

Python:中医病理分析
实验目的
1. 借助患者病理信息,发现中医症状间的关联关系和诸多症状间的规律性,
2. 并且依据规则分析病因、预测病情发展以及为未来临床诊治提供有效借鉴。
实验要求
1. 熟练应用关联规则算法 Apriori
2. 掌握 pandas、scipy、matplotlib、sklearn 等模块的使用
3. 掌握数据离散和聚类
4. 本实验不需要外网连接
实验原理
本案例的目标是探索乳腺癌患者 TNM 分期与中医症型系数之间的关系,因此采用关联规
则算法,挖掘它们之间的关联系数。关联规则算法主要用于寻找数据集中项之间的关联关
系。它揭示了数据项间的未知关系,基于样本的统计规律,进行关联规则挖掘。根据所挖
掘的关联关系,可以从一个属性的信息来推断另一个属性的信息。当置信度达到某一阈值
时,就可以认为规则成立。
本实验使用 Apriori 算法它是经典的挖掘频繁项集和关联规则的数据挖掘算法。该算法使用
频繁项集性质的先验性质,即频繁项集的所有非空子集也一定是频繁的。Apriori 算法使用
一种称为逐层搜索的迭代方法,其中 k 项集用于探索(k+1)项集。首先,通过扫描数据库,
累计每个项的计数,并收集满足最小支持度的项,找出频繁 1 项集的集合。该集合记为
L1。然后,使用 L1 找出频繁 2 项集的集合 L2,使用 L2 找出 L3,如此下去,直到不能再
找到频繁 k 项集。每找出一个 Lk 需要一次数据库的完整扫描。Apriori 算法使用频繁项集的
先验性质来压缩搜索空间。
实验步骤
第 1 步:
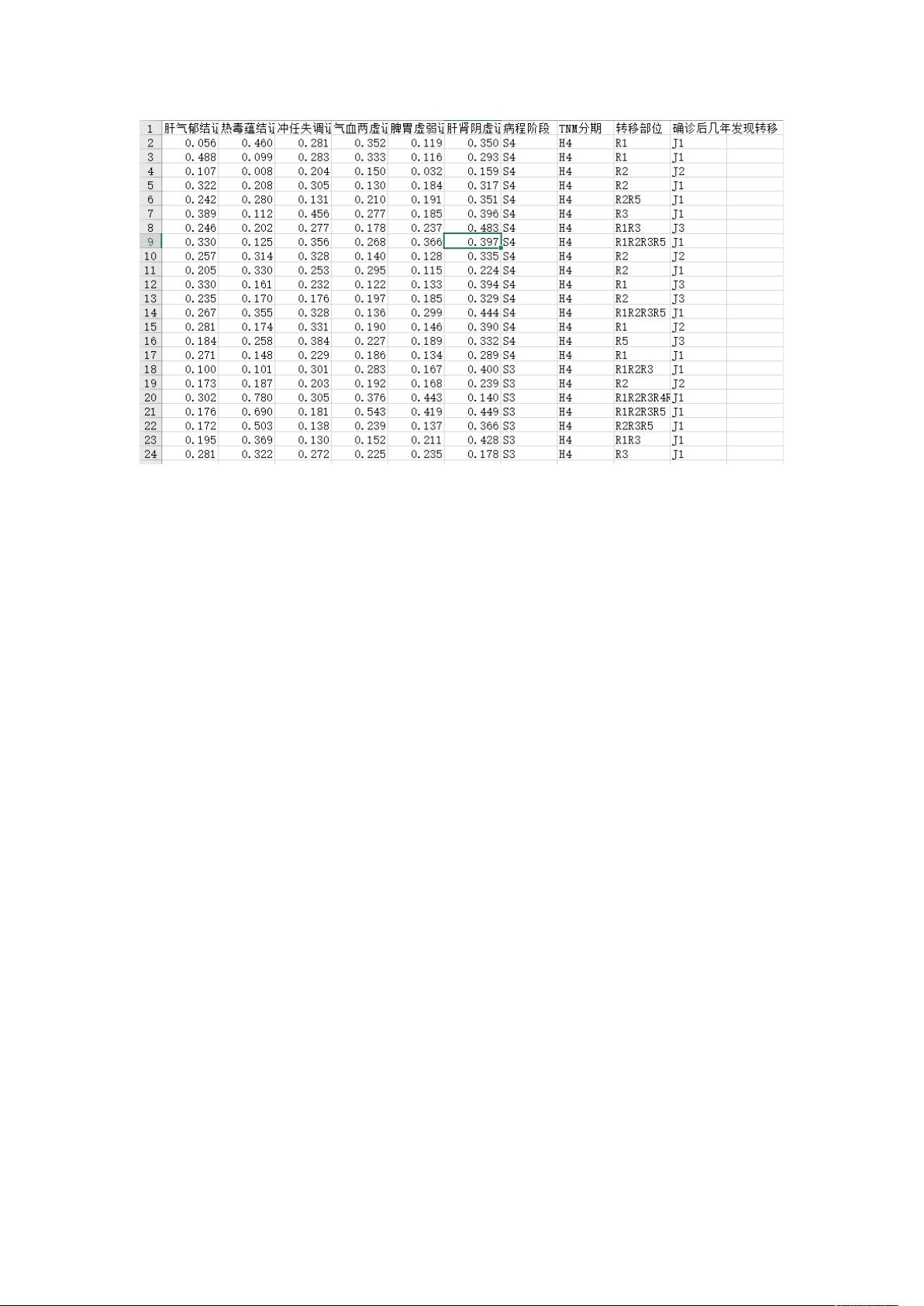
数据预处理É
首先从数据集中读取数据 data.xls。É这里采用证型系数代替具体单证型的证素得分,证型
系数=该证型得分/该证型总分。将 data.xls 保存到虚拟机 root 目录下。数据内容如下图
剩余9页未读,继续阅读
资源评论


ITBZNMG
- 粉丝: 1
- 资源: 2









最新资源
- 白色风格的购物商城网站模板下载.zip
- 白色风格的后台管理模板整站下载.zip
- 白色风格的后台管理系统模板下载.rar
- 白色风格的生活社区网站模板下载.zip
- 白色风格的商务网站模板下载.rar
- 白色风格的手机网站模板下载.rar
- 白色风格的直播平台模板整站下载.zip
- 白色大气风格的商务会议活动模板下载.rar
- 白色大气风格的商务网站模板下载.rar
- 白色大气风格的商务团队公司模板下载.zip
- 白色大气风格的商业办公楼租赁模板下载.zip
- 白色大气风格的商业html5模板.zip
- 白色大气风格的商务英语学习培训网站模板.zip
- 白色大气风格的商业公司模板下载.zip
- 白色大气风格的商业代理公司模板下载.zip
- 白色大气风格的商业策划公司模板下载.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


