计算机视觉四大任务(分类、定位、检测、分割) 计算机视觉.pdf
版权申诉


计算机视觉四⼤任务(分类、定位、检测、分割)
前⾔前⾔
全⽂来源于所作的
⼤佬毕业于南京⼤学LAMDA,主攻机器学习、深度学习、计算机视觉,出版了书籍《深度学习 视频理解》,也常常分享相关知识,特别细
致,⼤家感兴趣的可以知乎关注。侵权⽴删,还望告知。
计算机视觉
(Computer Vision)⼜称为机器视觉(Machine Vision),顾名思义是⼀门“教”会计算机如何去“看”世界的学科。
存在的难题包括:
语义鸿沟(semantic gap):⼈类可以轻松地从图像中识别出⽬标,⽽计算机看到的图像只是⼀组0到255之间的整数。
计算机视觉任务的其他困难 拍摄视⾓变化、⽬标占据图像的⽐例变化、光照变化、背景融合、⽬标形变、遮挡等。
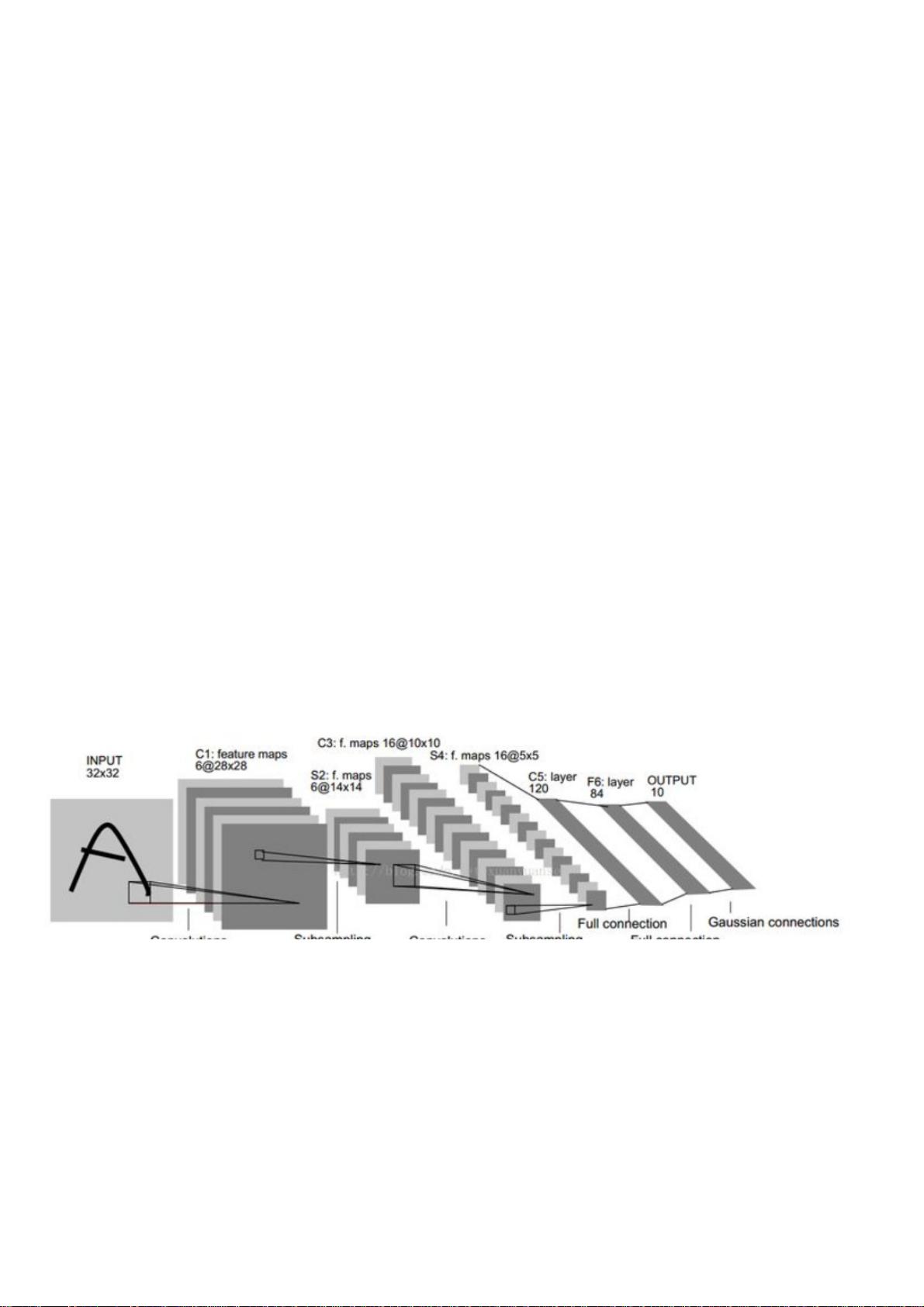
卷积神经⽹络(卷积神经⽹络(convolutional neural networks,,CNN))
经典的多层感知机由⼀系列全连接层组成,卷积神经⽹络中除全连接层外,还有卷积层和汇合(pooling)层。
(1) 卷积层卷积层
为什么要⽤卷积层 输⼊图像通常很维数很⾼,例如,1,000×1,000⼤⼩的彩⾊图像对应于三百万维特征。因此,继续沿⽤多层感知机中
的全连接层会导致庞⼤的参数量。⼤参数量需要繁重的计算,⽽更重要的是,⼤参数量会有更⾼的过拟合风险。卷积是局部连接、共享参数
版的全连接层。这两个特性使参数量⼤⼤降低。卷积层中的权值通常被成为滤波器(filter)或卷积核(convolution kernel)。
局部连接 在全连接层中,每个输出通过权值(weight)和所有输⼊相连。⽽在视觉识别中,关键性的图像特征、边缘、⾓点等只占据了整张图
像的⼀⼩部分,图像中相距很远的两个像素之间有相互影响的可能性很⼩。因此,在卷积层中,每个输出神经元在通道⽅向保持全连接,⽽
在空间⽅向上只和⼀⼩部分输⼊神经元相连。
共享参数 如果⼀组权值可以在图像中某个区域提取出有效的表⽰,那么它们也能在图像的另外区域中提取出有效的表⽰。也就是说,如果
⼀个模式(pattern)出现在图像中的某个区域,那么它们也可以出现在图像中的其他任何区域。因此,卷积层不同空间位置的神经元共享权
值,⽤于发现图像中不同空间位置的模式。共享参数是深度学习⼀个重要的思想,其在减少⽹络参数的同时仍然能保持很⾼的⽹络容量
