

强化学习入门及其实现代码
chen_h
介绍
目前,对于全球科学家而言,“如何去学习一种新技能”成为了一个最基本的研究问题。为
什么要解决这个问题的初衷是显而易见的,如果我们理解了这个问题,那么我们可以使
人类做一些我们以前可能没有想到的事。或者,我们可以训练去做更多的“人类”工作,常
遭一个真正的人工智能时代。
虽然,对于上述问题,我们目前还没有一个完整的答案去解释,但是有一些事情是可以
理解的。先不考虑技能的学习,我们首先需要与环境进行交互。无论我们是学习驾驶汽
车还是婴儿学习走路,学习都是基于和环境的相互交互。从互动中学习是所有智力发展
和学习理论的基础概念。
强化学习
今天,我们将探讨强化学习,这是一种基于环境相互交互的学习算法。有些人认为,强
化学习是实现强人工智能的真正希望。这种说法也是正确的,因为强化学习所拥有的潜
力确实是巨大的。
目前,有关强化学习的研究正在快速增长,人们为不同的应用程序生成各种各样的学习
算法。因此,熟悉强化学习的技术就变得尤其重要了。如果你还不是很熟悉强化学习,
那么我建议你可以去看看我以前有关强化学习文章和一些开源的强化学习平台。
一旦你已经掌握和理解了强化学习的基础知识,那么请继续阅读这篇文章。读完本文之
后,你会对强化学习有一个透彻的了解,并且会进行实际代码实现。
目录
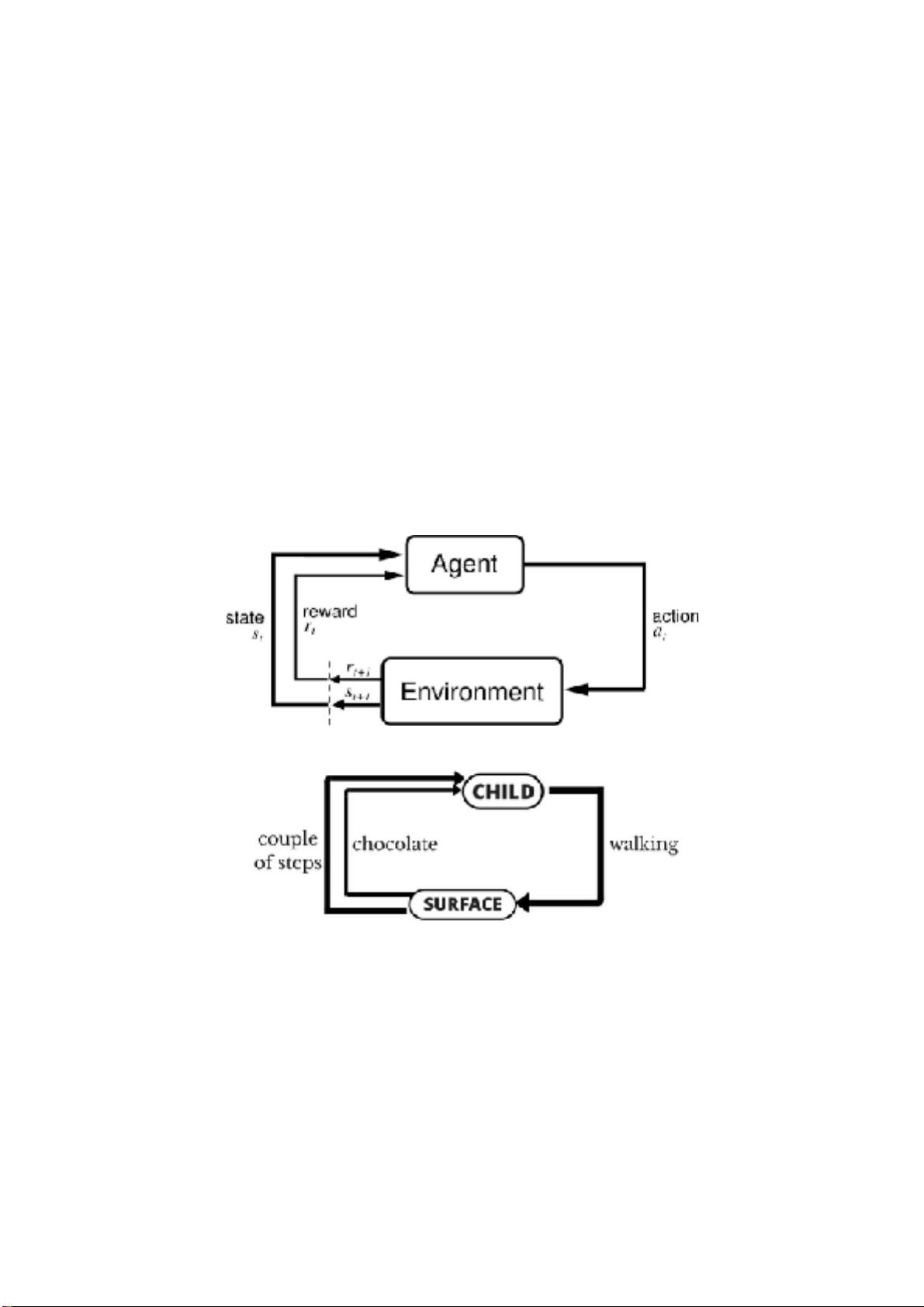
1.确定一个强化学习问题
2.与其他机器学习方法的比较
3.解决强化问题的框架

剩余13页未读,继续阅读
资源评论

 yaqianmaizi2019-03-20比较基础,学习还是不错的。
yaqianmaizi2019-03-20比较基础,学习还是不错的。
mqyqingkong
- 粉丝: 0
- 资源: 1









最新资源
- 基于HX711&STM32的压力传感器详细文档+全部资料+高分项目.zip
- 基于Linux的kfifo移植到STM32详细文档+全部资料+高分项目.zip
- 基于OneNet的stm32环境监测系统详细文档+全部资料+高分项目.zip
- 基于IMU和STM32的独轮自平衡机器人详细文档+全部资料+高分项目.zip
- 基于STLinkV21的STM32编程器和flash烧写器详细文档+全部资料+高分项目.zip
- 基于openmv+stm32的二维云台追踪系统详细文档+全部资料+高分项目.zip
- mmexport1735006369325.png
- mmexport1735006372544.png
- 基于STM32 HAL库的FOC封装详细文档+全部资料+高分项目.zip
- 基于stm32,cubemx,hal库的简易任务轮询,任务调度系统详细文档+全部资料+高分项目.zip
- 用python实现贪吃蛇
- wifi软件计算机基础 第二套(1).7z
- 美国国家健康与营养调查(NHANES).zip
- 基于stm32+fpgaecon位置模块详细文档+全部资料+高分项目.zip
- IT服务器,路由器等命令行式设备维护-命令行批量操作工具-免费分享
- 基于STM32、ESP8266、EMQX和Android的智能家居系统详细文档+全部资料+高分项目.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


