

The Llama 3 Herd of Models
Llama Team, AI @ Meta
1
1
A detailed contributor list can be found in the appendix of this paper.
Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a
new set of foundation models, called Llama 3. It is a herd of language models that natively support
multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with
405B parameters and a context window of up to 128K tokens. This paper presents an extensive
empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language
models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and
post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input
and output safety. The paper also presents the results of experiments in which we integrate image,
video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach
performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The
resulting models are not yet being broadly released as they are still under development.
Date: July 23, 2024
Website: https://llama.meta.com/
1 Introduction
Foundation models are general models of language, vision, speech, and/or other modalities that are designed
to support a large variety of AI tasks. They form the basis of many modern AI systems.
The development of modern foundation models consists of two main stages: (1) a pre-training stage in which
the model is trained at massive scale using straightforward tasks such as next-word prediction or captioning
and (2) a post-training stage in which the model is tuned to follow instructions, align with human preferences,
and improve specific capabilities (for example, coding and reasoning).
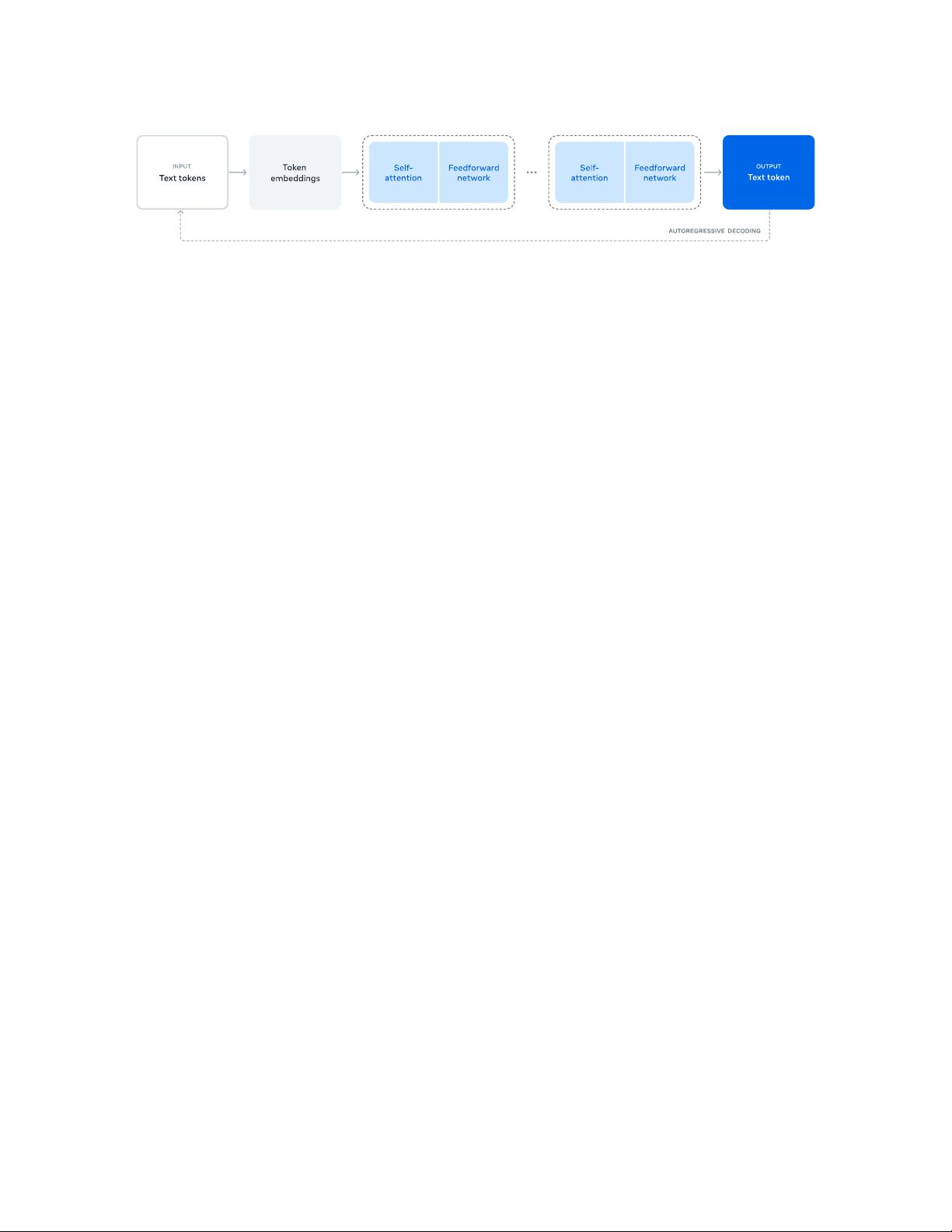
In this paper, we present a new set of foundation models for language, called Llama 3. The Llama 3 Herd
of models natively supports multilinguality, coding, reasoning, and tool usage. Our largest model is dense
Transformer with 405B parameters, processing information in a context window of up to 128K tokens. Each
member of the herd is listed in Table 1. All the results presented in this paper are for the Llama 3.1 models,
which we will refer to as Llama 3 throughout for brevity.
We believe there are three key levers in the development of high-quality foundation models: data, scale, and
managing complexity. We seek to optimize for these three levers in our development process:
•
Data. Compared to prior versions of Llama (Touvron et al., 2023a,b), we improved both the quantity and
quality of the data we use for pre-training and post-training. These improvements include the development
of more careful pre-processing and curation pipelines for pre-training data and the development of more
rigorous quality assurance and filtering approaches for post-training data. We pre-train Llama 3 on a
corpus of about 15T multilingual tokens, compared to 1.8T tokens for Llama 2.
•
Scale. We train a model at far larger scale than previous Llama models: our flagship language model was
pre-trained using 3
.
8
×
10
25
FLOPs, almost 50
×
more than the largest version of Llama 2. Specifically,
we pre-trained a flagship model with 405B trainable parameters on 15.6T text tokens. As expected per
1

剩余91页未读,继续阅读
资源评论


小稻虫
- 粉丝: 209
- 资源: 3









最新资源
- 10、安徽省大学生学科和技能竞赛A、B类项目列表(2019年版).xlsx
- 9、教育主管部门公布学科竞赛(2015版)-方喻飞
- C语言-leetcode题解之83-remove-duplicates-from-sorted-list.c
- C语言-leetcode题解之79-word-search.c
- C语言-leetcode题解之78-subsets.c
- C语言-leetcode题解之75-sort-colors.c
- C语言-leetcode题解之74-search-a-2d-matrix.c
- C语言-leetcode题解之73-set-matrix-zeroes.c
- 树莓派物联网智能家居基础教程
- YOLOv5深度学习目标检测基础教程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


