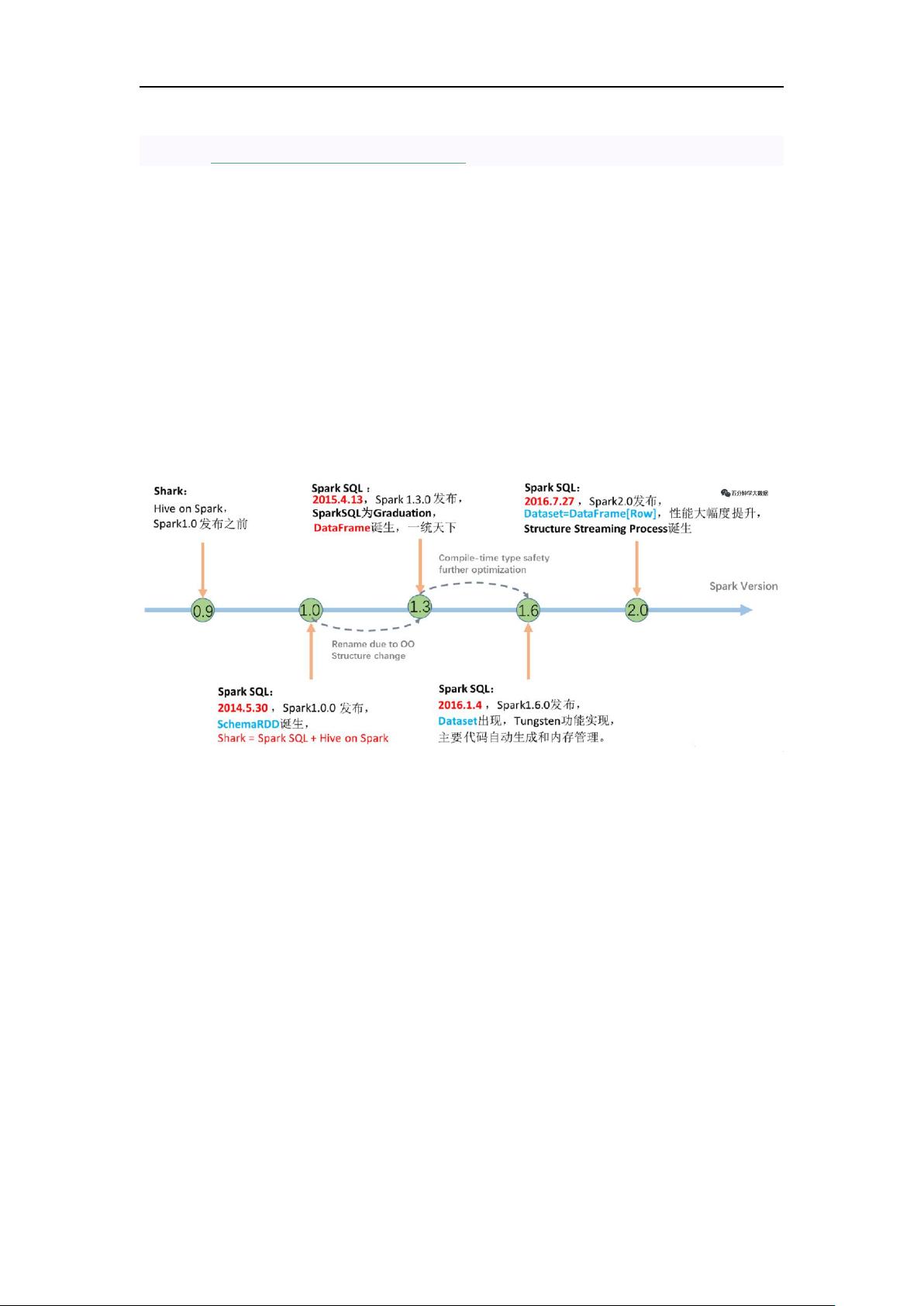
1. Shark 的诞生
.......................................................................................................
3
2. SparkSQL-DataFrame 诞生
.................................................................................
4
3. SparkSQL-Dataset 诞生
.....................................................................................
4
三、Spark SQL 底层执行原理
.........................................................................................
4
步骤 1. Parser 阶段:未解析的逻辑计划
............................................................
5
步骤 2. Analyzer 阶段:解析后的逻辑计划
........................................................
6
步骤 3. Optimizer 模块:优化过的逻辑计划
......................................................
7
步骤 4. SparkPlanner 模块:转化为物理执行计划
...........................................
8
步骤 5. 执行物理计划
.............................................................................................
9
总结:整体执行流程图
............................................................................................
9
四、Catalyst 的两大优化
............................................................................................
10
1. RBO:基于规则的优化
......................................................................................
10
2. CBO:基于代价的优化
......................................................................................
11