机器学习基础
朱明超
Email: deityrayleigh@gmail.com
Github: github.com/MingchaoZhu/DeepLearning
1 学习算法
机器学习算法描述⼀种能够从数据中学习的算法。学习指对于某类任务 T,为其定义性能度量 P,⼀个计算机程序被认为可以从经验 E 中学习是指:
通过经验 E 改进后,它在任务 T 上的性能度量 P 有所提高。
任务 T:机器学习任务定义为机器学习系统应该如何处理样本(Example)。例如,识别⼿写体数字识别的任务为:通过将输⼊的图⽚处理后,输出
该图⽚对应的数字(分类)。样本是量化的特征(Feature)的集合,⽤向量 x ∈ R
n
表⽰,其中向量的每个元素 x
i
是⼀个特征。例如⼀张图⽚的特
征就是这张图⽚⾥的像素点的值。
性能度量 P:为了评估机器学习的优劣,需要对算法的输出结果进⾏定量的衡量分析,这就需要合适的性能度量指标。
指标 说明
True Positive TP 将正样本预测为正例数⽬
True Negative TN 将负样本预测为负例数⽬
False Positive FP 将负样本预测为正例数⽬
False Negative FN 将正样本预测为负例数⽬
• 针对分类任务 (详细描述见第⼗⼀章):
– 准确率 (Accuracy):acc =
TP+TN
TP+TN+FP+FN
。
– 错误率 (Error-rate):err = 1 − acc
– 精度 (Precision):P =
TP
TP+FP
– 召回率 (Recall):R =
TP
TP+FN
– F
1
值:F
1
=
2PR
P+R
• 针对回归任务:距离误差
经验 E:根据经验 E 的不同,机器学习算法可以分为:⽆监督 (Unsupervised) 算法和监督 (Supervised) 算法。
• 监督学习算法 (Supervised Learning):训练集的数据中包含样本特征和标签值,常见的分类和回归算法都是有监督的学习算法。
• ⽆监督学习算法 (Unsupervised Learning):训练集的数据中只包含样本特征,算法需要从中学习出特征中隐藏的结构化特征,聚类、密度
估计等都是⽆监督的学习算法。
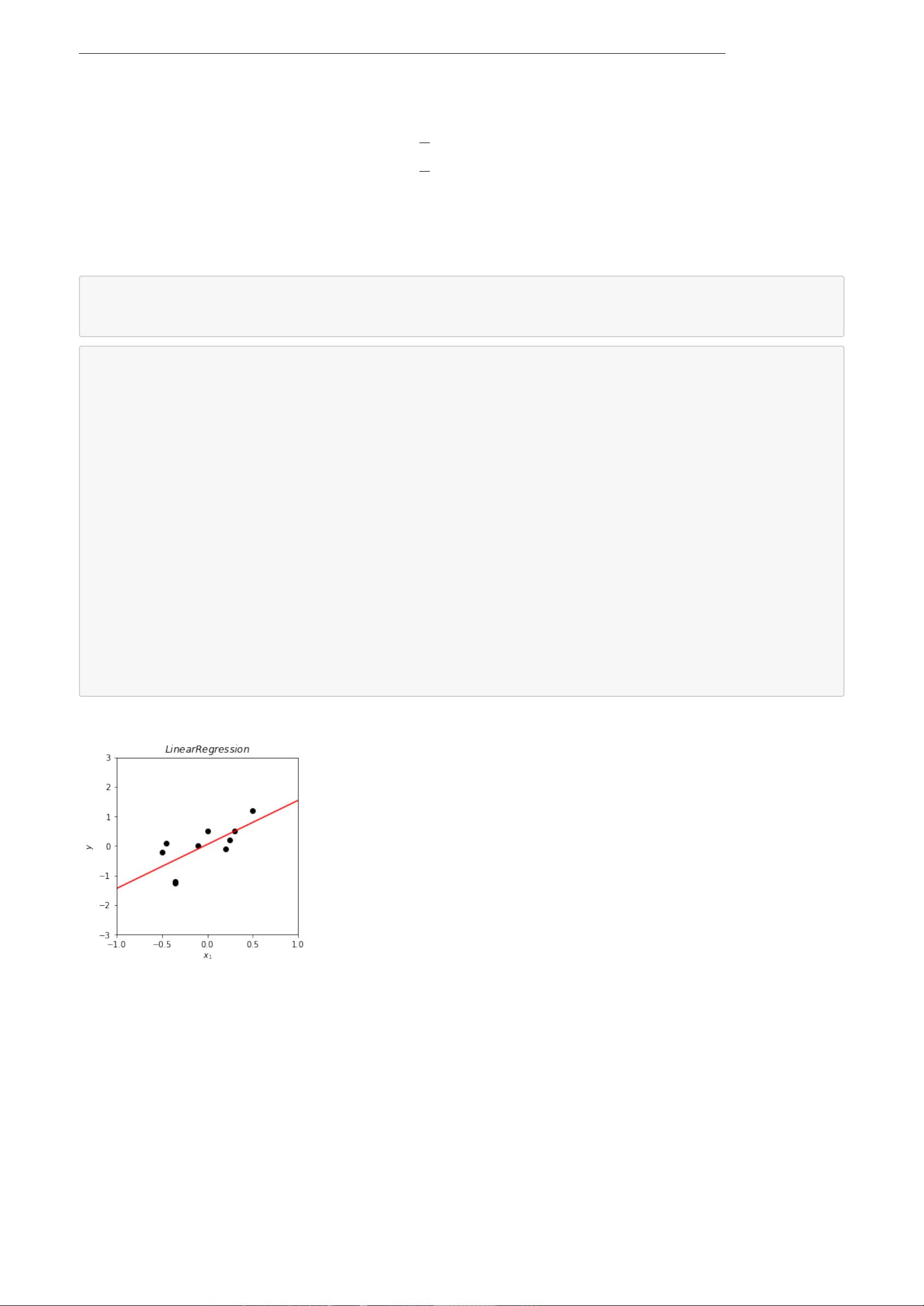
1.1 举例:线性回归
线性回归(Linear Regression)的⽬标:获得⼀个函数 f ,满⾜ f (x) = ˆy,其中 x ∈ R
n
, ˆy ∈ R,使得 ˆy 接近于真实的标签 y。
我们定义线性回归的输出为:
f(x) = w
⊤
x (1)
其中 w ∈ R
n
是我们需要学习的参数 (Parameter)。
在线性回归中,对任务 T 的定义:通过输出 ˆy = w
⊤
x,从 x 预测 y。
性能度量 P 的定义:假设测试集的特征和标签分别⽤ X
(test)
和 y
(test)
表⽰。可以采⽤的性能度量⽅式是均⽅误差(Mean Squared Error),如果
ˆ
y
(test)
表⽰模型在测试集上的预测值,那么均⽅误差公式为:
MSE
test
=
1
m
i
(
ˆ
y
(test)
− y
(test)
)
2
i
=
1
m
||
ˆ
y
(test)
− y
(test)
||
2
2
(2)
为了构建⼀个机器学习算法,需要设计⼀个算法,通过观察训练集 (X
(train)
, y
(train)
) 获得经验,改进权重 w 以减少 MSE
test
。⼀种直观的⽅式是
1