
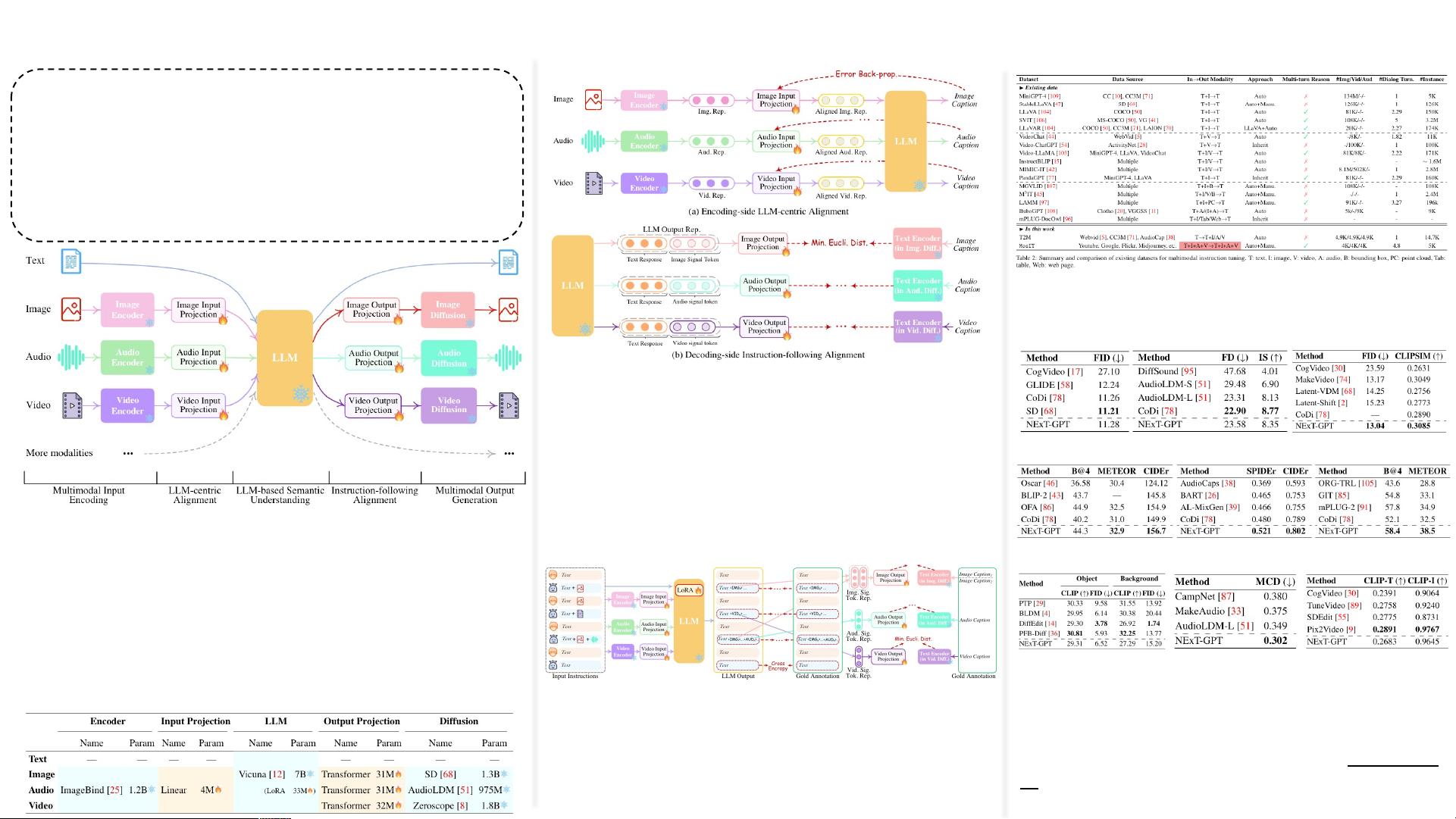
Next-GPT (NUS)
Motivation: 现有视觉语言模型大多受到多模态输入端理解
的限制,无法以多种模态生成内容。 现实世界中,人类总
是通过各种方式感知世界并交流,因此开发一个可以接受和
生成多模态内容的模型十分重要。
整体思路:将LLM与多模态适配器和不同的扩散解码器进行
连接,让模型能够钢制输入并以文本、图像、视频和音频的
任意组合生成输出。
整个模型分为三个阶段:
1. 多模态编码阶段:利用现有比较完善的模型对各种模式的输
入进行编码;
2. LLM理解与推理阶段:选择一个LLM作为核心Agent,其负
责接收不同模态信息并进行理解和推理,输出分为两种(1)
文本形式的回复,(2)每种模态的signal tokens用于解码;
3. 多模态生成阶段:从 LLM(如果有)接收具有特定指令的
多模态信号,基于 Transformer 的输出投影层将信号标记
表示映射为后续多模态解码器可以理解的表示形式。
为了弥合不同模态特征空间之间的差距,并确保不同输
入的流畅语义理解,有必要进行对齐学习。
1. 编码侧:基于现有与语料库和benchmark准备X-
caption对,X表示图片、视频、音频,实现其他模
态与文本模态的对齐;
2. 解码侧:为了让LLM输出的signal token中蕴含更
有效的模态信息用于扩散模型,最小化signal
token与扩散模型的条件文本表示之间的距离;
编码端和解码端与LLM保持一致仍不能保证整个系统
可以忠实地遵循和理解用户的指令,因此需要进行指
令微调。使用 (输入,输出)对进行指令微调,并使用
对应的Loss进行优化。
数据集分为两种:Tex t+ X->Text 和 Text->Tex t+ X .
现有数据集不满足全模态生成的模式,因此该论文
又自己构建了一个数据集MosIT(5k对话).
Text-to-Image
Text-to-Audio
Text-to-Video
Image-to-Text
Audio-to-Text
Video-to-Text
Text+Image-to-
Image
Text+Audio-
to-Audio
Text+Video-to-
Video
在不同模态设置下进行了详细的实验验证,通过与各
个模态设置的基线方法进行对比可知,该方法取得了
较优的实验结果,证明了方案的可行性。实验分析较
少。
http://arxiv.org/abs/2309.05519
资源评论













