
ChatGPT的原理分析

需积分: 0 12 浏览量
更新于2023-04-17
收藏 405KB DOCX 举报
ChatGPT是一种基于Transformer架构的语言模型,采用了自监督学习的方式进行预训练,然后可以用于各种自然语言处理任务,如文本生成、机器翻译、问答系统等。
具体来说,ChatGPT使用了一种称为Transformer的神经网络结构,它是一种基于自注意力机制的模型,可以对输入的序列进行编码和解码。在预训练阶段,ChatGPT使用了一个无监督的语言建模任务,即给定一个文本序列中的一部分,预测序列中缺失的部分。这个任务被称为掩码语言建模(Masked Language Modeling,MLM),它可以帮助模型学习上下文信息和语言规则。
在预训练完成后,ChatGPT可以通过微调的方式应用于各种自然语言处理任务。例如,在文本生成任务中,可以给定一个开始的文本序列,然后使用ChatGPT来生成接下来的文本;在问答系统中,可以将问题和文本序列作为输入,然后使用ChatGPT来预测答案。
总的来说,ChatGPT的原理是基于Transformer架构的语言模型,通过自监督学习的方式进行预训练,然后可以用于各种自然语言处理任务。
ChatGPT是OpenAI开发的一款基于Transformer架构的先进语言模型,其主要原理在于利用自监督学习的方法进行预训练,以实现各种自然语言处理任务。ChatGPT的核心是Transformer神经网络结构,这是一种基于自注意力机制的模型,能有效地处理输入序列的编码和解码。在预训练阶段,ChatGPT采用掩码语言建模(MLM)任务,即部分隐藏输入序列,让模型预测被遮蔽部分的内容,从而学习到上下文信息和语言规则。
预训练完成后,ChatGPT可通过微调适应不同的任务需求,如文本生成、机器翻译和问答系统等。在文本生成中,模型可根据给定的起始文本继续生成连贯的内容;在问答系统中,模型接收问题和文本上下文,然后预测出合适的答案。
相较于前代模型GPT-3,ChatGPT在交互性和性能上有显著提升。OpenAI采用了监督学习和强化学习的结合,特别是“人类反馈强化学习”(RLHF)的训练方法,以提高模型的响应质量和一致性。RLHF通过收集人类对模型输出的反馈,调整模型的训练目标,使得模型的输出更加符合人类的期望和价值观。这样,ChatGPT不仅能生成准确、详细的文本,还能在上下文连贯性和一致性方面表现出色。