(capacity)。卷积层在空间⽅向共享参数,⽽循环神经⽹络(recurrent neural networks,RNN)在时间⽅向共享参数。
卷积层的作⽤ 通过卷积,我们可以捕获图像的局部信息。通过多层卷积层堆叠,各层提取到特征逐渐由边缘、纹理、⽅向等低层级特征过
渡到⽂字、车轮、⼈脸等⾼层级特征。
卷积层中的卷积和数学教材中的卷积是什么关系 基本没有关系。卷积层中的卷积实质是输⼊和权值的互相关(cross-correlation)函数,⽽
不是数学教材中的卷积。
描述卷积的四个量 ⼀个卷积层的配置由如下四个量确定。
1. 滤波器个数。使⽤⼀个滤波器对输⼊进⾏卷积会得到⼀个⼆维的特征图(feature map)。我们可以⽤时使⽤多个滤波器对输⼊进⾏卷
积,以得到多个特征图。
2. 感受野(receptive field)
F
,即滤波器空间局部连接⼤⼩。


剩余15页未读,继续阅读
资源评论

 weixin_444594632023-11-26怎么能有这么好的资源!只能用感激涕零来形容TAT...
weixin_444594632023-11-26怎么能有这么好的资源!只能用感激涕零来形容TAT... Fontainebleau042022-06-21用户下载后在一定时间内未进行评价,系统默认好评。
Fontainebleau042022-06-21用户下载后在一定时间内未进行评价,系统默认好评。
_webkit
- 粉丝: 30
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 论文(最终)_20240430235101.pdf
- 基于python编写的Keras深度学习框架开发,利用卷积神经网络CNN,快速识别图片并进行分类
- 最全空间计量实证方法(空间杜宾模型和检验以及结果解释文档).txt
- 5uonly.apk
- 蓝桥杯Python组的历年真题
- 2023-04-06-项目笔记 - 第一百十九阶段 - 4.4.2.117全局变量的作用域-117 -2024.04.30
- 2023-04-06-项目笔记 - 第一百十九阶段 - 4.4.2.117全局变量的作用域-117 -2024.04.30
- 前端开发技术实验报告:内含4四实验&实验报告
- Highlight Plus v20.0.1
- 林周瑜-论文.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


