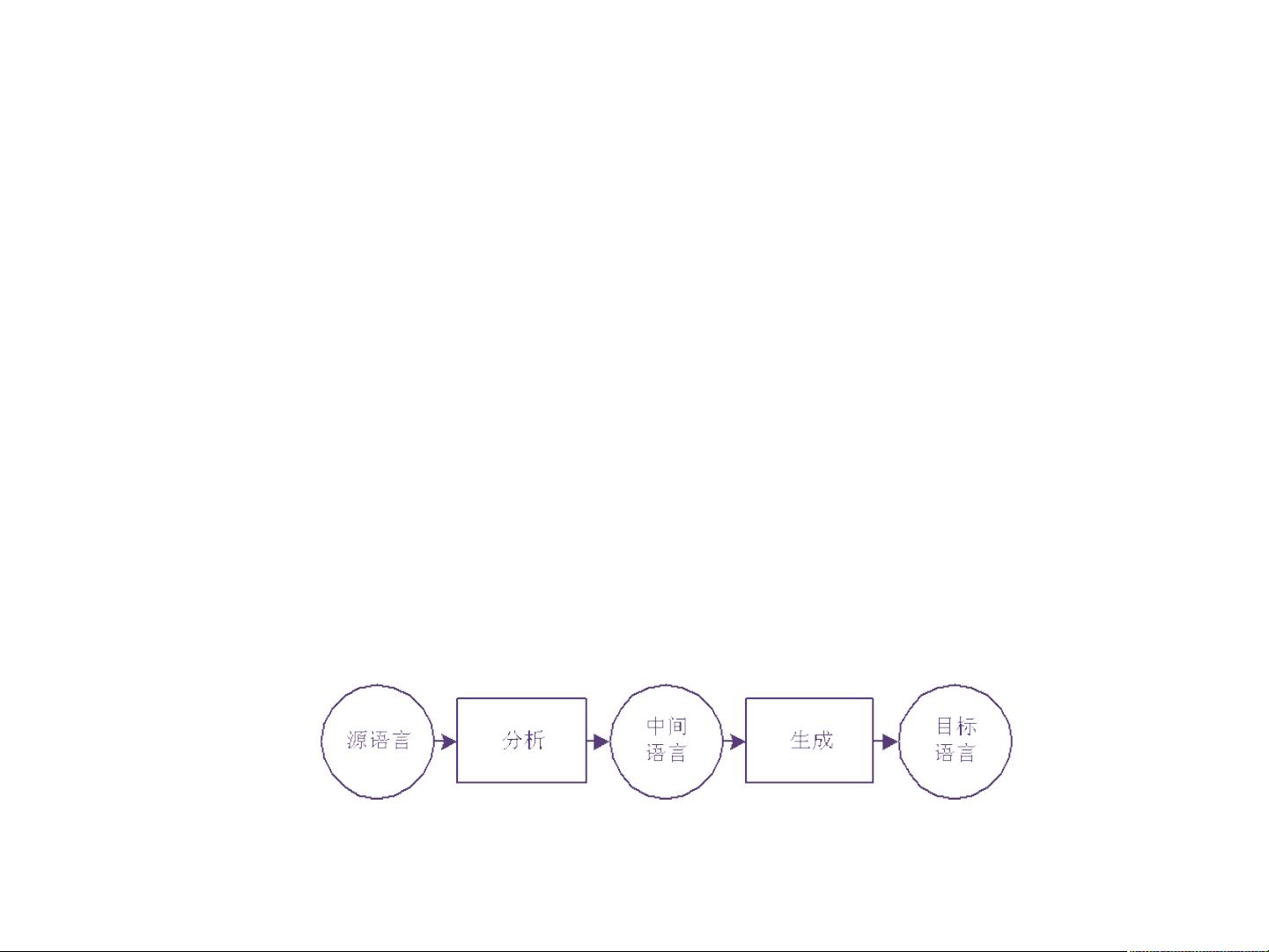
【课程简介】 本课程适合所有需要学习自然语言处理技术的同学,课件内容制作精细,由浅入深,适合入门或进行知识回顾。 本章为该课程的其中一个章节,如有需要可下载全部课程 全套资源下载地址:https://download.csdn.net/download/qq_27595745/85227773 【全部课程列表】 1_自然语言处理概论 共48页.pdf 2_机器学习与自然语言处理 共33页.pdf 3_n元模型 共33页.pdf 4_数据平滑技术 共39页.pdf 5_汉语分词 共34页.pdf 6_隐马尔科夫模型 共40页.pdf 7_词类标注 共32页.pdf 8_ME&CRF 共48页.pdf 9_常见深度学习模型 共49页.pdf 10_词向量 共38页.pdf 11_基于上下文无关文法的句法分析 共62页.pdf 12_PCFG和统计句法分析 共50页.pdf 13_依存句法分析介绍 共44页.pdf 14_自然语言处理中的话题模型 共48页.pdf 15_机器翻译概述 共45页.pdf 自然语言处理(NLP)是一门涉及人工智能与语言学的交叉学科,旨在让计算机理解和生成人类语言。在北大开设的这门NLP课程中,涵盖了从基础理论到具体应用的多个方面,包括自然语言处理概论、机器学习、n元模型、数据平滑技术、汉语分词、隐马尔科夫模型、词类标注、条件随机场(CRF)、深度学习模型、词向量、句法分析以及机器翻译等核心主题。 机器翻译(Machine Translation, MT)作为NLP领域的重要分支,其研究目标是开发能够将一种自然语言的文本自动转化为另一种语言的软件系统。这一技术的发展源于人类希望跨越语言障碍实现无障碍沟通的愿望。尽管全自动、高质量的机器翻译(FAHQMT)目前仍然是一个遥不可及的梦想,但随着算法和技术的进步,机器翻译已经在许多实际场景中取得了显著的效果。 机器翻译的基本方法主要包括基于规则的方法和基于数据驱动的方法。