

HBase 的介绍
1.Hbase 的特点:
1.面向列:Hbase 是面向列的存储和权限控制,并支持独立索引。列式存储,其数据在表中
是按照某列存储的,这样在查询只需要少数几个字段时,能大大减少读取的数据量。
2.多版本:Hbase 每一个列的存储有多个 Version。
3.稀疏性:为空的列不占用存储空间,表可以设计得非常稀疏。
4.扩展性:底层依赖 HDFS。
5.高可靠性:WAL 机制保证了数据写入时不会因集群异常而导致写入数据丢失, Replicaon
机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且 Hbase 底层使用
HDFS,HDFS 本身也有备份。
6.高性能:底层的 LSM 数据结构和 Rowkey 有序排列等架构上的独特设计,使得 Hbase 具有
非常高的写入性能。region 切分,主键索引和缓存机制使得 Hbase 在海量数据下具备一定的
随机读取性能,该性能真对 Rowkey 的查询能到达到毫秒级别。
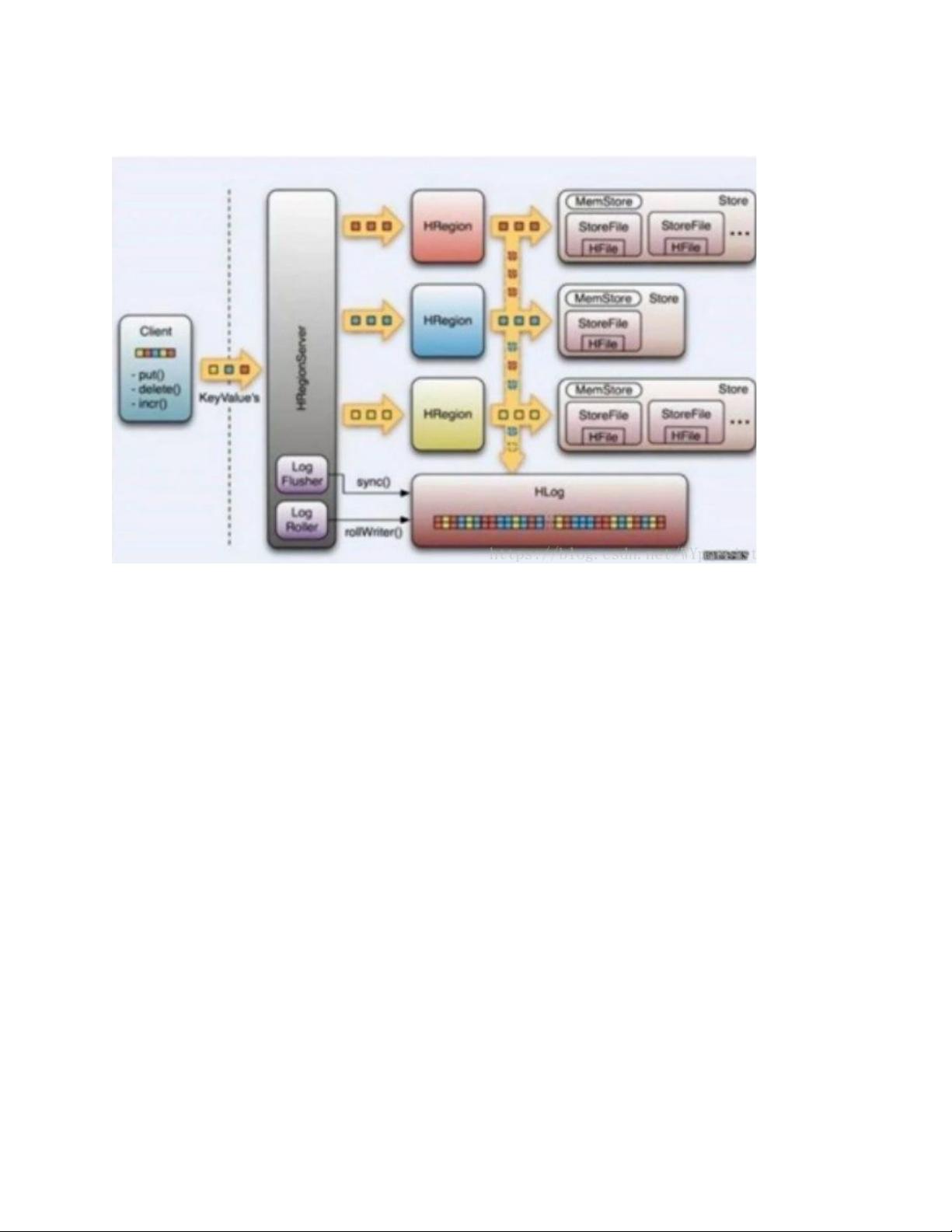
2.HBase 的读写过程
写数据流程
动物园管理员中存储了元表的区域信息,从元表获取相应地区信息,然后找到元表
的数据
根据命名空间,表名和 rowkey 根据元表的数据找到写入数据对应的区域信息
找到对应的 RegionServer 的
把数据分别写到的 Hlog 和那种 MEMSTORE 上一份
的 memstore 达到一个阈值后则把数据刷成一个 StoreFile 文件。若的 memstore 中
的数据有丢失,则可以总的 Hlog 上恢复
当多个 StoreFile 文件达到一定的大小后,会触发紧凑合并操作,合并为一个
StoreFile,这里同时进行版本的合并和数据删除。
当压缩后,逐步形成越来越大的 StoreFIle 后,会触发拆分操作,把当前的 StoreFile
分成两个,这里相当于把一个大的区域分割成两个区域如下图:
19.png
读数据流程
1. 动物园管理员中存储了元表的区域信息,所以先从动物园管理员中找到元表区域的位置,
然后读取元表中的数据.META 中又存储了用户表的区域信息。
2. 根据命名空间,表名和 rowkey 在元表中找到对应的区域信息
3. 找到这个区域对应的 RegionServer 的
4. 查找对应的区域
5. 先从那种 MEMSTORE 找数据,如果没有,再到 StoreFile 上读(为了读取的效率)。
Client-Server 交互逻辑
运维开发了很长一段时间 HBase,经常有业务同学咨询为什么客户端配置文件中没有配置
RegionServer 的地址信息,这里针对这种疑问简单的做下解释,客户端与 HBase 系统的交互阶段主要
有如下几个步骤:

剩余10页未读,继续阅读
资源评论













