exp6.pdf

需积分: 0 113 浏览量
更新于2023-03-19
收藏 1.63MB PDF 举报
基于集成学习的 Amazon 用户评论质量预测
一、案例简介
随着电商平台的兴起,以及疫情的持续影响,线上购物在我们的日常生活中扮演着越来越重要的角色。在进行线上商品挑选时,评论往往是我们十分关注的一个方面。然而目前电商网站的评论质量参差不齐,甚至有水军刷好评或者恶意差评的情况出现,严重影响了顾客的购物体验。因此,对于评论质量的预测成为电商平台越来越关注的话题,如果能自动对评论质量进行评估,就能根据预测结果避免展现低质量的评论。
二、作业说明
本案例中需要大家完成两种集成学习算法的实现(Bagging、AdaBoost.M1),其中基分类器要求使用 SVM 和决策树两种,因此,一共需要对比四组结果(AUC 作为评价指标):Bagging + SVM、Bagging + 决策树、AdaBoost.M1 + SVM、AdaBoost.M1 + 决策树。注意集成学习的核心算法需要手动进行实现,基分类器可以调库。
基本要求:
1. 根据数据格式设计特征的表示
2. 汇报不同组合下得到的 AUC
3. 结合不同集成学习算法的特点分析结果之间的差异
扩展要求:
1. 尝试其他基分类器(如 k-NN、朴素贝叶斯)
2. 分析不同特征的影响
3. 分析集成学习算法参数的影响
三、数据概览
本次数据来源于 Amazon 电商平台,包含超过 50,000 条用户在购买商品后留下的评论,各列的含义如下:
1. reviewerID:用户 ID
2. asin:商品 ID
3. reviewText:英文评论文本
4. overall:用户对商品的打分(1-5)
5. votes_up:认为评论有用的点赞数(只在训练集出现)
6. votes_all:该评论得到的总评价数(只在训练集出现)
7. label:评论质量的 label,1 表示高质量,0 表示低质量(只在训练集出现)
评论质量的 label 来自于其他用户对评论的 votes,votes_up/votes_all ≥ 0.9 的作为高质量评论。
四、比赛提交格式
课程页面:https://aistudio.baidu.com/aistudio/education/dashboard
提交文件需要对测试集中每一条评论给出预测为高质量的概率,每行包括一个 Id(和测试集对应)以及预测的概率 Predicted(0-1 的浮点数),用逗号分隔。
示例提交格式如下:
Id,Predicted
0,0.9
1,0.45
2,0.78
...
命名为 result.csv
五、实验报告
基于集成学习的 Amazon 用户评论质量预测
1. 数据预处理
1.1 数据集加载与概览
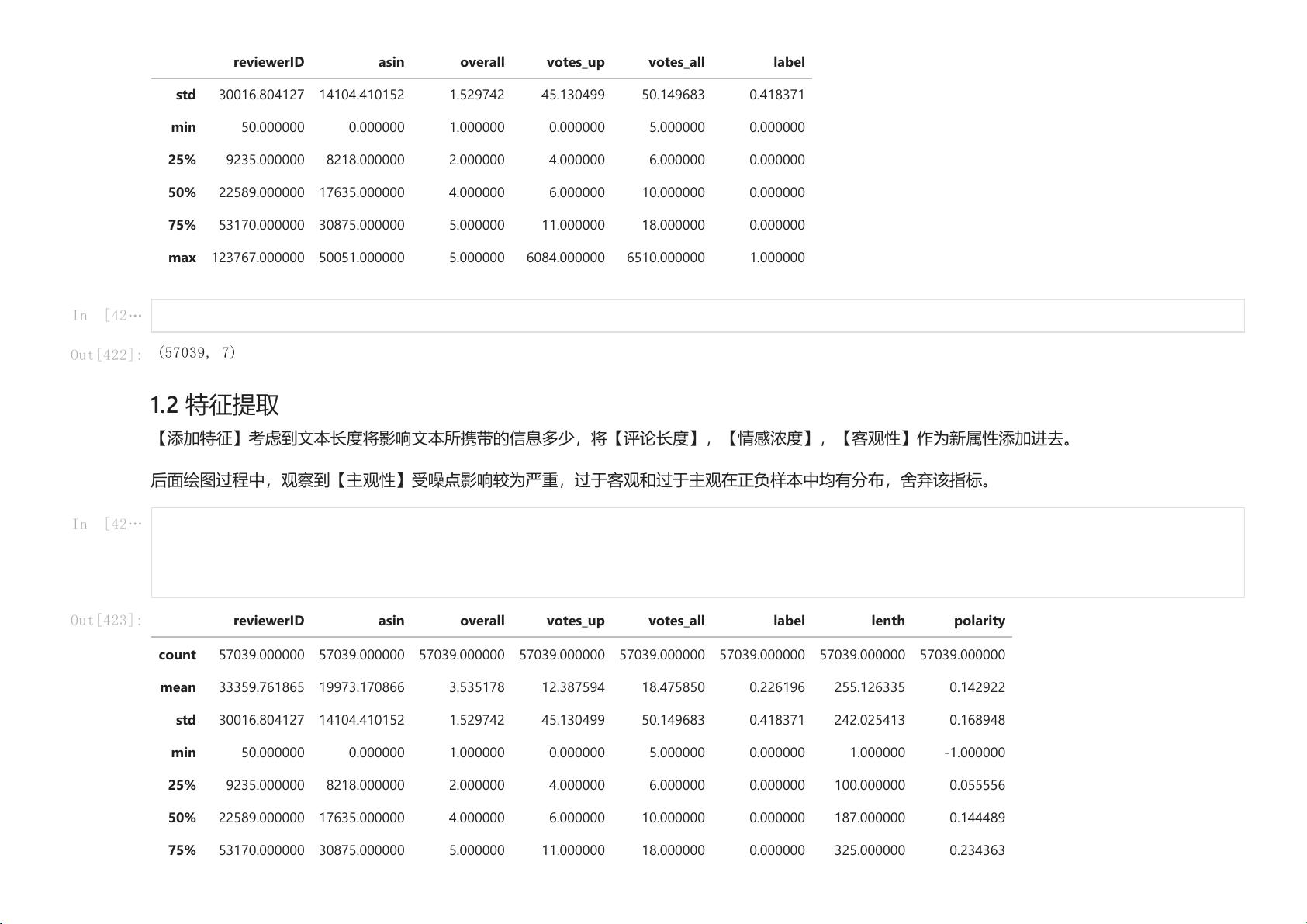
使用 Python 库 sklearn 和 pandas 对数据进行加载和概览,了解数据的基本信息,如数据维数、数据类型等。
1.2 数据预处理
使用 sklearn 库中的 CountVectorizer 和 TfidfVectorizer 对评论文本进行特征提取,并使用 StandardScaler 对数据进行标准化。
2. 集成学习算法实现
2.1 Bagging 算法实现
使用 sklearn 库中的 BaggingClassifier 实现 Bagging 算法,并使用 SVM 和决策树作为基分类器。
2.2 AdaBoost.M1 算法实现
使用 sklearn 库中的 AdaBoostClassifier 实现 AdaBoost.M1 算法,并使用 SVM 和决策树作为基分类器。
3. 结果分析
使用 AUC 作为评价指标,比较四组结果的差异,并分析不同集成学习算法的特点和影响。
4. 扩展分析
尝试其他基分类器(如 k-NN、朴素贝叶斯),分析不同特征的影响和集成学习算法参数的影响。

