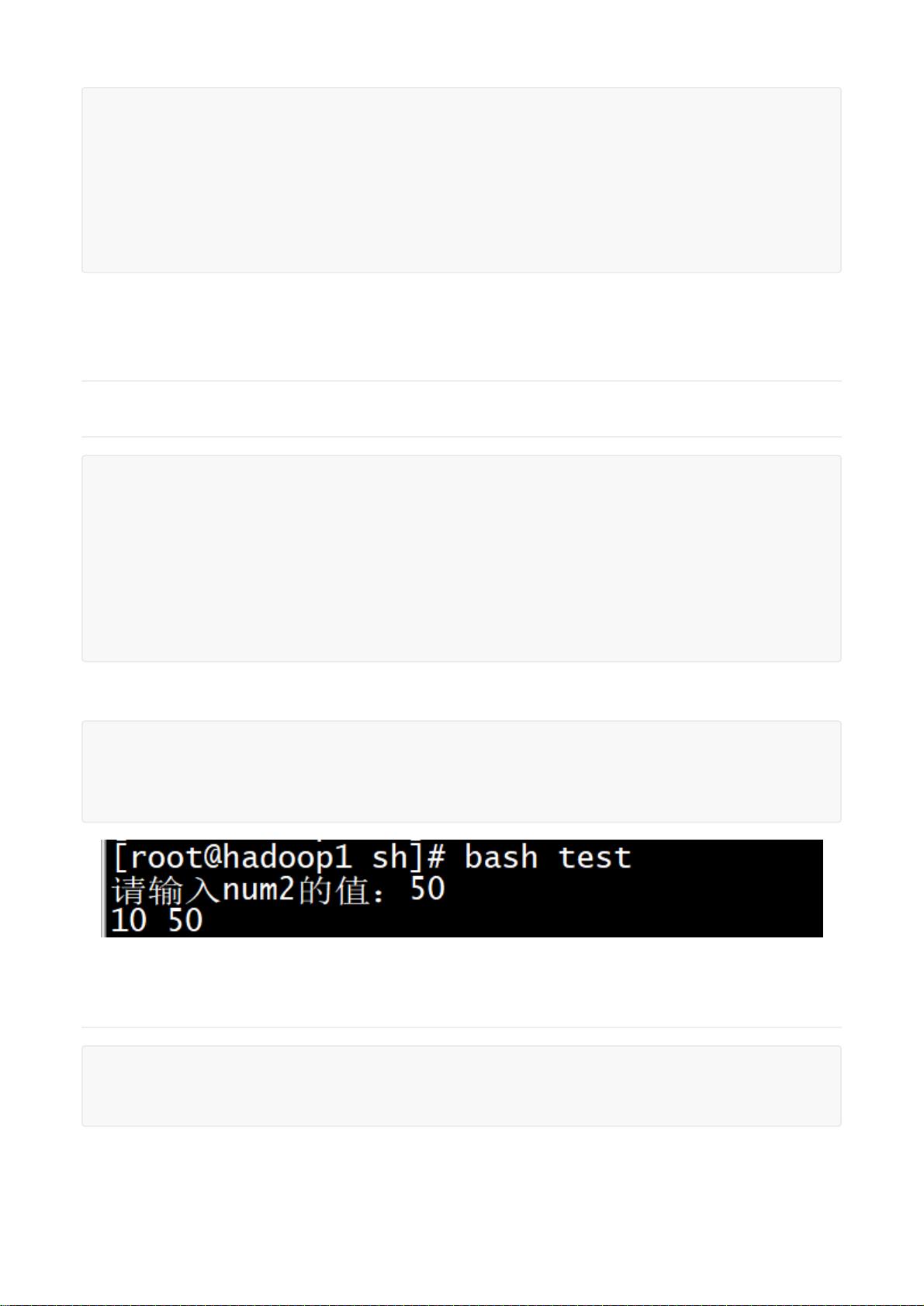
判断方式:
[] (一般和if循环语句配合使用)
格外注意:
中括号内左右两侧必须加空格!!!
如果要和if配合使用,if和[]之间也要加空格!!!
判断数字大小:
-eq 判断相等,相等返回true,否则返回false
-ne 判断是否不相等,不相等返回true,否则返回false
-gt 判断左边是否大于右边的值,大于则返回true,否则返回false
-lt 判断左边是否小于右边的值,小于则返回true,否则返回false
-ge 判断左边是否大于或等于右边的值,大于则返回true,否则返回false
-le 判断左边是否小于右边的值,小于则返回true,否则返回false