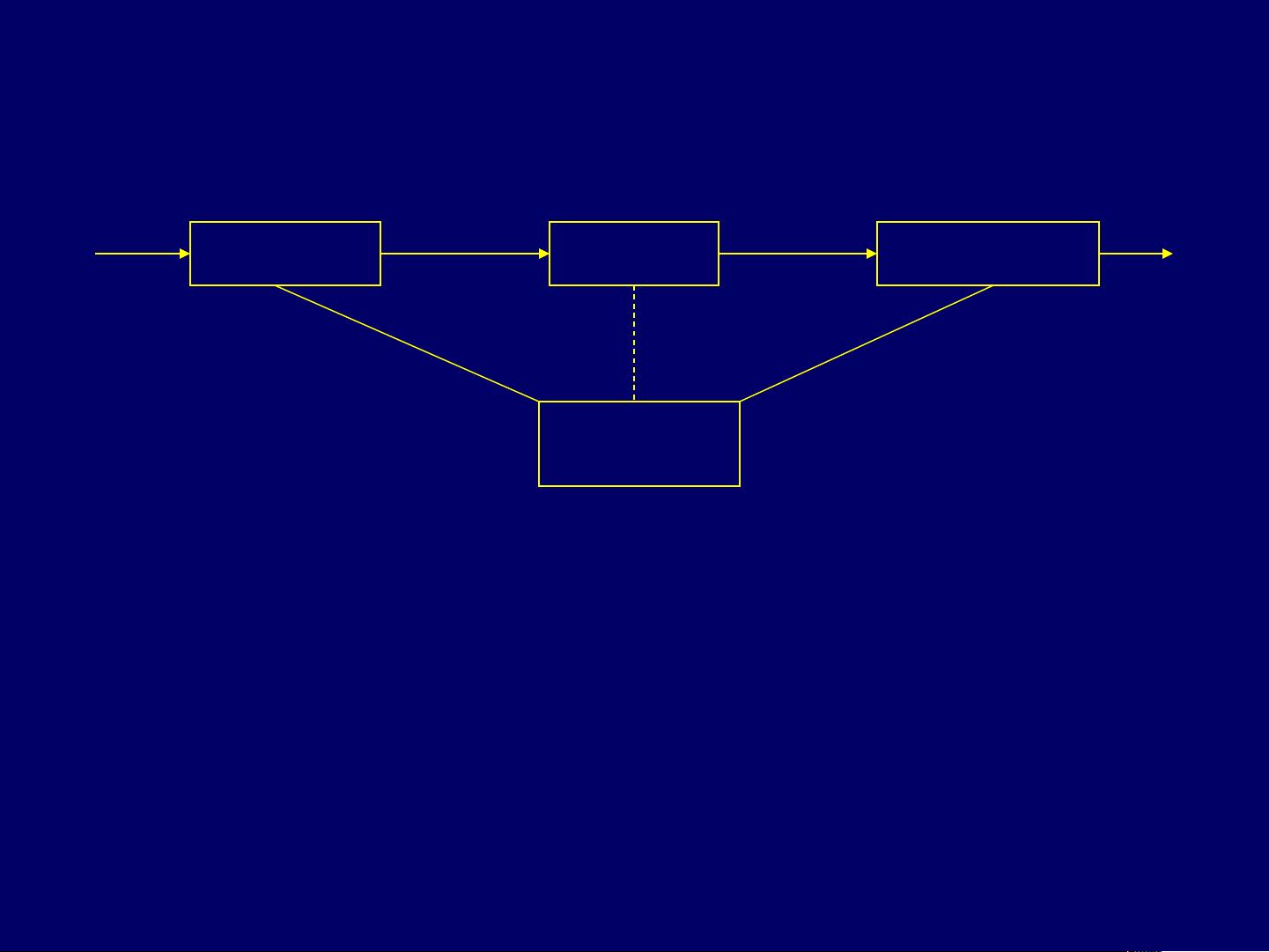
【目标代码生成器的位置】
在计算机程序的编译过程中,目标代码生成是至关重要的一步,它位于编译过程的后端。源代码首先通过编译前端解析和转换成中间代码,这是一种抽象的、与特定机器无关的语言。接着,经过代码优化阶段,中间代码会被进一步改进以提高效率。目标代码生成器将优化后的中间代码转化为特定机器能够执行的目标代码。
**目标代码的形式**
1. **已定位的可立即执行的机器语言代码**:这种形式的目标代码可以直接加载到内存中运行,因为它已经包含了所有必要的地址信息。
2. **可浮动的机器语言代码**:这种代码需要在运行前进行装配连接,以便解决外部引用和地址定位问题。
3. **汇编语言目标代码**:它是一种更高级别的表示,需要通过汇编器转换成机器语言才能执行。
**目标代码的高效性**
生成高效的目标代码是编译器的重要任务,目标代码应该尽可能短小,同时充分利用处理器的寄存器以减少对内存的访问,这可以显著提高程序的执行速度。
**简单的代码生成器**
以一个模拟机的指令系统为例,简单的代码生成策略包括:
1. 将中间代码逐条转换为等价的目标代码序列。
2. 在基本块内部优化,确保计算结果能尽可能长时间地保留在寄存器中,直到不再需要或者需要为其他计算腾出空间。
3. 当引用变量时,优先使用寄存器中的值,以避免不必要的内存访问。
**简化代码生成的策略**
在上述例子中,为了简化代码,我们需要跟踪变量在寄存器中的状态。为此,引入了以下概念:
1. **待用信息**:记录每个变量下次被引用的语句号,对于活跃变量保持其在寄存器中的状态,非活跃变量标记为“非待用”。
2. **活跃信息**:区分哪些变量在基本块内仍然活跃,哪些已经不活跃。
3. **寄存器描述数组**:存储每个寄存器当前承载的变量信息。
4. **变量地址描述数组**:记录变量在内存或寄存器中的状态。
**待用信息和活跃信息的构造算法**
1. 初始化时,将块内所有变量设为“非待用”,并根据它们在块出口后的使用情况设为“活跃”或“非活跃”。
2. 从出口逆向遍历语句,更新变量的状态,例如,对于赋值语句,更新左值和右操作数的待用信息和活跃信息,并更新它们在符号表中的状态。
通过这样的处理,我们可以准确地跟踪变量的使用情况,从而生成更高效的代码。每条语句都会包含变量的活跃信息和待用信息,使得编译器能更智能地决定何时将变量值保存在寄存器中,何时释放寄存器给其他计算使用。这样,编译器就能生成更接近机器语言的高效目标代码,提高程序的执行效率。