
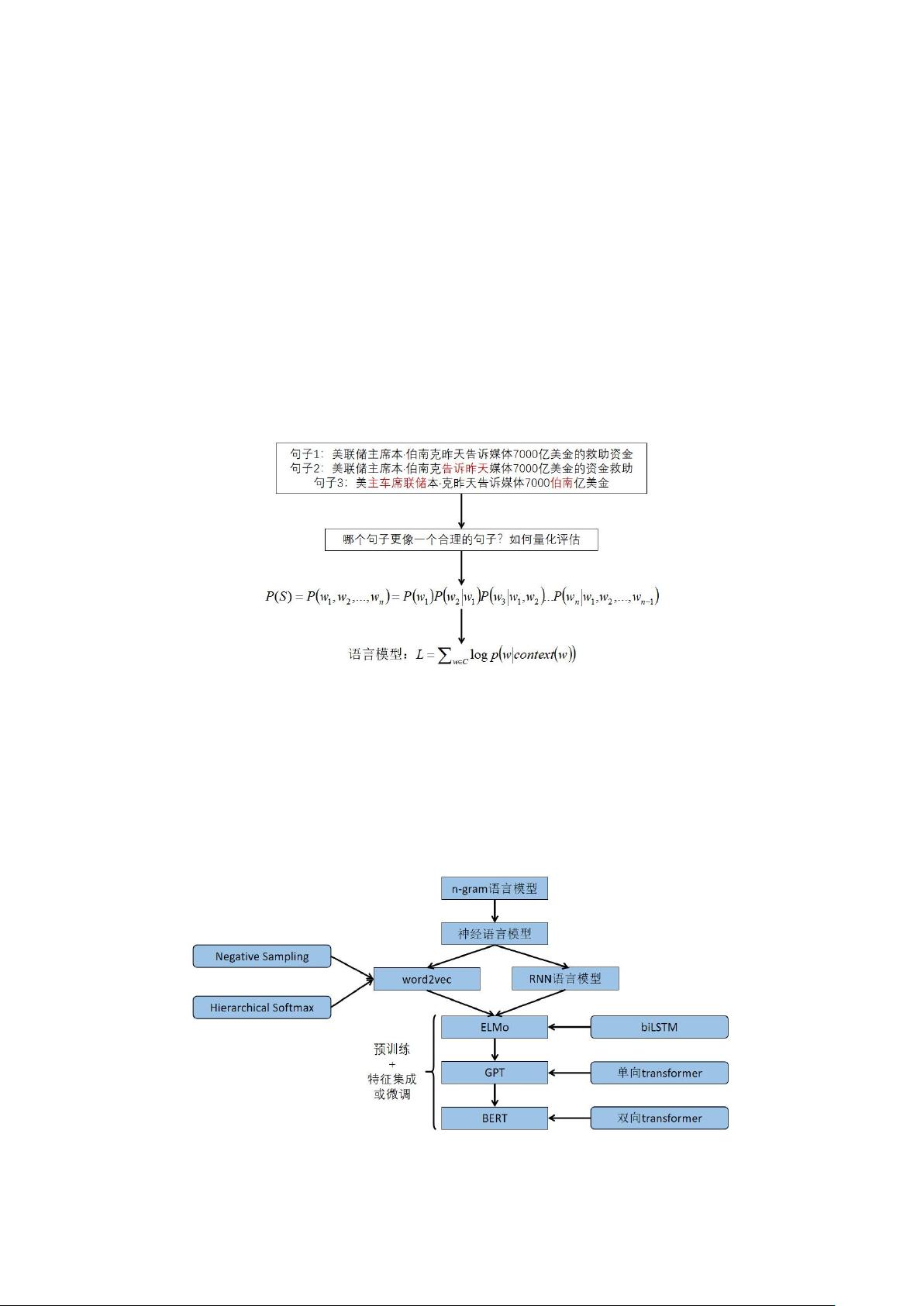
一、语言模型
语言模型的目的为了能够量化地衡量哪个句子更像一个客观世界真实的句子。根据上下
文推测下一个词是什么,这不需要人工标注语料,可以从大规模语料库中学习丰富的语义知
识。语言模型最初是针对语音识别问题而开发的,它们仍然在现代语音识别系统中发挥着核
心作用,同时也广泛用于其他自然语言处理应用程序。核心思想是根据句子里面前面的一系
列前导单词预测后面跟哪个单词的概率大小(理论上除了上文之外,也可以引入单词的下文
联合起来预测单词出现概率)。句子里面每个单词都会根据上文预测自己,把所有这些单词
的产生概率乘起来,数值越大代表这越像一个真实的句子。
目前主要有两类语言模型,分别是统计语言模型和神经网络语言模型。统计语言模型主
要是 n-gram 语言模型,在神经网络语言模型中,主要包括原始的神经网络语言模型、
word2vec、GloVe、基于循环神经网络的语言模型、ELMo、GPT、BERT。这些语言模型基本
呈承接关系,每一个新的语言模型会在前一个语言模型的基础上进行改进升级。本节课会对
其中几种重要的语言模型进行介绍。
图 1 语言模型




剩余38页未读,继续阅读
资源评论