Exp6: 基于集成学习的 Amazon 用户评论质量预测
一、案例简介
随着电商平台的兴起,以及疫情的持续影响,线上购物在我们的日常生活中扮演着越来越重要的角色。在进行线上商品挑选时,评论往往是我们十分关
注的一个方面。然而目前电商网站的评论质量参差不齐,甚至有水军刷好评或者恶意差评的情况出现,严重影响了顾客的购物体验。因此,对于评论质
量的预测成为电商平台越来越关注的话题,如果能自动对评论质量进行评估,就能根据预测结果避免展现低质量的评论。本案例中我们将基于集成学习
的方法对 Amazon 现实场景中的评论质量进行预测。
二、作业说明
本案例中需要大家完成两种集成学习算法的实现(Bagging、AdaBoost.M1),其中基分类器要求使用 SVM 和决策树两种,因此,一共需要对比四组
结果(AUC 作为评价指标):
Bagging + SVM
Bagging + 决策树
AdaBoost.M1 + SVM
AdaBoost.M1 + 决策树
注意集成学习的核心算法需要手动进行实现,基分类器可以调库。
基本要求
根据数据格式设计特征的表示
汇报不同组合下得到的 AUC
结合不同集成学习算法的特点分析结果之间的差异
(使用 sklearn 等第三方库的集成学习算法会酌情扣分)
扩展要求
尝试其他基分类器(如 k-NN、朴素贝叶斯)



剩余35页未读,继续阅读
2019-09-14 上传
2021-10-11 上传
2021-08-31 上传
143 浏览量
140 浏览量
2021-08-12 上传
184 浏览量
2009-04-18 上传
162 浏览量
2021-08-31 上传
116 浏览量
199 浏览量
119 浏览量
2021-08-31 上传
2021-08-31 上传
116 浏览量
2021-08-31 上传
资源评论


周鸭子的单刀
- 粉丝: 0
- 资源: 1









最新资源
- (1034828)仓库管理系统
- 基于ssm的学校招生系统源码(java毕业设计完整源码+LW).zip
- (176798438)大麦抢票.user.js
- 2- moo0视频压缩v1.24
- (178313820)SSM美食推荐系统小程序 源码77145.zip
- 电机磁环自动装配(sw18可编辑+工程图)全套设计资料100%好用.zip
- 基于ssm的“陕西农特产品”网络交易平台源码(java毕业设计完整源码+LW).zip
- (176791020)雷达系统的matlab仿真
- (178411024)LQG主动悬架 maltab simulink实现.zip
- 多盘离合器sw18可编辑全套设计资料100%好用.zip
- (12778634)近十年数学建模优秀论文
- 基于ssm的基金分析系统的设计与实现源码(java毕业设计完整源码+LW).zip
- 2- Windows Memory Cleaner v2.8 Win内存清理工具
- 圆圈体标志体检测7-YOLO(v5至v11)、VOC数据集合集.rar
- (178794814)MT5指标-双线MACD
- 多功能搬运机器人sw18可编辑全套设计资料100%好用.zip