早期的基于规则的方法如直接翻译法、转换法和中间语言法,它们依赖于对源语言和目标语言的详细规则理解。直接翻译法简单地逐词对应,忽略了语言间的差异,效果较差。转换法和中间语言法则试图通过中间语言来实现更复杂的语义转换,但这种方法的挑战在于中间语言的定义和实现。 20世纪80年代后,基于语料库的机器翻译技术逐渐兴起,主要包括基于统计和基于实例的方法。这些方法通过学习大量平行语料库中的翻译样本,自动提取翻译模式,减少了对语言规则的依赖。统计机器翻译(Statistical Machine Translation, SMT)通过建立和训练统计模型来预测最佳翻译结果,而神经机器翻译(Neural Machine Translation, NMT)进一步发展,利用深度学习网络模型,如Transformer,来实现端到端的翻译,效果优于传统统计方法。 规则系统中的知识表示是构建机器翻译系统的关键。它包括词典、规则库以及相应的分析和生成步骤。词典存储词汇信息,规则描述句子结构和转换过程,而语义分析和形态生成则帮助确保翻译的准确性和自然度。 在实际操作中,机器翻译流程通常包括词法分析、句法分析、语义分析、结构转换、句子生成、译词选择和形态生成等步骤。例如,一个简单的中文句子“她把一束花放在桌上”会被切分、标注,然后进行句法分析,通过结构转换和规则应用,将其转化为目标语言的相应表达。 尽管机器翻译技术已取得长足进步,但仍面临诸多挑战,如语境理解、多义词处理、文化差异等。随着技术的不断迭代和大数据的积累,未来机器翻译的质量有望进一步提升,更好地服务于全球化的交流需求。
剩余44页未读,继续阅读
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~






 ah_xiong2024-01-09资源有一定的参考价值,与资源描述一致,很实用,能够借鉴的部分挺多的,值得下载。
ah_xiong2024-01-09资源有一定的参考价值,与资源描述一致,很实用,能够借鉴的部分挺多的,值得下载。