然而,大型语言模型如GPT-3和ChatGPT仍然存在一致性问题。尽管这些模型在预测下一个单词的概率分布方面很强大,但它们的训练目标与实际应用场景之间存在差距。这种不一致性可能导致模型在某些情况下提供无效的帮助、创造不实的信息、难以解释其决策过程,甚至输出有偏见的内容。这些问题的根源在于语言模型的训练策略,如next-token-prediction和masked-language-modeling,它们虽然有助于学习语言的统计结构,但也可能导致模型无法区分重要错误和不重要错误。
为了改进这个问题,OpenAI的RLHF方法引入了人类反馈,让模型在实际应用中学习并调整其行为。通过不断迭代和优化,ChatGPT能够更好地理解和遵循人类的期望,从而提供更可靠、更有价值的服务。然而,这种方法也有限制,如训练成本高、可能存在过拟合风险以及仍可能存在的潜在偏见问题。
ChatGPT作为一款先进的自然语言处理模型,其原理和优化策略旨在克服传统语言模型的局限性,通过强化学习和人类反馈来提高一致性。尽管如此,持续的挑战在于如何平衡模型的能力和一致性,确保它们在实际应用中既能产出高质量文本,又能满足人类的期望和价值观。随着人工智能技术的发展,未来的语言模型将进一步提升其交互性和实用性,更好地服务于人类社会。
自 ChatGPT 发布以来,已经吸引了无数人一探究竟。但 ChatGPT 实际上是如何工作的?尽
管它内部实现的细节尚未公布,我们却可以从最近的研究中一窥它的基本原理。
ChatGPT 是 OpenAI 发布的最新语言模型,比其前身 GPT-3 有显著提升。与许多大型语言模型类似,
ChatGPT 能以不同样式、不同目的生成文本,并且在准确度、叙述细节和上下文连贯性上具有更优的表现。
它代表了 OpenAI 最新一代的大型语言模型,并且在设计上非常注重交互性。
OpenAI 使用监督学习和强化学习的组合来调优 ChatGPT,其中的强化学习组件使 ChatGPT 独一无二。
OpenAI 使用了「人类反馈强化学习」(RLHF)的训练方法,该方法在训练中使用人类反馈,以最小化无
益、失真或偏见的输出。
本文将剖析 GPT-3 的局限性及其从训练过程中产生的原因,同时将解释 RLHF 的原理和理解 ChatGPT
如何使用 RLHF 来克服 GPT-3 存在的问题,最后将探讨这种方法的局限性。
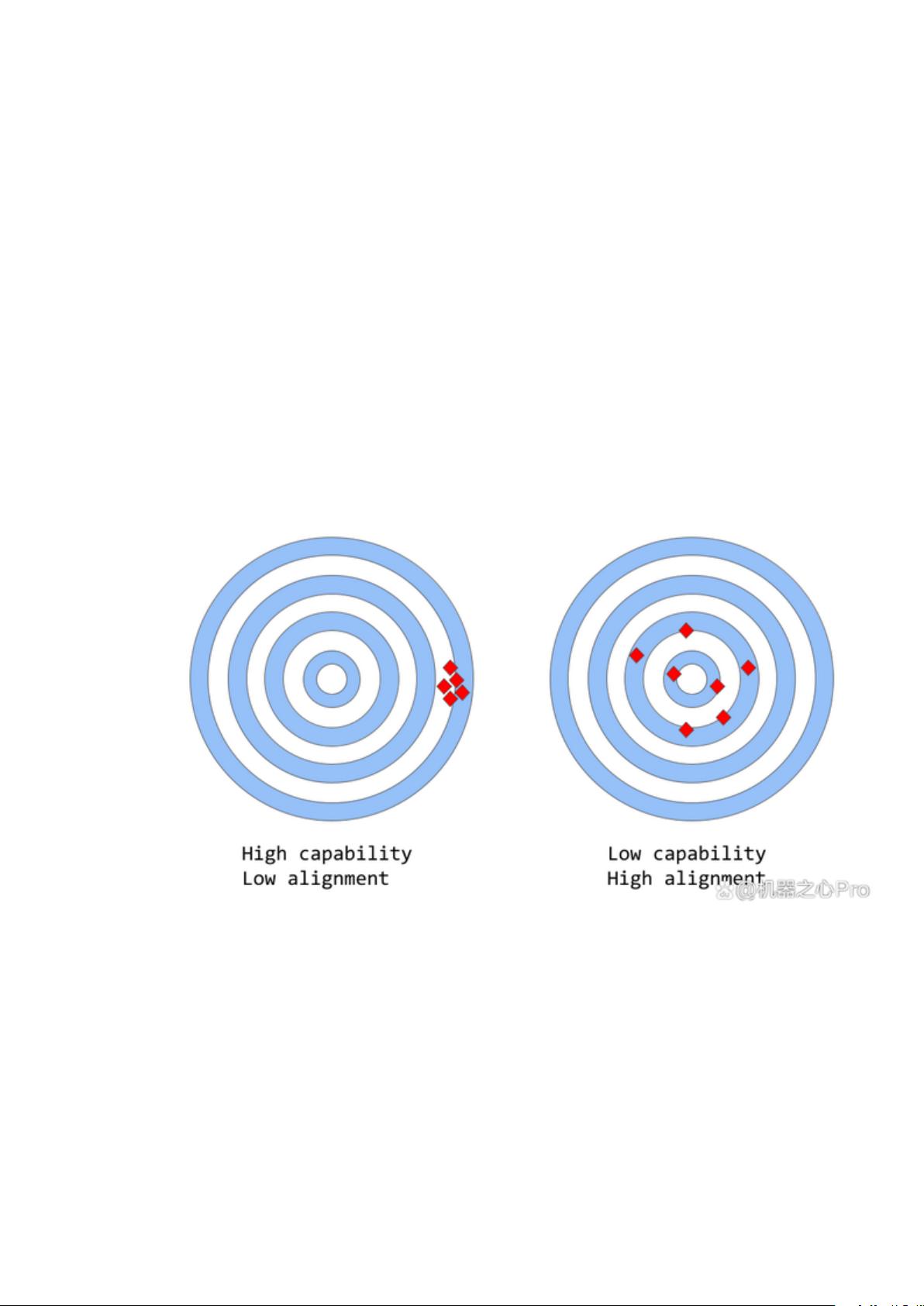
大型语言模型中的能力与一致性
「一致性 vs 能力」可以被认为是「准确性 vs 精确性」的更抽象的类比。
在机器学习中,模型的能力是指模型执行特定任务或一组任务的能力。模型的能力通常通过它能够优化其
目标函数的程度来评估。例如,用来预测股票市场价格的模型可能有一个衡量模型预测准确性的目标函数。
如果该模型能够准确预测股票价格随时间的变化,则认为该模型具有很高的执行能力。
