
ChatGPT 的实际工作方式
自发布以来,公众一直在玩 ChatGPT,看看它能做什么,但 ChatGPT 究竟是如何工作的
呢?虽然其内部运作的细节尚未公布,但我们可以从最近的研究中拼凑出它的运作原理。
ChatGPT 是 OpenAI 的最新语言模型,比其前身 GPT-3 有了重大改进。与许多大型语言
模型类似,ChatGPT 能够为不同目的生成多种样式的文本,但具有更高的精确度、细节和
连贯性。它代表了 OpenAI 大型语言模型系列的下一代产品,其设计非常注重交互式对
话。
创建者结合使用监督学习和强化学习来微调 ChatGPT,但正是强化学习组件使 ChatGPT
独一无二。创作者使用一种称为人类反馈强化学习 (RLHF) 的特殊技术,该技术在训练循
环中使用人类反馈来最大限度地减少有害、不真实和/或有偏见的输出。
在了解 RLHF 的工作原理和了解 ChatGPT 如何使用 RLHF 来克服这些问题之前,我们
将研究 GPT-3 的局限性以及它们如何源于其训练过程。最后,我们将研究这种方法的一
些局限性。
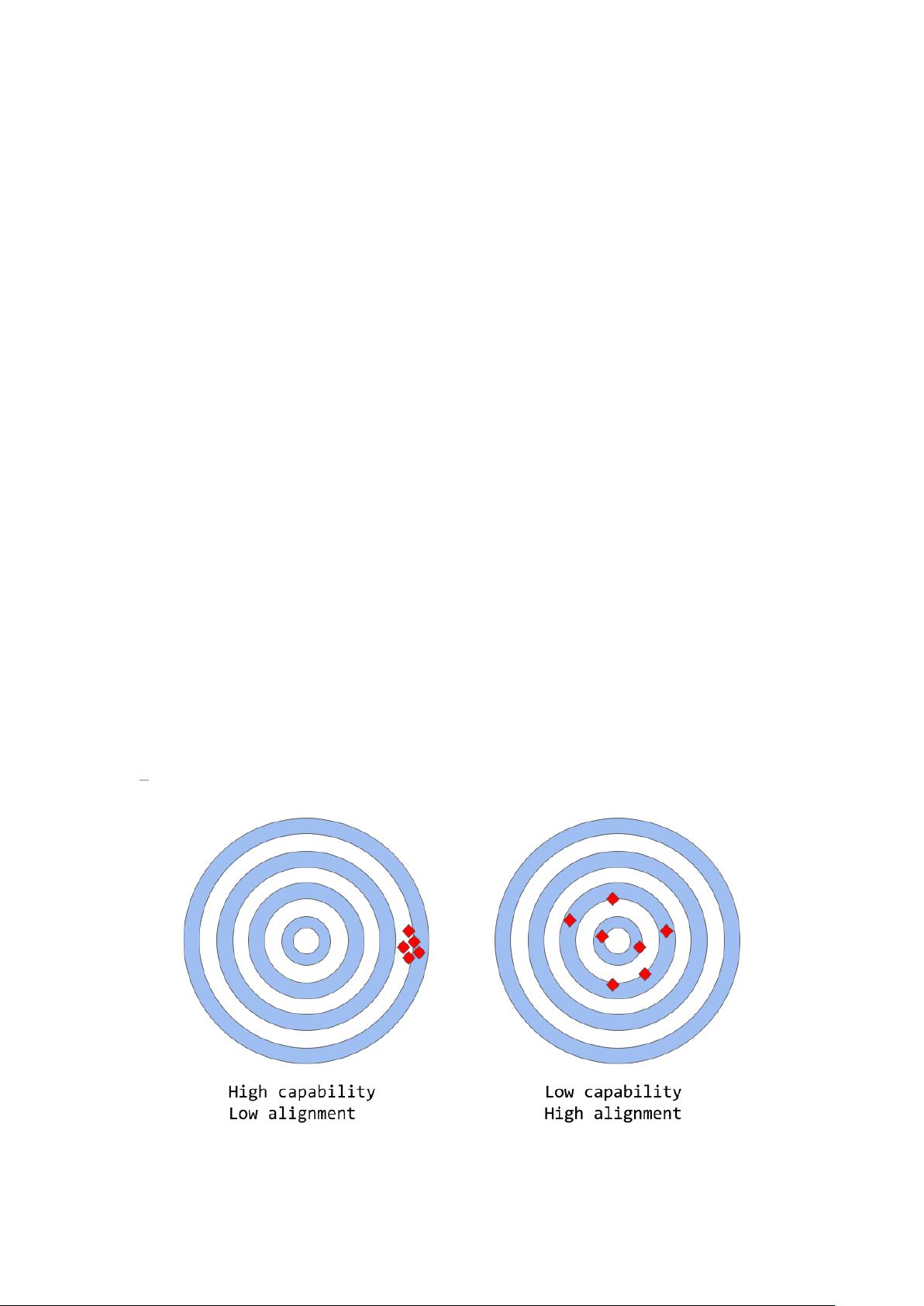
#大型语言模型中的能力与对齐
“对齐与能力”可以被认为是“准确性与精确度”的更抽象的类比

剩余11页未读,继续阅读
资源评论


沐风老师
- 粉丝: 1w+
- 资源: 491









最新资源
- 基于java的教学资料管理系统的设计和实现.docx
- 基于java的老年人体检管理系统的设计和实现.docx
- 基于java的旅游推荐系统的设计和实现.docx
- 基于java的旅游网站的设计和实现.docx
- 基于java的美妆购物网站的设计和实现.docx
- 基于java的绿城郑州爱心公益网站的设计和实现.docx
- 基于java的民宿管理系统的设计和实现.docx
- 基于java的民族婚纱预定系统的设计和实现.docx
- 基于java的民谣网站的设计和实现.docx
- 基于java的企业信息管理系统的设计和实现.docx
- 基于java的企业OA管理系统的设计和实现.docx
- 基于java的农产品直卖平台的设计和实现.docx
- 基于java的汽车维修预约服务系统的设计和实现.docx
- 基于java的汽车租赁系统的设计和实现.docx
- 基于java的汽车销售系统的设计和实现.docx
- 基于java的社区医疗综合服务平台的设计和实现.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


