本地部署开源大模型的完整教程LangChain + Streamlit+ Llama
需积分: 5 52 浏览量
2023-09-23
12:38:06
上传
评论 3
收藏 1.98MB DOCX 举报

来源:DeepHub IMBA
在过去的几个月里,大型语言模型(llm)获得了极大的关注,这些模型创造了令
人兴奋的前景,特别是对于从事聊天机器人、个人助理和内容创作的开发人
员。
大型语言模型(llm)是指能够生成与人类语言非常相似的文本并以自然方式理解
提示的机器学习模型。这些模型使用广泛的数据集进行训练,这些数据集包括
书籍、文章、网站和其他来源。通过分析数据中的统计模式,LLM 可以预测给
定输入后最可能出现的单词或短语。
以上是目前的 LLM 的一个全景图。
背景知识
1、LangChain
LangChain 是一个令人印象深刻且免费的框架,它彻底改变了广泛应用的开发
过程,包括聊天机器人、生成式问答(GQA)和摘要。通过将来自多个模块的组
件无缝链接,LangChain 能够使用大部分的 llm 来创建应用程序。
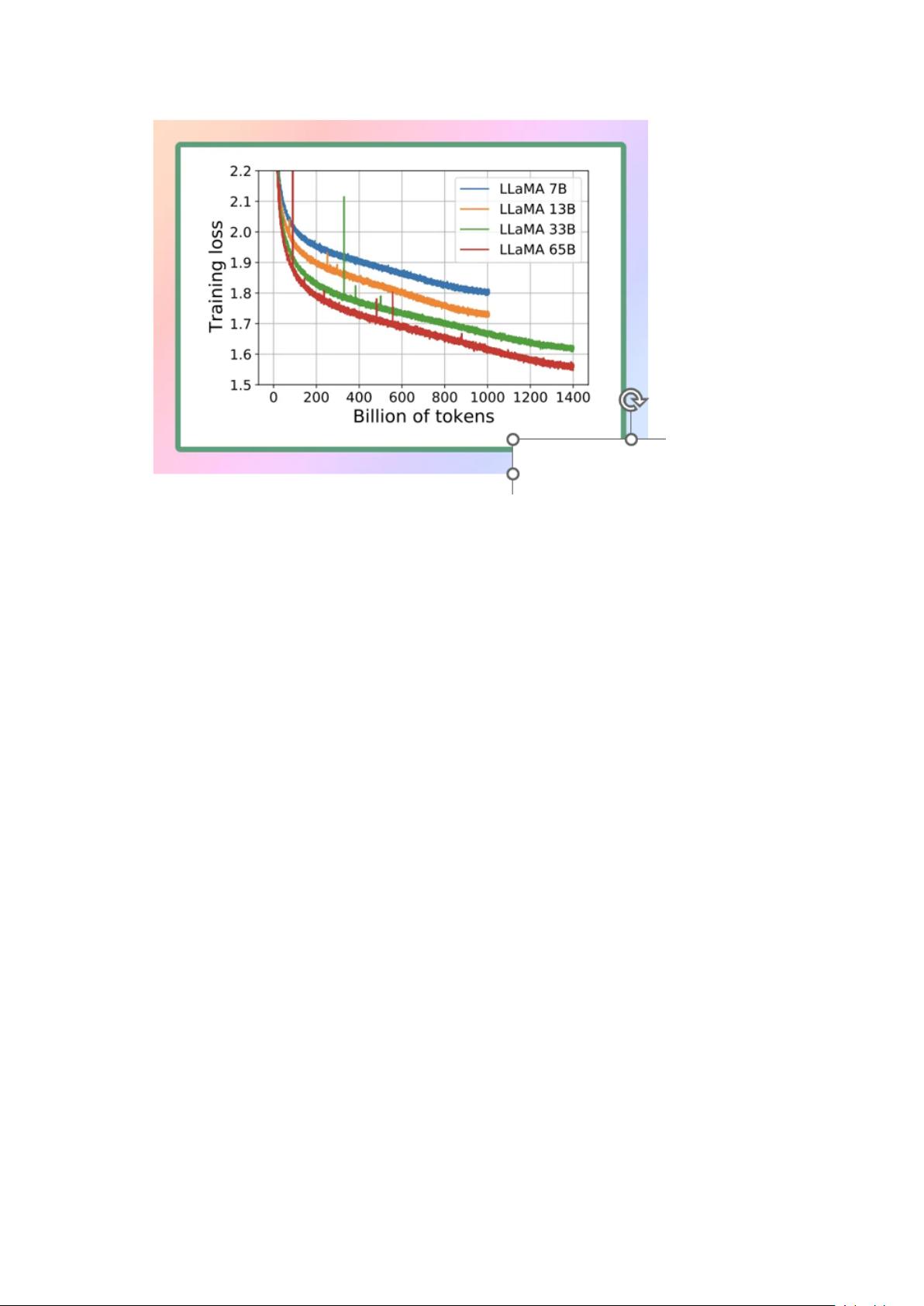
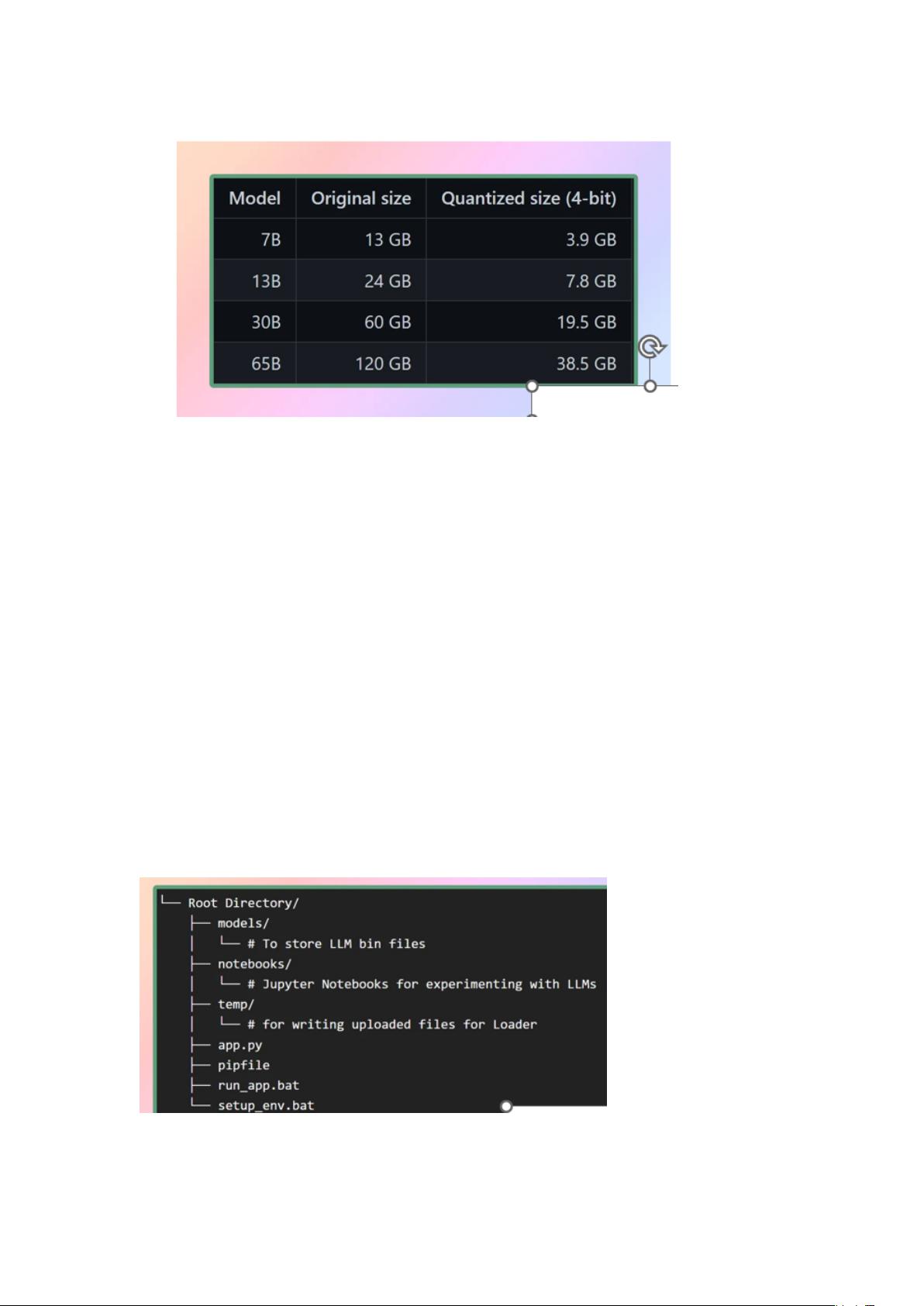
2、LLaMA
LLaMA 是由 Facebook 的母公司 Meta AI 设计的一个新的大型语言模型。
LLaMA 拥有 70 亿到 650 亿个参数的模型集合,是目前最全面的语言模型之
一。2023 年 2 月 24 日,Meta 向公众发布了 LLaMA 模型,展示了他们对开放
科学的奉献精神(虽然我们现在用的都是泄露版)。
剩余14页未读,继续阅读
资源评论