一致性关注的是实际希望模型做什么,而不是它被训练做什么。它提出的问题是「目标函数是否符合预
期」,根据的是模型目标和行为在多大程度上符合人类的期望。假设要训练一个鸟类分类器,将鸟分类为
「麻雀」或「知更鸟」,使用对数损失作为训练目标,而最终目标是很高的分类精度。该模型可能具有较


剩余11页未读,继续阅读
2023-04-20 上传
198 浏览量
2023-04-17 上传
2023-04-18 上传
122 浏览量
151 浏览量
194 浏览量
118 浏览量
2023-10-06 上传
174 浏览量
104 浏览量
2023-03-16 上传
166 浏览量
195 浏览量
2023-12-27 上传
资源评论


菜鸟学识
- 粉丝: 4159
- 资源: 113









最新资源
- 基于PHP的FeelDesk工单管理系统开源版设计源码
- 基于Antv-X6的组态编辑器与可视化设计源码
- factoryio2.5工厂流水线仿真程序,期末专周可用,多个场景可以咨询 使用简单的梯形图与SCL语言编写,通俗易懂,起到抛砖引玉的作用,比较适合有动手能力的入门初学者 软件环境: 1、西门子编程
- 基于公有云平台的OpenIoT项目设计源码
- 基于微信小程序文件系统的MxLocalBase本地数据库设计源码
- 基于C语言的2023级寒假实践打地鼠游戏设计源码
- 基于matlab的孔入式静压轴承程序,进油孔数为4个,采用有限差分计算轴承油膜厚度及油膜压力 程序已调通,可直接运行
- 控制电机-感应电动机转差型矢量控制伺服模型系统 仿真模型+实验报告(内附实验参数,仿真波形等) 注意:matlab版本需在2016a以下,否则可能打不开
- 控制电机-正弦波永磁同步电动机矢量控制系统仿真 仿真模型+实验报告(内附实验参数,仿真波形等) 注意:matlab版本需在2016a以下,否则可能打不开
- 基于扰动观测器的永磁同步电机(PMSM)模型预测控制(MPC)仿真 速度外环基于模型预测控制、电流内环基于无差拿控制搭建,控制效果理想,模块程序设计通俗易通
- 基于Laravel的简化Smarty模板引擎设计源码
- NSGA2遗传算法多目标优化 三维视图 寻优多个函数(函数类型见图二类型),出图为三维红色为帕列托(图一), 带最终结果图(图三)
- 基于graqhql/mongodb/nodejs/nuxtjs的Vue跨世代实时在线文档编辑系统设计源码
- 基于Java的用户线程模型设计源码
- 基于Rust Axum框架的Web后端项目设计与源码实践
- 基于HTML、CSS和JavaScript的eui后台UI框架设计源码预览版账号密码提供
