大数据原理与应用课程设计
需积分: 0 96 浏览量
2023-06-24
11:08:26
上传
评论 3
收藏 6.74MB DOCX 举报


大数据课程综合实验案例
1.案例目的
1) 熟悉 Linux 系统、MySQL、Hadoop、HBase、Hive、R、Eclipse 等系统和软件的安
装和使用;
2) 了解大数据处理的基本流程;
3) 熟悉数据预处理方法;
4) 熟悉在不同类型数据库之间进行数据相互导入导出;
5) 熟悉使用 R 语言进行可视化分析;
6) 熟悉使用 Eclipse 编写 Java 程序操作 HBase、Hive 和 MySQL。
2.预备知识
需要案例使用者,已经学习过大数据相关课程(比如入门级课程《大数据技术原理与应
用》),了解大数据相关技术的基本概念与原理,了解 Windows 操作系统、Linux 操作系统、
大数据处理架构 Hadoop 的关键技术及其基本原理、列族数据库 HBase 概念及其原理、数
据仓库概念与原理、关系型数据库概念与原理、R 语言概念与应用等。
3.时间安排
建议一周左右完成案例内容
4.硬件要求
本案例可以在单机上完成,也可以在集群环境下完成。单机上完成本案例实验时,建议
计算机硬件配置为:50GB 以上硬盘,8GB 以上内存。
5.软件工具
1) Linux: Ubuntu16.04(或 18.04)
2) MySQL: 5.7.29
3) Hadoop: 3.1.3
4) HBase:2.2.2
5) Hive:3.1.2
6) R:3.2.3
7) Eclipse:3.8
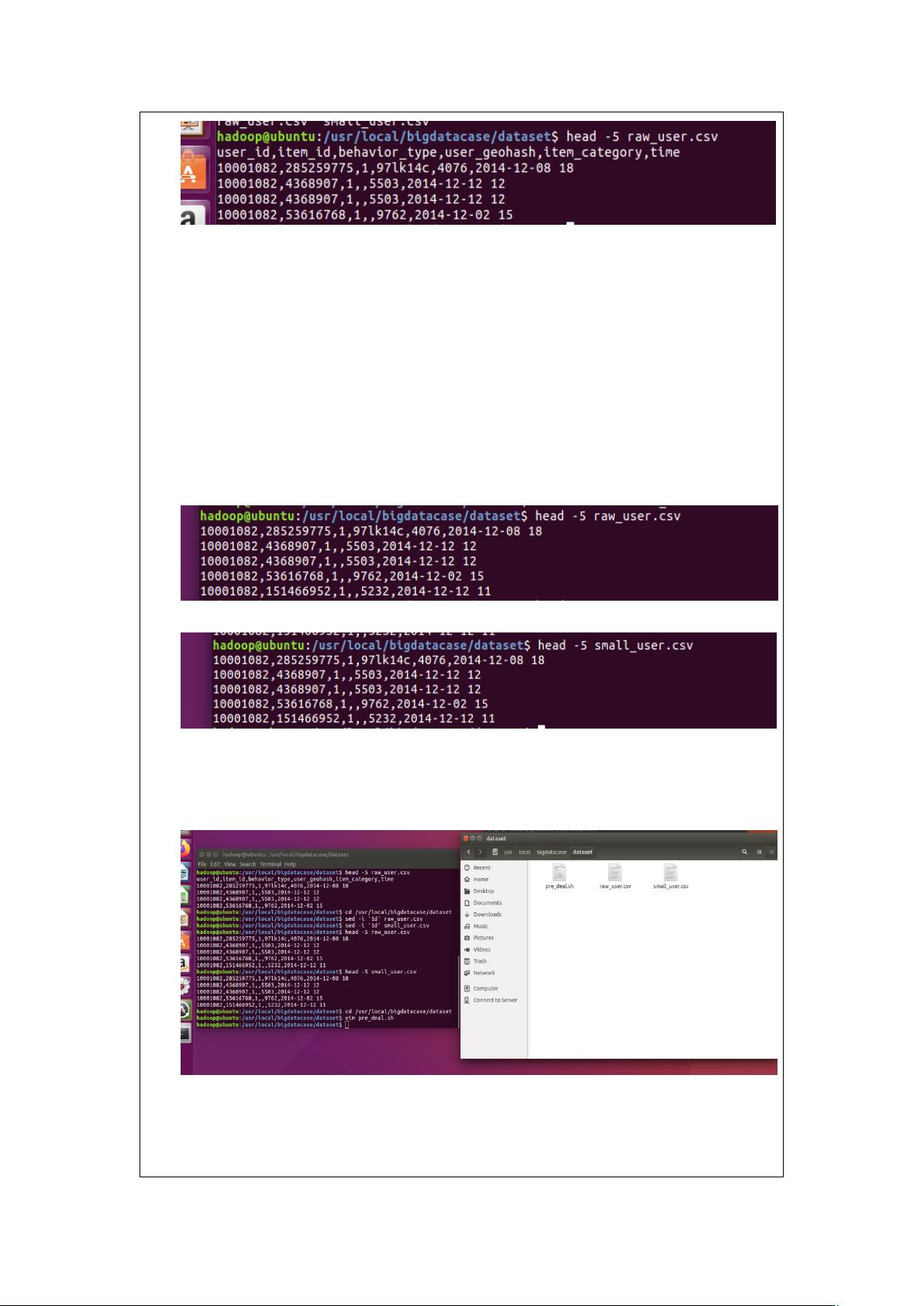
6.数据集
见 PPT 或者资料。



剩余33页未读,继续阅读
资源评论













